

Provate a prendermi: tecniche evasive e difensive nel phishing


Il phishing è un tipo di attacco multisfaccettato, finalizzato a raccogliere nomi utente e password, informazioni personali o, talvolta, entrambi. Tuttavia, questi attacchi funzionano solo finché il kit di phishing rimane nascosto. Il phishing è un gioco di cifre in cui il tempo gioca un ruolo importante. Più un kit di phishing rimane attivo e non rilevato, più a lungo può andare avanti la truffa. Più va avanti la truffa, più aumenta il numero di vittime.
I kit di phishing utilizzano molte tecniche evasive e difensive per eludere i controlli di sicurezza ed evitare il rilevamento. In questo modo, i criminali che li utilizzano possono evitare i ricercatori della sicurezza identificandoli manualmente e i fornitori di servizi di sicurezza utilizzando l'apprendimento automatico per il rilevamento predittivo o la scansione di Internet per i domini sospetti.
In questo blog, esamineremo diverse tecniche evasive e difensive sviluppate e utilizzate su migliaia di siti web e in centinaia di kit. Alcune di queste tecniche sono comuni, mentre altre possono essere piuttosto sofisticate. La differenza è solitamente determinata dal kit stesso, dal suo utilizzo e dalla funzionalità prevista.
Elusione basata sui contenuti
Nel settore della sicurezza, bloccare i kit di phishing tramite il rilevamento basato su firma sul sito web di phishing (noto anche come pagina di destinazione) è una tecnica comune, utilizzata da molti anni. Tuttavia, gli sviluppatori di kit di phishing hanno continuato a incentrare l'attenzione su tecniche che rendono più difficile per le soluzioni basate su firma rimanere efficaci nel rilevare e prevenire gli attacchi di phishing. Per gestire l'elusione dei kit, i fornitori di sistemi di sicurezza hanno dovuto adottare un approccio multilivello. Ecco alcuni esempi recenti di tecniche elusive basate sui contenuti.
Creazione di contenuti casuali
Nelle immagini qui di seguito, il contenuto in questione si incentra su una pagina PayPal fraudolenta. Questo attacco di phishing è principalmente alla ricerca del nome utente e della password PayPal della vittima ma, a volte, si estende a ulteriori informazioni personali e finanziarie.
La figura 1 mostra l'aspetto della pagina di destinazione visualizzata dalla vittima, mentre la figura 2 presenta il codice sorgente HTML che esegue il rendering della pagina stessa. Nella figura 2, l'immagine a destra è stata scattata qualche secondo dopo l'immagine di sinistra. Anche se il codice sorgente HTML è completamente diverso in entrambe le immagini, la pagina di destinazione principale rimane invariata. La creazione di valori HTML casuali obbliga i fornitori di servizi di sicurezza a mantenere le firme per ogni iterazione del codice sorgente caricato, operazione pressoché impossibile.
