
Exploración de un dispositivo VPN: la experiencia de un investigador


- Ben Barnea, investigador de Akamai, encontró varias vulnerabilidades en FortiOS de Fortinet.
- Un atacante no autenticado puede desencadenar vulnerabilidades que pueden provocar ataques de denegación de servicio (DoS) y de ejecución remota de código (RCE).
- La vulnerabilidad DoS es fácil de explotar y hace que el dispositivo Fortigate deje de funcionar.
- Suponemos que la vulnerabilidad de RCE es difícil de explotar.
- Se informó a Fortinet de estas vulnerabilidades de manera responsable, y se les asignaron las CVE-2024-46666 y CVE-2024-46668.
- Fortinet solucionó las vulnerabilidades descubiertas por Barnea el 14 de enero de 2025, y los dispositivos con versiones de FortiOS actualizadas ya están protegidos contra ellas.
Introducción
En los últimos años, las soluciones VPN han sufrido muchas vulnerabilidades críticas que han sido explotadas libremente por agentes maliciosos. Algunas de estas vulnerabilidades son increíblemente fáciles de explotar y tienen un impacto devastador: una RCE en un dispositivo VPN expuesto a Internet. Una vez dentro de la red, los atacantes pueden moverse lateralmente para obtener acceso a datos confidenciales, propiedad intelectual y otros activos de gran valor.
Además de la explotación inicial de las vulnerabilidades de las VPN, el investigador de Akamai Ori David también ha documentado técnicas posteriores a la explotación y ha demostrado que un servidor VPN comprometido podría permitir a los atacantes obtener fácilmente el control sobre otros activos críticos de la red.
Lamentablemente, los investigadores sobre seguridad que desean estudiar los dispositivos VPN tienen dificultades para iniciar su investigación, ya que los firmwares no siempre están disponibles fácilmente y están protegidos con mecanismos de cifrado implementados por los proveedores. Sin embargo, dado que los dispositivos VPN son el principal objetivo de explotación, superar estas protecciones puede merecer la pena para los atacantes.
En esta entrada de blog, exploraremos el proceso de análisis de la solución VPN de Fortinet. Pasaremos por los procesos de obtención del firmware, descifrado, configuración de un depurador y, finalmente, búsqueda de vulnerabilidades.
Algunas de las investigaciones presentadas en esta publicación no son novedosas: FortiOS ha sido objeto de investigaciones importantes por parte de Optistream, Bishop Fox, Assetnote, Lexfo y más. Hemos actualizado su investigación inicial con la versión más reciente de FortiOS, ya que Fortinet cambia a menudo los métodos de cifrado y descifrado, lo que dificulta el análisis del dispositivo.
Obtención de una imagen de firmware
Tradicionalmente, las VPN se vendían como un dispositivo físico independiente, lo que podía complicar su adquisición y extracción del firmware. Sin embargo, hoy en día es mucho más común encontrar dispositivos VPN como un dispositivo virtual que se puede implementar en una máquina virtual (VM).
Afortunadamente para nosotros, Fortinet ofrece una máquina virtual de prueba que se puede descargar de su sitio web después de registrarse (Figura 1). La máquina virtual está limitada: solo se permite una CPU y está limitada a 2 GB de RAM.
 Fig. 1: Versiones de prueba de VM descargables
Fig. 1: Versiones de prueba de VM descargables
Creación de un entorno de depuración
La VM proporcionada contiene dos puntos de interés: (1) una imagen de arranque, junto con una imagen del kernel (llamada flatkc) y (2) un sistema de archivos cifrado rootfs que contiene la mayoría de los archivos interesantes. Dentro del sistema de archivos, una vez descifrado, podemos encontrar un binario llamado init dentro del directorio /bin/.
La mayoría de los binarios de la VM se compilaron estáticamente en este único binario. Dos binarios interesantes que están presentes en /bin/init son SSLVPND y el servidor web de gestión. Volveremos a esos binarios más adelante en esta publicación.
Queremos crear un entorno en el que tengamos un shell completo, y no la interfaz de línea de comandos (CLI) restringida que recibimos de Fortinet. Además, queríamos tener un binario gdb que nos permitiera depurar los binarios fácilmente.
