

Catch Me If You Can: Evasive and Defensive Techniques in Phishing


Phishing is a multifaceted type of attack, aimed at collecting usernames and passwords, personal information, or sometimes both. Yet, these attacks only work so long as the phishing kit itself remains hidden. Phishing is a numbers game and time is a factor. The longer a phishing kit can remain active and undetected, the longer the scam can run. The longer the scam runs, the number of victims only increases.
Phishing kits use many evasive and defensive techniques to help bypass security controls and stay avoid detection. Doing so helps the criminal deploying these kits avoid security researchers manually hunting them down and security vendors using machine learning for predictive detection or scanning the Internet for suspect domains.
This blog post will examine several evasive and defensive techniques that have been developed and used on thousands of websites across hundreds of kits. Some of these techniques are common, while others can be rather sophisticated. The difference is usually determined by the kit itself,its usage, and intended functionality.
Content-based evasion
In the security industry, blocking phishing kits via signature-based detection on the phishing website (also known as a landing page) has been a common technique for many years. However, phishing kit developers have continued to focus on techniques that make it harder for signature-based solutions to remain effective at detecting and preventing phishing attacks. In order to deal with kit evasions, security vendors have had to use a multi-level approach. Here are some recent examples of content-based evasive techniques.
Random content generation
In the images below, the content in question centers on a fraudulent PayPal page. This phishing attack is mainly looking for PayPal usernames and passwords from the victim, but will sometimes extend to additional personal and financial information.
Figure 1 is what the landing page looks like to the victim, while the Figure 2 is the HTML source code rendering the page itself. In Figure 2, the image on the right was taken seconds after the image on the left. Even though the HTML source code is completely different on both sides, the main landing page remains unchanged. Generating random HTML values forces security companies to maintain signatures for each iteration of the loaded source code, which is nearly impossible.
When the victim loads the page for the first time, the odds are in the criminal's favor that there are no pre-existing signatures on record for the page. If the domain has a neutral or unknown reputation, or worse is a compromised domain with a positive reputation, attacks such as these have a better than average rate of success.

Figure 1: The randomly content generated phishing page appearance
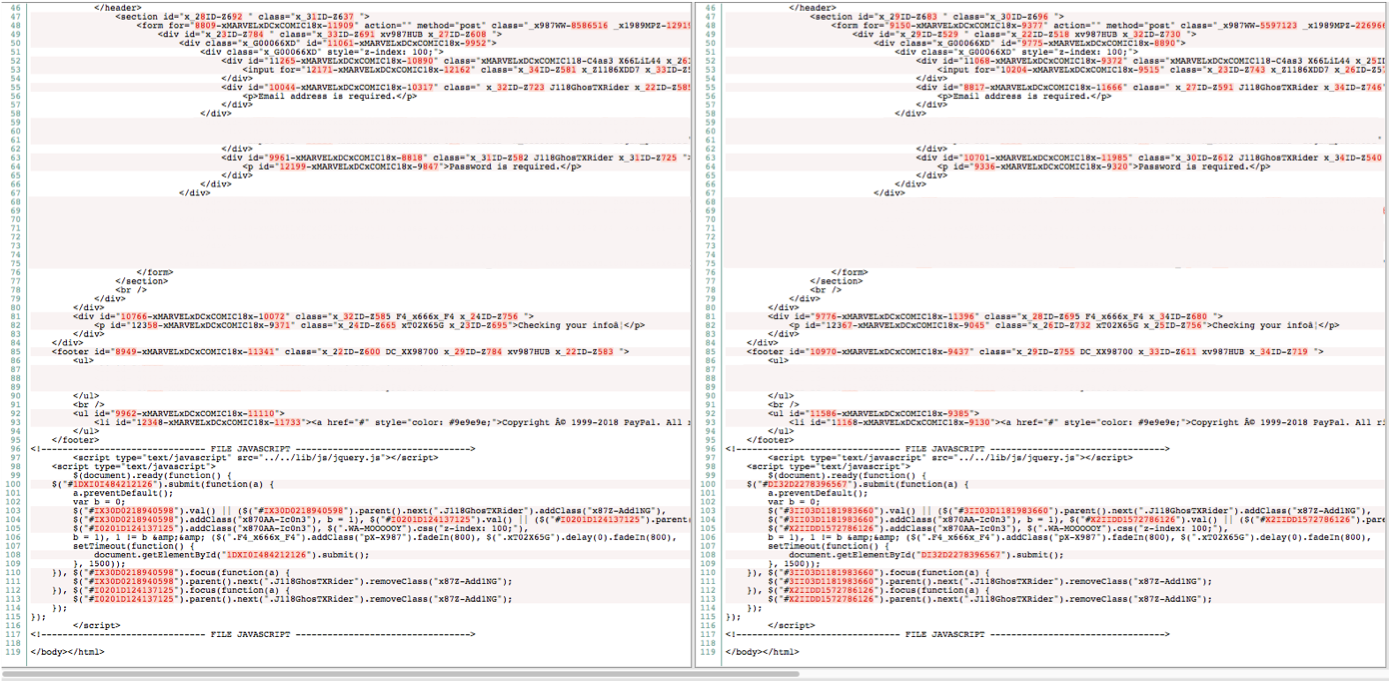
Figure 2: Same toolkit with two different randomly generated HTML content
HTML encoding evasion