Quando la vittima carica la pagina per la prima volta, le probabilità che non vi siano firme preesistenti registrate per la pagina sono tutte a favore del criminale. Se il dominio ha una reputazione neutrale o sconosciuta, o peggio ancora è compromesso con una reputazione positiva, attacchi come questi hanno un tasso di successo superiore alla media
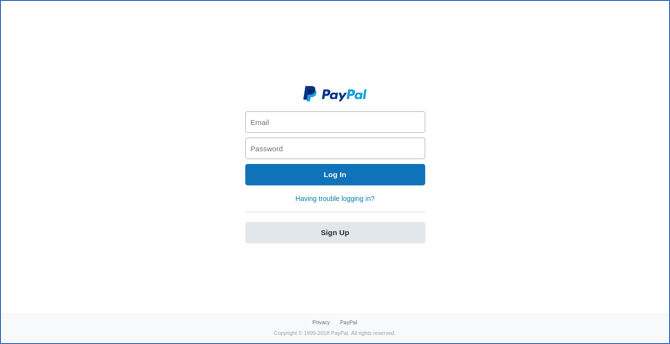
Figura 1: aspetto della pagina di phishing con contenuti generati casualmente
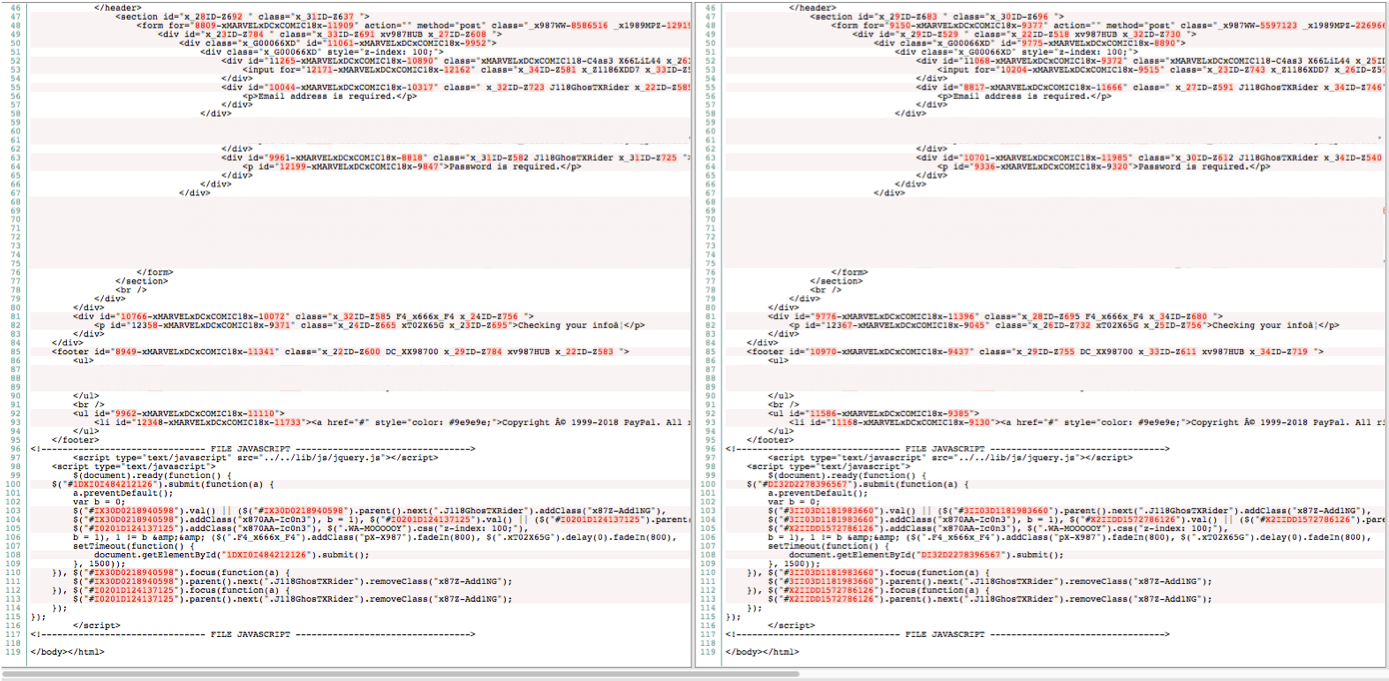
Figura 2: stesso toolkit con due contenuti HTML diversi generati casualmente
Elusione della codifica HTML
Un'altra tecnica comunemente utilizzata è quella di sostituire i valori di testo ASCII con una combinazione di codifica ASCII e HTML. Sebbene tale operazione non modifichi il modo in cui il testo viene sottoposto a rendering e presentato dal browser, queste combinazioni potrebbero eludere i controlli di sicurezza non sfuggiti all'HTML della pagina, prima di trovare una corrispondenza con le firme di testo.

Figura 3: valore del titolo del sito web di phishing con combinazione di codifica ASCII e HTML
Elusione del font CSS
A gennaio 2019, i ricercatori di Proofpoint hanno scoperto un kit di phishing che utilizza caratteri web per codificare il testo. Esaminando una pagina di destinazione, i ricercatori di Proofpoint hanno riscontrato che il codice sorgente era codificato ma che questo non influiva sul rendering della pagina. Analizzando ulteriormente la questione, i ricercatori hanno identificato l'algoritmo di crittografia responsabile della decodifica del codice sorgente nel codice CSS della pagina.
Il CSS effettuava chiamate a una cartella di font inesistente mentre invece caricava due file di font WOFF e WOFF2 con codifica base64. I file di font personalizzati presentavano lettere fuori sequenza e, una volta eseguito il rendering della pagina, il browser trattava i font come se fossero in ordine alfabetico, sostituendo il codice sorgente con testo leggibile.
URL generati casualmente
Uno dei modi più diffusi per condividere l'intelligence nel settore della sicurezza è attraverso i feed di intelligence. Questi feed sono definiti con diversi nomi comuni, come le generiche "liste" o "blacklist", ma il loro scopo è distribuire le informazioni ai peer, in modo che possano difendersi dalle minacce osservate in precedenza. Nel phishing, i feed disponibili sono numerosi e i criminali ne sono ben consapevoli e cercano di evitarli a tutti i costi.