Para crear dicho entorno, hacemos lo siguiente:
- Descomprimir el CPIO (un formato de archivo) comprimido con GZIP
- Utilizar el script de Bishop Fox para descifrar los rootfs
- Descomprimir el archivo bin.tar.xz
- Aplicar parche a la comprobación de integridad de /bin/init
- Convertir el flatkc a ELF mediante vmlinux-to-elf
- Buscar la dirección de fgt_verify_initrd en IDA, de modo que podamos aplicar parches en tiempo de ejecución para desactivar más comprobaciones de integridad
- Colocar un BusyBox y gdb compilado estáticamente dentro de /bin/
- Compilar un stub que cree un servidor telnet; anular /bin/smartctl con este stub
- Comprimir la carpeta /bin/
- Volver a empaquetar los rootfs y cifrarlos
- Añadir relleno al final de los rootfs cifrados
- Sustituir los rootfs en el VMDK mediante una VM Ubuntu auxiliar (que monta el VMDK)
Los pasos que se ilustran en la figura 2 crean una VM editada con capacidades de depuración. Dado que la comprobación de integridad de los rootfs falla, el kernel detendrá la ejecución. Por lo tanto, o bien necesitamos aplicar parches al kernel (flatkc) y, a continuación, aplicar parches al código de verificación de integridad del cargador de arranque, o bien recurrir a aplicar parches de forma dinámica a la comprobación de integridad del kernel. Decidimos seguir con este último enfoque.
 Fig. 2: Aplicación de parches a FortiGate para un entorno de investigación
Fig. 2: Aplicación de parches a FortiGate para un entorno de investigación
Intentamos utilizar la función de depuración de VM de VMware editando el archivo VMDK. Esto debería configurar un depurador GDB que estará disponible una vez que se ejecute el equipo. Lamentablemente, hemos encontrado un problema con la implementación de esta función al ejecutarla en un equipo con Hyper-V activado. En cuanto se encuentra un punto de interrupción, la máquina se bloquea. Esto parece deberse a una implementación incompleta de la función de depuración del kernel cuando se ejecuta en un equipo Hyper-V.
Intento de creación de una VM en ejecución mediante QEMU