Another technique commonly used in the wild is to replace ASCII text values with combination of ASCII and HTML encoding. While such action will not change the way the text will be rendered and presented by browser, such combinations might evade security monitors that are not escaping HTML on the page, before trying to match textual signatures.

Figure 3: Phishing website title value with combination of ASCII and HTML encoding
CSS font evasion
In January 2019, researchers at Proofpoint discovered a phishing kit that used web fonts to encode text. While examining a landing page, Proofpoint researchers discovered that source code was encoded, but that didn't impact the rendering of the page. Looking into the matter further, the researchers discovered the cipher responsible for decoding the source code in the page's CSS code.
The CSS made calls to a fonts folder that didn't exist, and instead loaded two base64-encoded WOFF and WOFF2 font files. Custom made, the font files had letters out of order, and once the page is rendered, the browser treated the fonts as if they were in alphabetical order, replacing the source code with readable text.
Randomly generated URLs
One of the more popular ways to share intelligence in the security industry is via intelligence feeds. These feeds go by many common names, such as the generic "lists" or "black lists", but the point is to distribute information to peers, so that they can defend against previously observed threats. When it comes to phishing, there are plenty of feeds out there, criminals are well aware of them, and they look to avoid them at all costs.
Many phishing kits use randomly-generated strings in order to alter the URL to the landing page, every time the page is accessed. This keeps the kit from being blocked outright when the black lists are using the full URL, instead of just a domain. The randomization also comes into play as a means of adding legitimacy to the phishing attack itself, since random digits and letters often distract the victim and make the page appear more official.
Here is an example of URLs that were generated by toolkit recently observed in the wild:
http://whiteohio{.}ga/secure/santos/4a19123eb1279a47c524bb5610c04eb2fc9f4af3/
http://whiteohio{.}ga/secure/santos/f1236dff5933eac286085df87abcac581b12a7de/
http://whiteohio{.}ga/secure/santos/4fa97942c5059d10bfa08e7cc61cbdba566e52c9/
In this kit, each time the website was loaded by a victim, a new folder and URL was generated, using very little code (see Figure 4).
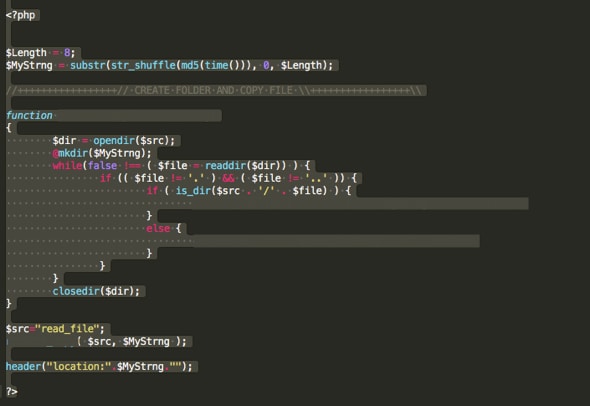
Figure 4: Phishing code performing random URL generation
Random URL parameters
Related to randomly-generated URLs are randomly-generated parameters. Again, the goal here is split between adding legitimacy to the landing page and avoiding detection. Many times, login websites display a long, seemingly random, string of characters and numbers to the visitor, so when phishing kits want to do this, they'll just use the rand() command on each page load. Some examples of randomly generated parameters are below.
