

Catch Me If You Can: Ausweichende und defensive Techniken bei Phishing


Phishing ist ein vielschichtiger Angriffstyp, der darauf abzielt, Nutzernamen und Passwörter, persönliche Informationen oder auch beides zu sammeln. Diese Angriffe funktionieren jedoch nur so lange, wie das Phishing-Kit selbst verborgen bleibt. Beim Phishing geht es um die Quantität und Zeit ist ein entscheidender Faktor. Je länger ein Phishing-Kit aktiv und unentdeckt bleibt, desto länger kann der Betrug laufen. Und je länger der Betrug läuft, desto mehr Opfer gibt es.
Phishing-Kits verwenden viele ausweichende und defensive Techniken, um Sicherheitskontrollen zu umgehen und eine Erkennung zu vermeiden. So können Kriminelle, die diese Kits einsetzen, verhindern, dass Sicherheitsforscher sie manuell aufspüren und dass Sicherheitsanbieter sie durch maschinelles Lernen für vorausschauende Erkennung oder durch Scans des Internets auf verdächtige Domains erkennen.
In diesem Blogbeitrag untersuchen wir verschiedene ausweichende und defensive Techniken, die auf zahlreichen Websites in einer Vielzahl von Kits entwickelt und verwendet wurden. Einige dieser Techniken sind weit verbreitet, während andere recht anspruchsvoll sein können. Der Unterschied wird in der Regel durch das Kit selbst, seine Verwendung und seine beabsichtigte Funktionalität bestimmt.
Inhaltsbasierte Umgehung
In der Sicherheitsbranche ist das Blockieren von Phishing-Kits durch signaturbasierte Erkennung auf der Phishing-Website (oder „Landingpage“) seit vielen Jahren eine gängige Technik. Entwickler von Phishing-Kits konzentrieren sich jedoch weiterhin auf Techniken, die es signaturbasierten Lösungen erschweren, Phishing-Angriffe effektiv zu erkennen und zu verhindern. Um mit Kit-Auslösungen umgehen zu können, mussten Sicherheitsanbieter einen mehrstufigen Ansatz verwenden. Hier einige aktuelle Beispiele inhaltsbasierter Ausweichtechniken:
Generierung zufälliger Inhalte
In den folgenden Bildern konzentriert sich der Inhalt auf eine betrügerische PayPal-Seite. Dieser Phishing-Angriff sucht hauptsächlich nach PayPal-Nutzernamen und -Passwörtern des Opfers, erstreckt sich aber manchmal auch auf zusätzliche persönliche und finanzielle Informationen.
Abbildung 1 zeigt, wie die Landingpage für das Opfer aussieht, während Abbildung 2 den HTML-Quellcode darstellt, der die Seite erzeugt. In Abbildung 2 wurde das Bild auf der rechten Seite einige Sekunden nach dem Bild auf der linken Seite aufgenommen. Obwohl der HTML-Quellcode auf beiden Seiten völlig unterschiedlich ist, bleibt die Haupt-Landingpage unverändert. Die Generierung zufälliger HTML-Werte zwingt Sicherheitsunternehmen dazu, Signaturen für jede Iteration des geladenen Quellcodes zu verwalten, was fast unmöglich ist.
Wenn das Opfer die Seite zum ersten Mal lädt, ist die Wahrscheinlichkeit hoch, dass für die Seite noch keine Signaturen vorhanden sind. Wenn die Domain einen neutralen oder unbekannten Ruf hat oder – noch schlimmer: – eine kompromittierte Domain mit einem positiven Ruf ist, haben solche Angriffe eine bessere Erfolgsrate als der Durchschnitt.