Después de varios intentos fallidos de ejecutar la depuración del kernel con VMware, decidimos intentar crear una VM en ejecución mediante QEMU. Creamos la VM modificada estáticamente, utilizando pasos similares, excepto por la necesidad de conversión entre los formatos de archivo qcow2 y VMDK.
Para depurar el kernel cuando se usa QEMU, podemos proporcionar el indicador -s a qemu-system. Finalmente ejecutamos la VM, adjuntamos GDB y agregamos un punto de interrupción para sobrescribir la comprobación de integridad, y la CLI nos da la bienvenida. (Figura 3).
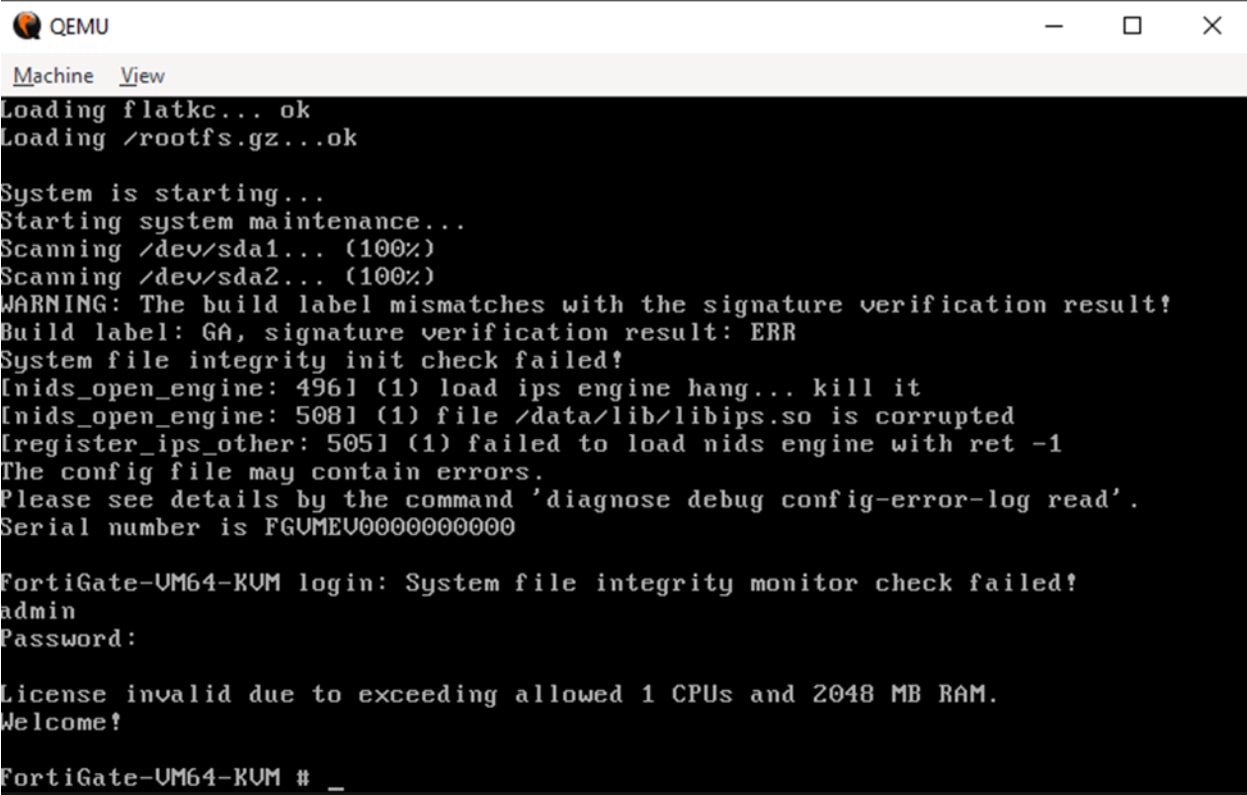 Fig. 3: VM en funcionamiento con CLI
Fig. 3: VM en funcionamiento con CLI
Después de configurar los ajustes de red y recibir una IP válida del servidor DHCP, podemos ejecutar el binario smartctl modificado que imprime el contenido actual del directorio, el comando Linux ID y abre una sesión telnet de BusyBox. (Figura 4).
 Fig. 4: Activación de la puerta trasera
Fig. 4: Activación de la puerta trasera
Y finalmente, la figura 5 muestra que nos conectamos al servidor telnet recién creado.
 Fig. 5: Conexión al shell
Fig. 5: Conexión al shell
¿Final? No.
Como puede ver en la figura 6, no tenemos una licencia válida, lo que nos impide interactuar con el panel administrativo.
 Fig. 6: Error de licencia
Fig. 6: Error de licencia
Un problema ineludible (¿?)
Al principio, pensamos que la licencia no era válida porque superamos el límite de 1 CPU y 2048 MB de RAM. Así que teníamos dos opciones: Podíamos aceptar este límite y tener una VM muy lenta, o bien eludirlo.
Después de hacer algunas maniobras de reversión, encontramos la función upd_vm_check_license que se llama periódicamente en un daemon (Figura 7). La función comprueba que la RAM de la máquina y el número de CPU no superan los límites.
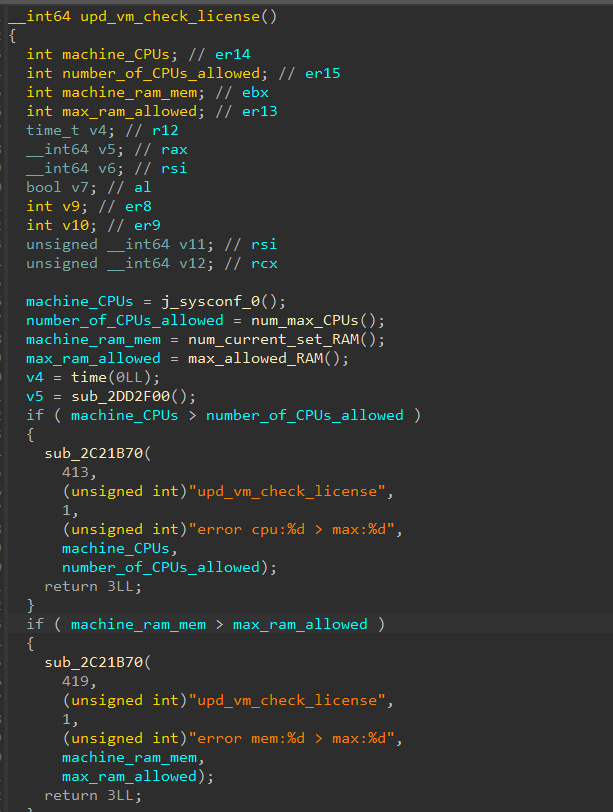 Fig. 7: Código descompilado responsable de las restricciones de la VM
Fig. 7: Código descompilado responsable de las restricciones de la VM
Después de eludir las restricciones modificando el valor devuelto de num_max_CPUs() y max_allowed_RAM() dinámicamente, ahora tenemos una VM potente y sin restricciones y recibimos menos errores cuando arrancamos la máquina, pero seguimos recibiendo un error de licencia no válida.