- hxxps://chicagocontracts{.}tk/files/adobeproject/952cdca7aae137e22d7e1eedc7cc81a1/login.php?cmd=login_submit&id=f44b5e2fe6bb7f972a476a386cbf7626f44b5e2fe6bb7f972a476a386cbf7626&session=f44b5e2fe6bb7f972a476a386cbf7626f44b5e2fe6bb7f972a476a386cbf7626
- hxxps://chicagocontracts{.}tk/files/adobeproject/00e0b678a385a1f097044f8953fa0be1/login.php?cmd=login_submit&id=653af29587971f829e7d45ecb72c2860653af29587971f829e7d45ecb72c2860&session=653af29587971f829e7d45ecb72c2860653af29587971f829e7d45ecb72c2860
- hxxps://chicagocontracts{.}tk/files/adobeproject/e130e2f6df8ae2f5b9be01a8edaeaa7a/login.php?cmd=login_submit&id=4ec8655cab2e9c4b0119c2c6ca9c80274ec8655cab2e9c4b0119c2c6ca9c8027&session=4ec8655cab2e9c4b0119c2c6ca9c80274ec8655cab2e9c4b0119c2c6ca9c8027
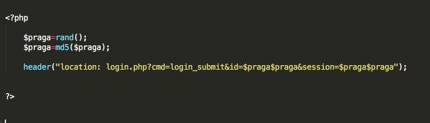
Figure 5: Toolkit source code that randomize parameters
Randomly generated subdomains
Another method of avoiding detection centers is the usage of random subdomains. This really only works if the root domain itself isn't being filtered or blocked outright. In this method, the attacker will create a list of subdomains that can be used depending on how the victim accesses the landing page.
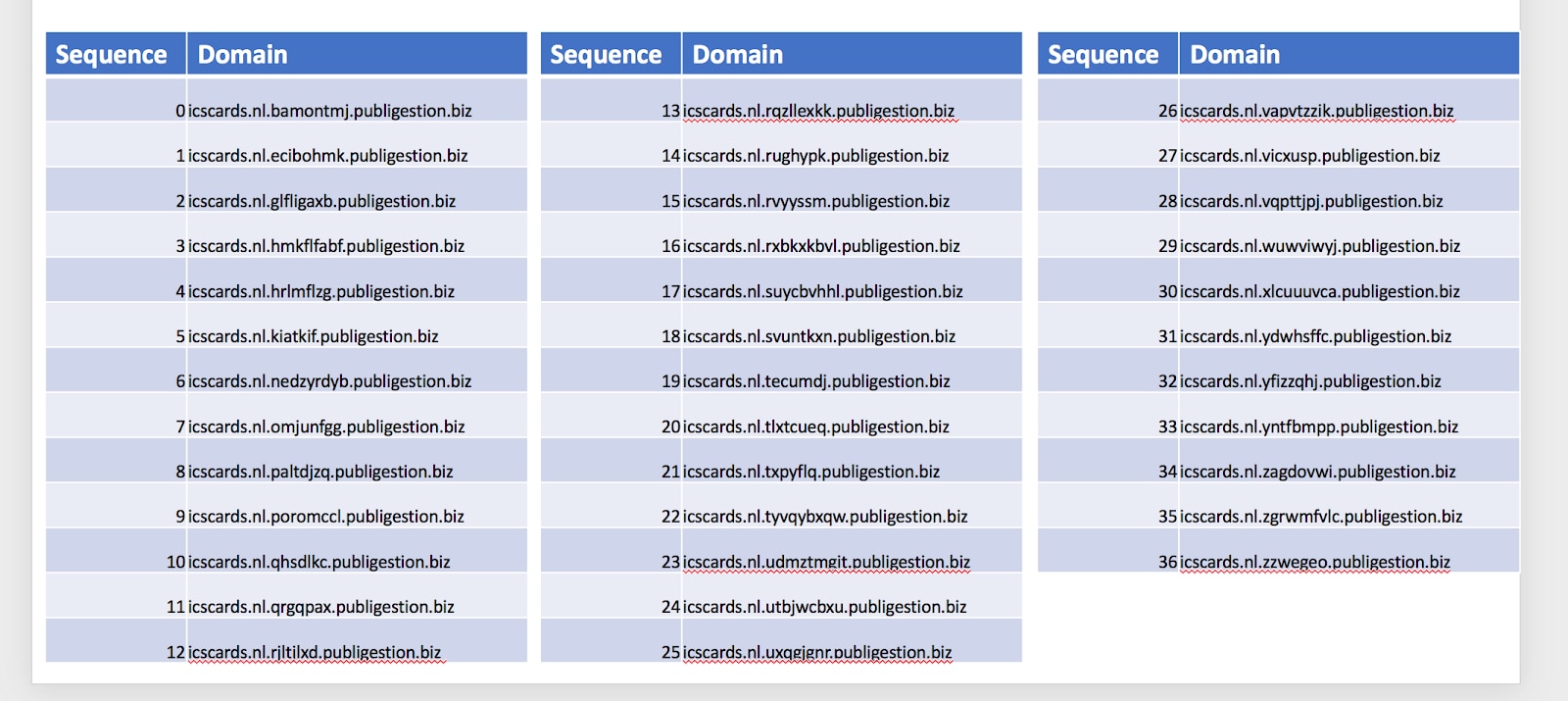
Figure 6: A partial list of randomized sub-domains being used in the wild
Moreover, phishing kits will try to avoid detection is by limiting access to selected victims. These methods are commonly spotted in almost all kits, and while they do have a moderate degree of success overall, they're not foolproof. Mostly these methods are designed to block automated scans, blocks, and researchers.
Reverse PTR exclude
Criminals are looking to block known domains by taking a visitor's IP address and conducting a PTR DNS query - a DNS query that resolves and IP address to its associated domain. In the example below, you can see that the source code is looking to block crawlers, known vendors (cyveillance, phishtank, sucuri.net), and cloud hosting providers such as Amazon or Google. Moreover, there are a few security vendors mentioned directly, including Message Labs and Trend Micro.

Figure 7: PTR exclude source code
HTTP user agent filtering
In this method (Figure 8), phishing kits will filter a visitor to the landing page by examining the HTTP User-Agent and look for keywords that indicate bot traffic or automated scanning.