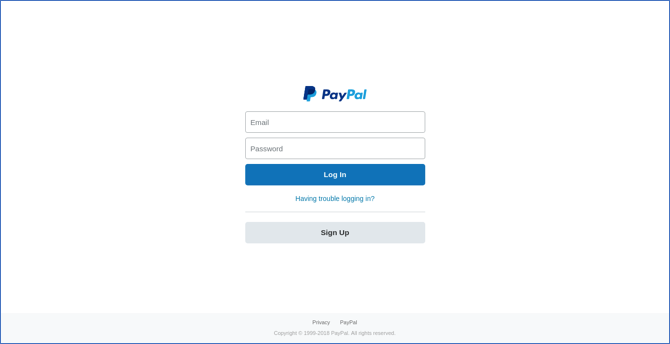
Abbildung 1: Erscheinungsbild der zufällig generierten Phishing-Seite
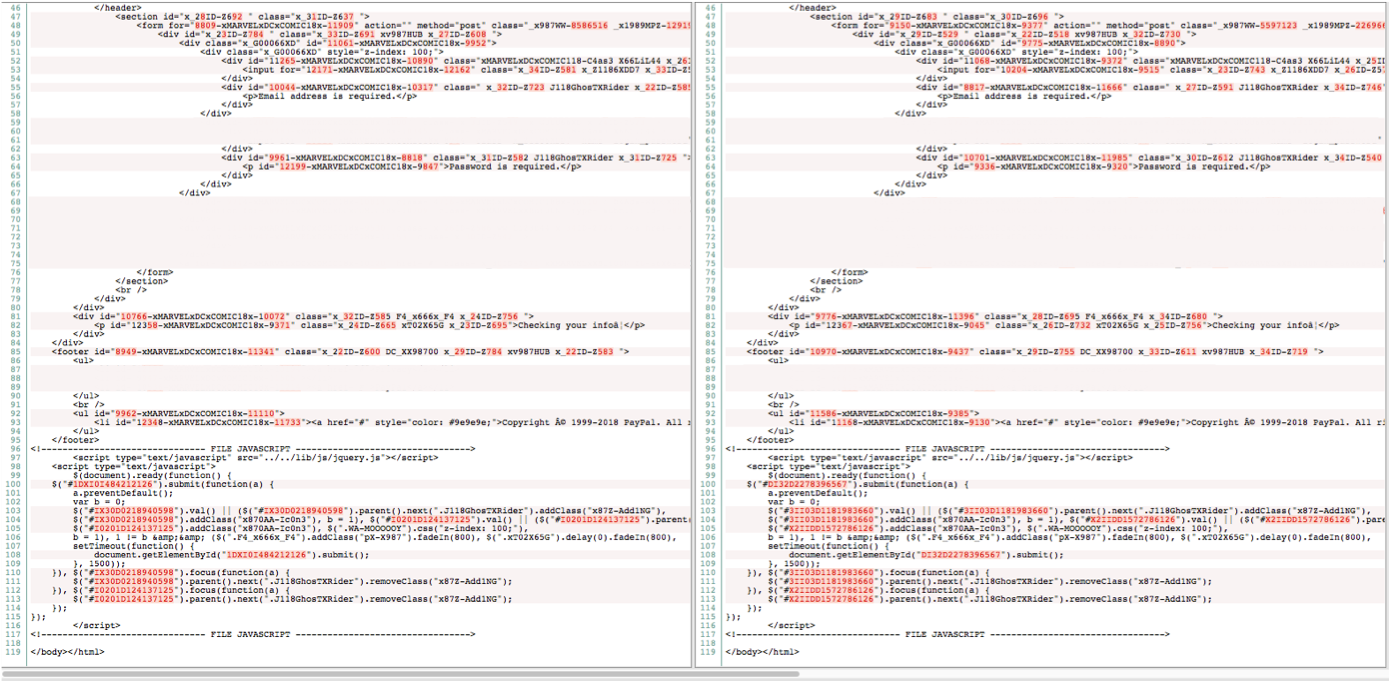
Abbildung 2: Dasselbe Toolkit mit zwei verschiedenen, zufällig generierten HTML-Inhalten
Umgehung der HTML-Codierung
Eine weitere Technik, die häufig eingesetzt wird, ist das Ersetzen von ASCII-Textwerten durch eine Kombination aus ASCII- und HTML-Codierung. Diese Aktion ändert zwar nicht die Art und Weise, wie der Text vom Browser dargestellt wird. Doch solche Kombinationen können Sicherheitslösungen umgehen, die HTML-Code auf der Seite nicht auskommentieren, bevor sie versuchen, Textsignaturen abzugleichen.