Después de pasar demasiado tiempo invirtiendo la función de validación de licencias y sopesando las elecciones de nuestras vidas que nos llevaron a esto, finalmente descubrimos que la licencia utiliza la clave de serie de la máquina, que se construye con SMBIOS UUID. Dado que no proporcionamos una a QEMU, utilizó una NULA, y por eso el número de serie creado era "FGVMEV0000000000". Después de proporcionar un UUID de SMBIOS a QEMU mediante el siguiente indicador:
-smbios type=1,manufacturer=t1manufacturer,product=t1product,version=t1version,serial=t1serial,
uuid=25359cc8-5fe7-4d50-ab82-9fd15ecaf221,sku=t1sku,family=t1family
Finalmente arrancamos la máquina y recibimos una licencia válida.
Nueva versión. Nuevo cifrado. ¿POR QUÉ?
En este punto, tenemos un entorno de depuración en funcionamiento. Comenzamos a investigar el servidor web de gestión y encontramos algunas vulnerabilidades que describiremos más adelante en esta publicación. Al detectar estas vulnerabilidades, observamos que Fortinet publicó FortiOS versión 7.4.4.
Queríamos ver si las vulnerabilidades aún existían en la nueva versión, pero después de no lograr descifrar los rootfs de la VM actualizada, encontramos un cifrado completamente diferente que es aún más difícil de descifrar. Esta vez, decidimos hacer un esfuerzo para descifrar los nuevos rootfs, pero no para crear un entorno de depuración, ya que el objetivo principal en este momento era verificar que las vulnerabilidades aún existían.
Por lo tanto, primero vamos a describir la forma antigua de descifrar los rootfs (antes de la versión 7.4.4):
1. El kernel verifica la integridad de los rootfs y, si es válida, continúa con el paso siguiente.
2. El kernel llama a fgt_verifier_key_iv, que calcula una clave y vector de inicialización (IV) de la siguiente manera:
a. Clave: sha256() de datos globales
b. IV: sha256() de otra parte de los mismos datos globales; entonces, trunca el resultado a 16 bytes
3. Descifra los rootfs mediante Chacha20 con la clave e IV anteriores.
Ahora, echemos un vistazo al nuevo algoritmo (Figura 8):
1. El código de descifrado calcula la clave y el IV mediante sha256() del buffer de datos globales, como en el algoritmo anterior.
2. ChaCha descifra un bloque de memoria utilizando la clave y el IV; este bloque de memoria es un ASN1 que representa una clave privada RSA.
3. Toma d,n de la clave privada RSA y descifra un bloque de datos presente en los últimos 256 bytes del firmware cifrado mediante la fórmula conocida M = Cd mod N.
4. Del bloque de datos, toma:
16 bytes que son nonce + contador
32 bytes de clave
5. Realiza el descifrado AES en modo CTR, con la clave y el nonce+contador; el código utiliza una adición CTR personalizada.