Bots are a problem for legitimate websites, but clearly bots are an issue for criminals as well. Many of the bots filtered by phishing kits are search engine related, or content scrapers. However, the kits will also look to block automated crawlers used by researchers and security companies. The bot blocking effort is geared towards keeping the phishing kit hidden for as long as possible so that only the kit's victims are able to access its location.
There are also evasions based on ISP and IP visitation (to keep the same address from visiting the phishing kit more than once). ISP-based filters are used to keep the phishing kit's victims locked to a specific region, or if the kit targets an ISP directly, target only that service's customers.

Figure 8: Source code showing User-Agent filtering
Custom .htaccess configuration
On web servers, .htaccess files are used to control visitor traffic, such as redirections to custom error pages, index control, or preventing hotlinking. For phishing kits, .htaccess files are leverages to block by IP. Many of the common .htaccess files used by phishing kits today will block entire IP ranges owned by security vendors, cloud vendors, known Tor nodes, known researchers, universities, and more.
Conclusion
Phishing is a cat and mouse game. Security researchers and vendors develop methods of detection, and phishing kit developers create a means of evading them. As we've shown in this post, most kits use basic, yet effective, methods for evasion. Advancements made by defenders, including machine learning and algorithmic detection, place phishing kit developers at a bit of a disadvantage.
Trying to stop phishing permanently is a fool's errand - people will always click a link or have their curiosity piqued by something. Instead, focusing on detection, and decreasing the lifespan of a given phishing kit's deployment is an obtainable win in the security space. Because phishing isn't just an email problem, defenses have to exist outside the inbox, which is where awareness, proactive scanning, and kit-based instead of domain-based fingerprinting come into play.
As the borders between defensive vs. offensive techniques blur - now that both sides are using them - security practitioners are obligated to make sure we are familiar with the threat inside-out and make sure we know more about the walls being built by threat actors in order to make sure we're not staying outside of the fence.