Abbildung 3: Title-Wert der Phishing-Website mit einer Kombination aus ASCII- und HTML-Codierung
CSS-Schriftartumgehung
Im Januar 2019 entdeckten Forscher von Proofpoint ein Phishing-Kit, das Webschriftarten zur Textcodierung verwendet. Bei der Untersuchung einer Landingpage entdeckten die Proofpoint-Forscher, dass der Quellcode codiert wurde, was sich jedoch nicht auf die Darstellung der Seite auswirkte. Bei näherer Betrachtung entdeckten die Forscher die für die Decodierung des Quellcodes im Seiten-CSS-Code verantwortlichen Chiffre.
Der CSS-Code hat einen Schriftartenordner aufgerufen, der nicht vorhanden war, und stattdessen zwei base64-codierte WOFF- und WOFF2-Schriftartendateien geladen. Diese Schriftartdateien waren spezifisch entwickelt worden und wiesen Buchstaben in der falschen Reihenfolge auf. Sobald die Seite gerendert wurde, wurden die Schriftarten vom Browser so behandelt, als ob sie in alphabetischer Reihenfolge aufgeführt wären, und der Quellcode wurde durch lesbaren Text ersetzt.
Zufällig generierte URLs
Eine der beliebtesten Möglichkeiten, um Informationen in der Sicherheitsbranche zu teilen, ist die Nutzung von Intelligence-Feeds. Diese Feeds haben viele verschiedene Namen, wie z. B. allgemeine "Listen" oder "Blacklists". So oder so geht es jedoch darum, Informationen an Kollegen zu verteilen, damit sie sich vor zuvor erkannten Bedrohungen schützen können. Wenn es um Phishing geht, gibt es viele Feeds, die Kriminelle gut kennen. Und sie versuchen, um jeden Preis zu vermeiden, in diesen Feeds zu landen.
Viele Phishing-Kits verwenden zufällig generierte Zeichenfolgen, um die URL zur Landingpage jedes Mal zu ändern, wenn auf die Seite zugegriffen wird. Dadurch wird verhindert, dass das Kit direkt blockiert wird, wenn die Blacklists die vollständige URL anstelle einer Domain verwenden. Auch Randomisierung spielt eine Rolle, um die Legitimität des Phishing-Angriffs zu erhöhen, da zufällige Zahlen und Buchstaben das Opfer häufig ablenken und die Seite dadurch offizieller erscheint.
Hier ist ein Beispiel für URLs, die von einem Toolkit generiert wurden, das kürzlich entdeckt wurde:
http://whiteohio{.}ga/secure/santos/4a19123eb1279a47c524bb5610c04eb2fc9f4af3/
http://whiteohio{.}ga/secure/santos/f1236dff5933eac286085df87abcac581b12a7de/
http://whiteohio{.}ga/secure/santos/4fa97942c5059d10bfa08e7cc61cbdba566e52c9/
In diesem Kit wurde jedes Mal, wenn die Website von einem Opfer geladen wurde, ein neuer Ordner und eine neue URL generiert, und das mit sehr wenig Code (siehe Abbildung 4).
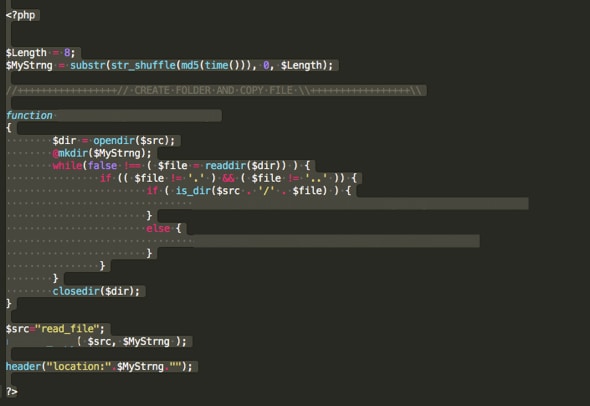
Abbildung 4: Phishing-Code, der eine zufällige URL-Generierung durchführt
Zufällige URL-Parameter
Bei zufällig generierten URLs handelt es sich um zufällig generierte Parameter. Auch hier besteht das Ziel darin, die Legitimität auf der Landingpage zu steigern und eine Erkennung zu vermeiden. Häufig zeigen Anmeldewebsites dem Besucher eine lange, scheinbar zufällige Zeichenfolge aus Buchstaben und Zahlen an. Phishing-Kits verwenden hierfür einfach den Befehl „rand()“ bei jedem Laden der Seite. Unten finden Sie einige Beispiele für zufällig generierte Parameter.