Molti kit di phishing utilizzano stringhe generate casualmente per modificare l'URL della pagina di destinazione, ogni volta che si accede alla pagina. Questo impedisce al kit di essere bloccato completamente quando le blacklist utilizzano l'URL completo, anziché solo un dominio. La randomizzazione entra in gioco anche come mezzo per aggiungere legittimità all'attacco di phishing stesso, poiché cifre e lettere casuali spesso distraggono la vittima e rendono la pagina visualizzata più ufficiale.
Di seguito, è riportato un esempio di URL generati da toolkit osservati di recente:
http://whiteohio{.}ga/secure/santos/4a19123eb1279a47c524bb5610c04eb2fc9f4af3/
http://whiteohio{.}ga/secure/santos/f1236dff5933eac286085df87abcac581b12a7de/
http://whiteohio{.}ga/secure/santos/4fa97942c5059d10bfa08e7cc61cbdba566e52c9/
In questo kit, ogni volta che il sito web viene caricato da una vittima, vengono generati una nuova cartella e un nuovo URL, utilizzando pochissimo codice (vedere la Figura 4).
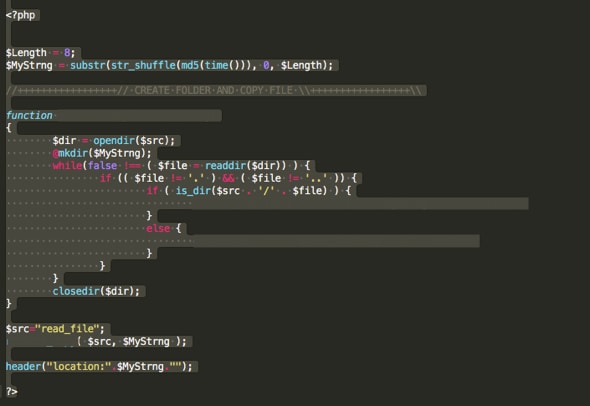
Figura 4: codice di phishing che genera URL casuali
Parametri URL casuali
In presenza di URL generati casualmente esistono parametri generati casualmente. Ancora una volta, l'obiettivo è duplice: aggiungere legittimità alla pagina di destinazione ed evitare il rilevamento. Molte volte, le pagine web di accesso mostrano al visitatore una lunga stringa di caratteri e numeri, apparentemente casuale, in modo che quando i kit di phishing vogliono, utilizzano semplicemente il comando rand() ad ogni caricamento di pagina. Di seguito, sono riportati alcuni esempi di parametri generati casualmente.
- hxxps://chicagocontracts{.}tk/files/adobeproject/952cdca7aae137e22d7e1eedc7cc81a1/login.php?cmd=login_submit&id=f44b5e2fe6bb7f972a476a386cbf7626f44b5e2fe6bb7f972a476a386cbf7626&session=f44b5e2fe6bb7f972a476a386cbf7626f44b5e2fe6bb7f972a476a386cbf7626
- hxxps://chicagocontracts{.}tk/files/adobeproject/00e0b678a385a1f097044f8953fa0be1/login.php?cmd=login_submit&id=653af29587971f829e7d45ecb72c2860653af29587971f829e7d45ecb72c2860&session=653af29587971f829e7d45ecb72c2860653af29587971f829e7d45ecb72c2860
- hxxps://chicagocontracts{.}tk/files/adobeproject/e130e2f6df8ae2f5b9be01a8edaeaa7a/login.php?cmd=login_submit&id=4ec8655cab2e9c4b0119c2c6ca9c80274ec8655cab2e9c4b0119c2c6ca9c8027&session=4ec8655cab2e9c4b0119c2c6ca9c80274ec8655cab2e9c4b0119c2c6ca9c8027
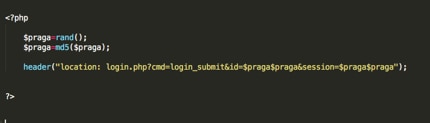
Figura 5: codice sorgente del toolkit che randomizza i parametri
Sottodomini generati casualmente
Un altro metodo per evitare i centri di rilevamento è l'utilizzo di sottodomini casuali. Questo metodo funziona solo se il dominio radice non è filtrato o bloccato completamente. Con questo metodo, il criminale crea un elenco di sottodomini da utilizzare in base a come la vittima accede alla pagina di destinazione.