- hxxps://chicagocontracts{.}tk/files/adobeproject/952cdca7aae137e22d7e1eedc7cc81a1/login.php?cmd=login_submit&id=f44b5e2fe6bb7f972a476a386cbf7626f44b5e2fe6bb7f972a476a386cbf7626&session=f44b5e2fe6bb7f972a476a386cbf7626f44b5e2fe6bb7f972a476a386cbf7626
- hxxps://chicagocontracts{.}tk/files/adobeproject/00e0b678a385a1f097044f8953fa0be1/login.php?cmd=login_submit&id=653af29587971f829e7d45ecb72c2860653af29587971f829e7d45ecb72c2860&session=653af29587971f829e7d45ecb72c2860653af29587971f829e7d45ecb72c2860
- hxxps://chicagocontracts{.}tk/files/adobeproject/e130e2f6df8ae2f5b9be01a8edaeaa7a/login.php?cmd=login_submit&id=4ec8655cab2e9c4b0119c2c6ca9c80274ec8655cab2e9c4b0119c2c6ca9c8027&session=4ec8655cab2e9c4b0119c2c6ca9c80274ec8655cab2e9c4b0119c2c6ca9c8027
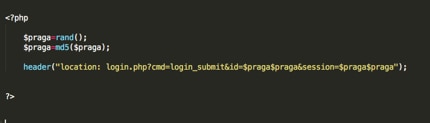
Abbildung 5: Toolkit-Quellcode, der Parameter randomisiert
Zufällig generierte Subdomains
Eine weitere Methode zur Vermeidung von Erkennungszentren ist die Verwendung zufälliger Subdomains. Das funktioniert nur dann, wenn die Root-Domain selbst nicht gefiltert oder sogar vollständig blockiert wird. Bei dieser Methode erstellt der Angreifer eine Liste von Subdomains, die verwendet werden können, je nachdem, wie das Opfer auf die Landingpage zugreift.
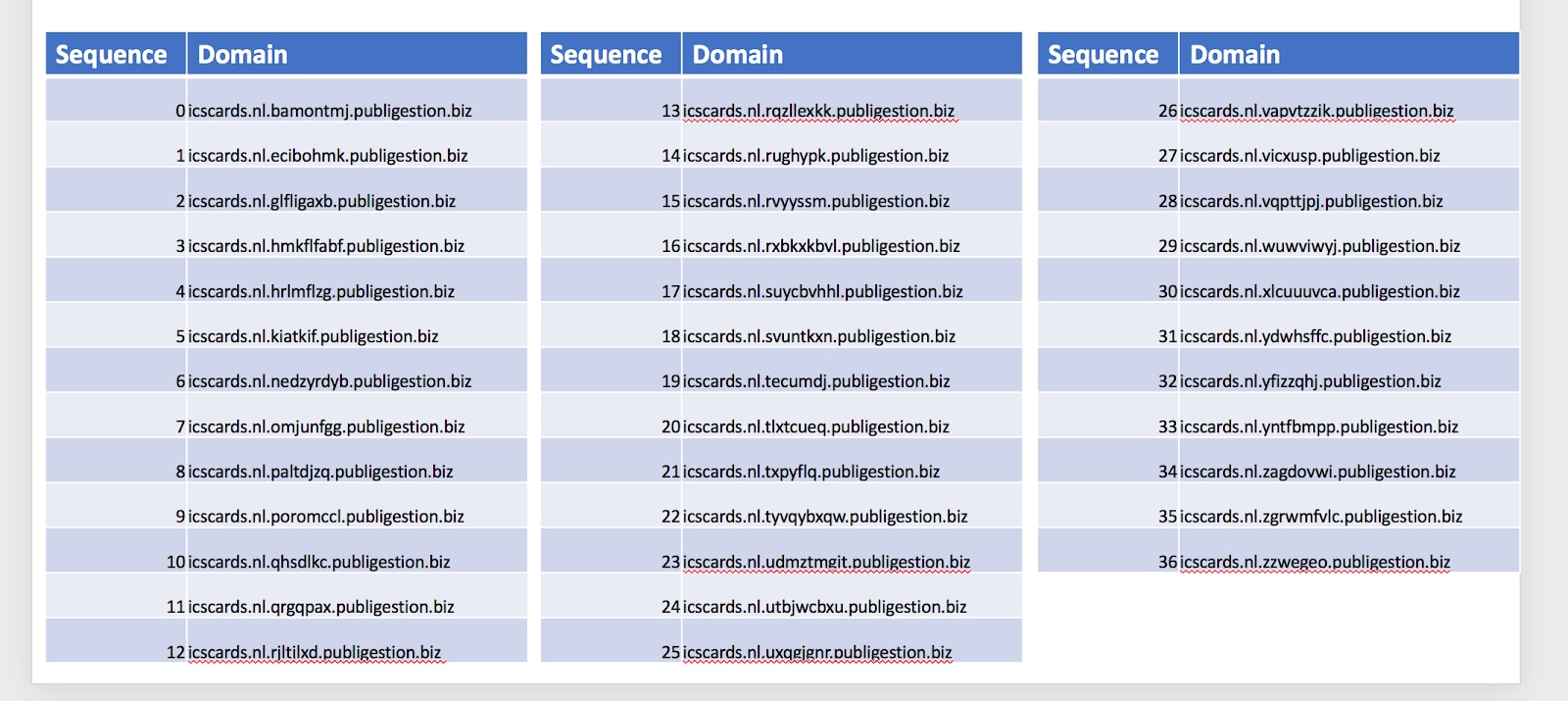
Abbildung 6: Eine Teilliste randomisierter Subdomains, die bei aktuellen Angriffen verwendet werden
Darüber hinaus versuchen Phishing-Kits, die Erkennung zu vermeiden, indem der Zugriff auf ausgewählte Opfer beschränkt wird. Diese Methoden werden in fast allen Kits verwendet, und obwohl sie insgesamt einen mäßigen Erfolg haben, sind sie nicht absolut sicher. Meist werden mit diesen Methoden automatisierte Scans, Blöcke und Forscher blockiert.
Umgekehrter PTR-Ausschluss
Kriminelle versuchen, bekannte Domains zu blockieren, indem sie die IP-Adresse eines Besuchers übernehmen und eine PTR-DNS-Abfrage durchführen. Dabei handelt es sich um eine DNS-Abfrage, die die IP-Adresse der zugehörigen Domain auflöst. Im Beispiel unten sehen Sie, dass der Quellcode versucht, Crawler, bekannte Anbieter (Cyveillance, Phishtank, Sucuri.net) sowie Cloud-Hosting-Anbieter wie Amazon oder Google zu blockieren. Darüber hinaus werden einige Sicherheitsanbieter direkt erwähnt, darunter Message Labs und Trend Micro.

Abbildung 7: PTR-Ausschluss-Quellcode
HTTP-User-Agent-Filterung
Bei dieser Methode (Abbildung 8) filtern Phishing-Kits einen Besucher auf der Landingpage, indem sie den HTTP-User-Agent untersuchen und nach Schlüsselwörtern suchen, die auf Bot-Traffic oder automatische Scans hindeuten.
Bots sind nicht nur für legitime Websites ein Problem, sondern auch für Kriminelle. Viele der von Phishing-Kits gefilterten Bots sind mit Suchmaschinen oder Content Scrapern verknüpft. Die Kits sollen jedoch auch automatisierte Crawler blockieren, die von Forschern und Sicherheitsunternehmen verwendet werden. Die Bot-Blockierungsbemühungen zielen darauf ab, das Phishing-Kit so lange wie möglich zu verstecken, damit nur die Opfer des Kits Zugriff auf seinen Standort haben.