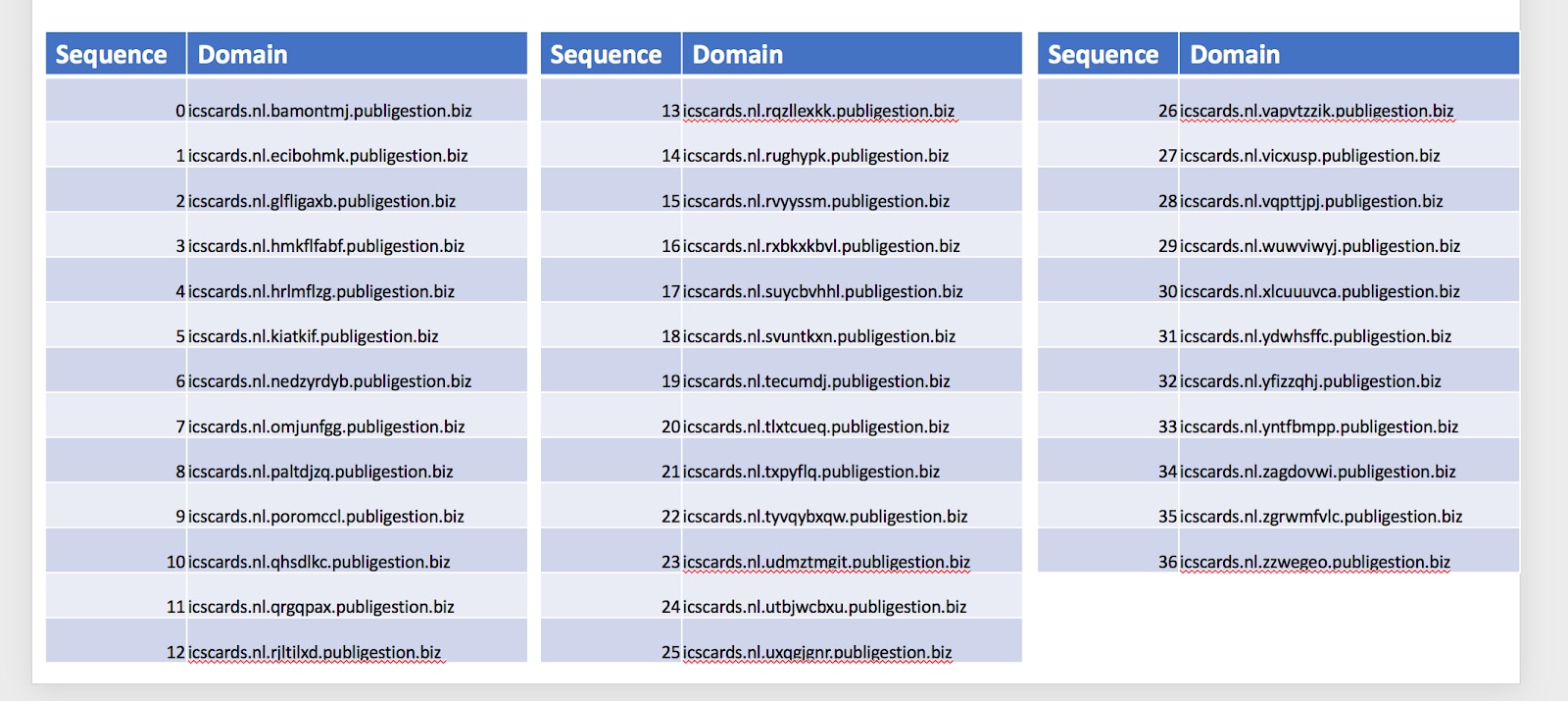
Figura 6: un elenco parziale dei sottodomini randomizzati utilizzati nella realtà
Inoltre, i kit di phishing tenteranno di evitare il rilevamento limitando l'accesso alle vittime prescelte. Questi metodi sono comunemente osservati in quasi tutti i kit e, sebbene abbiano generalmente un moderato grado di successo, non sono infallibili. Questi metodi sono principalmente progettati per bloccare le scansioni automatizzate, i blocchi e i ricercatori.
Esclusione del record PTR inverso
I criminali cercano di bloccare i domini noti prendendo l'indirizzo IP di un visitatore ed eseguendo una query DNS PTR, una query DNS che viene risolta in un indirizzo IP di un dominio associato. Nell'esempio riportato di seguito, vediamo che il codice sorgente sta cercando di bloccare i crawler, i fornitori noti (cyveillance, phishtank, sucuri.net) e i provider di hosting su cloud come Amazon o Google. Inoltre, sono menzionati direttamente alcuni fornitori di servizi di sicurezza, tra cui Message Labs e Trend Micro.