Es gibt auch Ausweichversuche, die auf Internetanbieter- und IP-Besuchen basieren (um zu verhindern, dass dieselbe Adresse das Phishing-Kit mehrfach besucht). Internetanbieter-basierte Filter werden verwendet, um die Opfer des Phishing-Kits an eine bestimmte Region zu binden. Wenn das Kit direkt auf einen Internetanbieter abzielt, richten sie sich nur an die Kunden dieses Service.
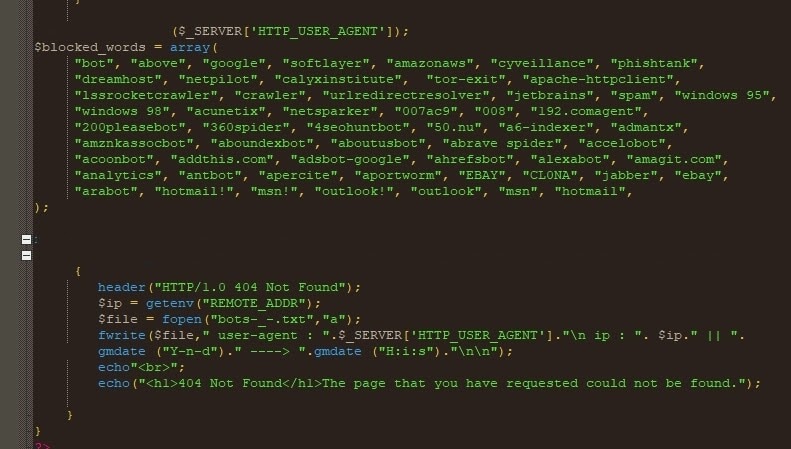
Abbildung 8: Quellcode der User-Agent-Filterung
Nutzerdefinierte .htaccess-Konfiguration
Auf Webservern werden .htaccess-Dateien verwendet, um den Besucher-Traffic zu kontrollieren, wie z. B. Umleitungen zu nutzerdefinierten Fehlerseiten, Indexsteuerung oder das Vermeiden von Hotlinking. Bei Phishing-Kits werden .htaccess-Dateien genutzt, um anhand der IP zu blockieren. Viele der gängigen .htaccess-Dateien, die heute von Phishing-Kits verwendet werden, blockieren ganze IP-Bereiche, die zu Sicherheitsanbietern, Cloudanbietern, bekannten Tor-Knoten, bekannten Forschern, Universitäten oder anderen Stellen gehören.
Fazit
Phishing ist ein Katz-und-Maus-Spiel Sicherheitsforscher und -anbieter entwickeln Erkennungsmethoden und die Entwickler von Phishing-Kits finden ein Mittel, um sie zu umgehen. Wie wir in diesem Beitrag gezeigt haben, verwenden die meisten Kits grundlegende, aber effektive Methoden zur Umgehung. Doch durch Fortschritte der Verteidiger, einschließlich maschinellen Lernens und algorithmischer Erkennung, sind Entwickler von Phishing-Kits etwas stärker im Nachteil.
Der Versuch, Phishing dauerhaft zu stoppen, ist vergebliche Mühe – Menschen werden immer wieder auf unbekannte Links klicken oder ihre Neugier vom nächsten nigerianischen Prinzen wecken lassen. Stattdessen ist es ein Erfolg im Sicherheitsbereich, sich auf die Erkennung zu konzentrieren und die Lebensdauer der Phishing-Kits zu verringern. Da Phishing nicht nur ein E-Mail-Problem ist, müssen Abwehrmaßnahmen außerhalb des Posteingangs bestehen, wo Bewusstsein, proaktive Scans und Kit-basiertes (statt domainbasiertes) Fingerprinting zum Einsatz kommen.
Da die Grenzen zwischen defensiven und offensiven Techniken verschwimmen – jetzt, wo beide Seiten sie nutzen –, müssen Sicherheitsexperten sicherstellen, dass wir bestens mit der Bedrohung vertraut sind und uns mit den Schutzwällen auskennen, die von Cyberkriminellen aufgebaut werden, um uns draußen zu halten.