Figura 7: codice sorgente per l'esclusione di record PTR (Pointer Record Type)
Filtraggio di user agent HTTP
Con questo metodo (Figura 8), i kit di phishing filtrano un visitatore nella pagina di destinazione esaminando l'User-Agent Http e ricercano le parole chiave che indicano il traffico bot o la scansione automatizzata.
I bot sono un problema per i siti web legittimi, ma sono chiaramente un problema anche per i criminali. Molti dei bot filtrati dai kit di phishing sono correlati ai motori di ricerca o agli scrapper di contenuti. Tuttavia, i kit tentano anche di bloccare i crawler automatizzati, utilizzati dai ricercatori e dai fornitori di servizi di sicurezza. Il tentativo di bloccare i bot è finalizzato a mantenere nascosto il kit di phishing il più a lungo possibile, in modo che solo le vittime del kit possano accedere alla sua posizione.
Esistono anche elusioni basate su visite ISP e IP (per evitare che lo stesso indirizzo visiti il kit di phishing più di una volta). I filtri basati su ISP vengono utilizzati per mantenere le vittime del kit di phishing bloccate in una regione specifica o, se il kit prende di mira direttamente un ISP, lo fa solo per i clienti del servizio.
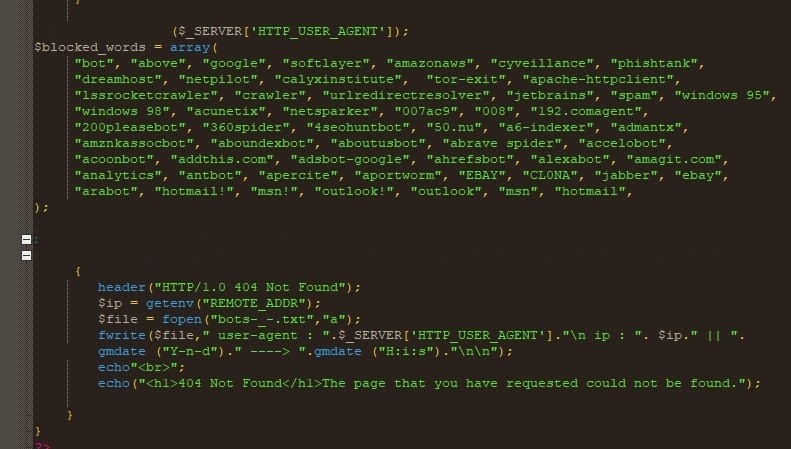
Figura 8: codice sorgente che mostra il filtraggio User-Agent
Configurazione personalizzata .htaccess
Nei server web, i file .htaccess vengono utilizzati per controllare il traffico dei visitatori, ad esempio i reindirizzamenti a pagine di errore personalizzate, l'index controller o la prevenzione degli hotlink. Nei kit di phishing, i file .htaccess vengono utilizzati per il blocco tramite IP. Molti dei file .htaccess più comuni e utilizzati oggi dai kit di phishing bloccano interi intervalli IP di proprietà dei fornitori di servizi di sicurezza, di cloud, nodi Tor noti, ricercatori noti, università e altro ancora.
Conclusione
Il phishing è un sistema poco funzionale. Mentre i ricercatori e i fornitori di sistemi di sicurezza sviluppano metodi di rilevamento, gli sviluppatori di kit di phishing creano il modo per eluderli. Come abbiamo mostrato in questa pubblicazione, per eludere i sistemi, la maggior parte dei kit utilizza metodi di base ma efficaci. I progressi compiuti dai sistemi di difesa, tra cui l'apprendimento automatico e il rilevamento algoritmico, pongono gli sviluppatori di kit di phishing in una posizione di leggero svantaggio.
Cercare di fermare il phishing in modo permanente è un'idea da folli: le persone faranno sempre clic su un link e la loro curiosità sarà sempre stimolata da qualcosa. Invece, concentrarsi sul rilevamento e ridurre la durata di distribuzione di un determinato kit di phishing è un traguardo raggiungibile nel campo della sicurezza. Poiché il phishing non è solo una questione che riguarda le e-mail, i sistemi di difesa devono essere presenti all'esterno della casella di posta, ovvero dove entrano in gioco la consapevolezza, la scansione proattiva e il fingerprinting basato su kit anziché su dominio.
Il confine tra tecniche difensive e offensive è ormai offuscato e, ora sono utilizzate da entrambe le parti, gli esperti della sicurezza sono obbligati a familiarizzare con la minaccia sia nell'ambiente interno che all'esterno e a conoscere più approfonditamente i muri costruiti dai criminali, per non essere tagliati fuori.