6. Esta adición es el resultado de crear mediante texto sin formato XOR los fragmentos de (nonce + contador).
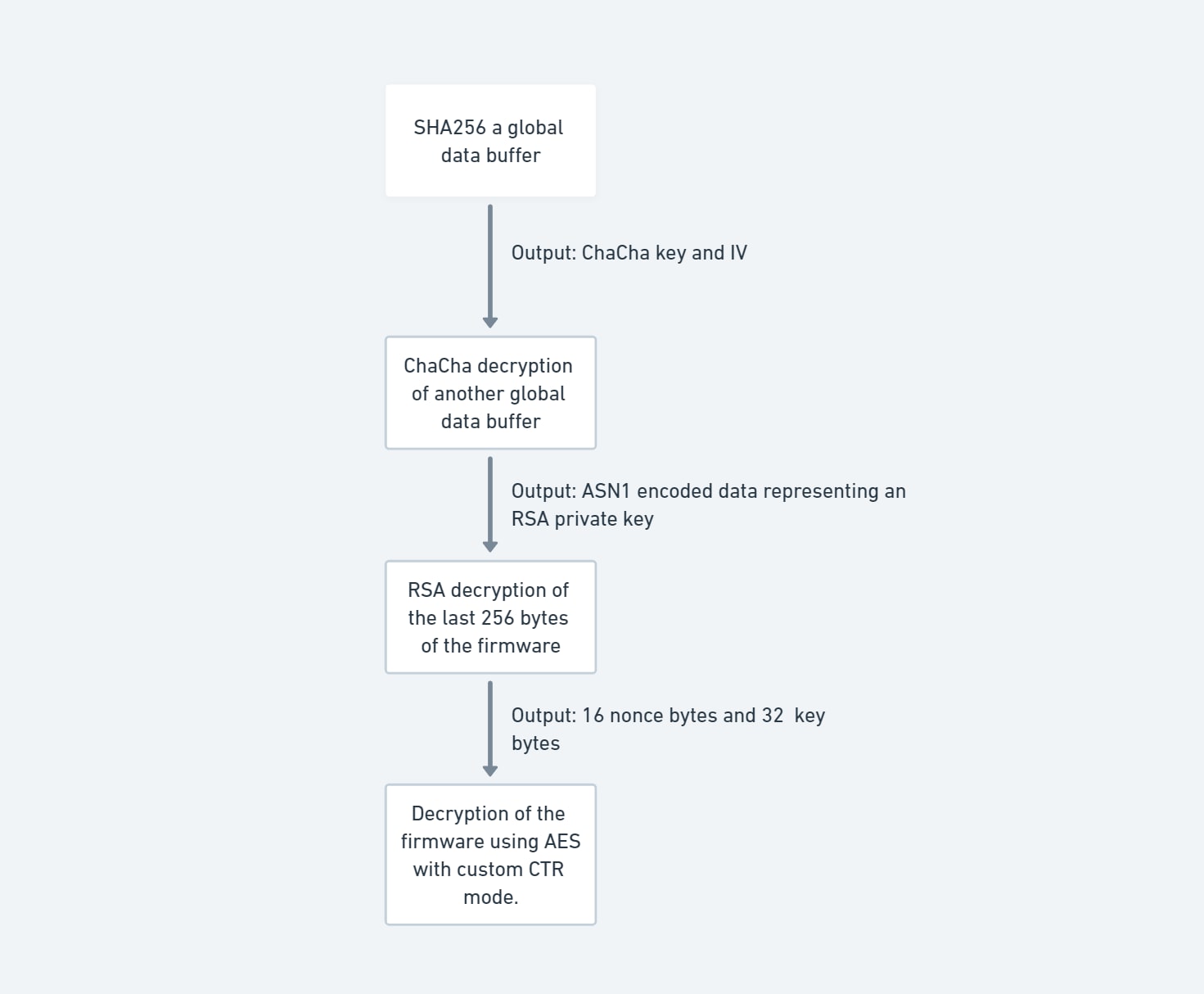 Fig. 8: Diagrama de flujo de descifrado del firmware
Fig. 8: Diagrama de flujo de descifrado del firmware
Para aumentar la complejidad de este algoritmo de descifrado de varias fases, el nuevo flatkc ya no tiene símbolos, lo que dificulta que las herramientas de escritura descifren automáticamente el firmware; por ejemplo, encontrando los datos globales que se utilizan para el descifrado ChaCha y la clave privada RSA cifrada.
Después de realizar todos los pasos descritos anteriormente, podemos ver los rootfs (Figura 9).
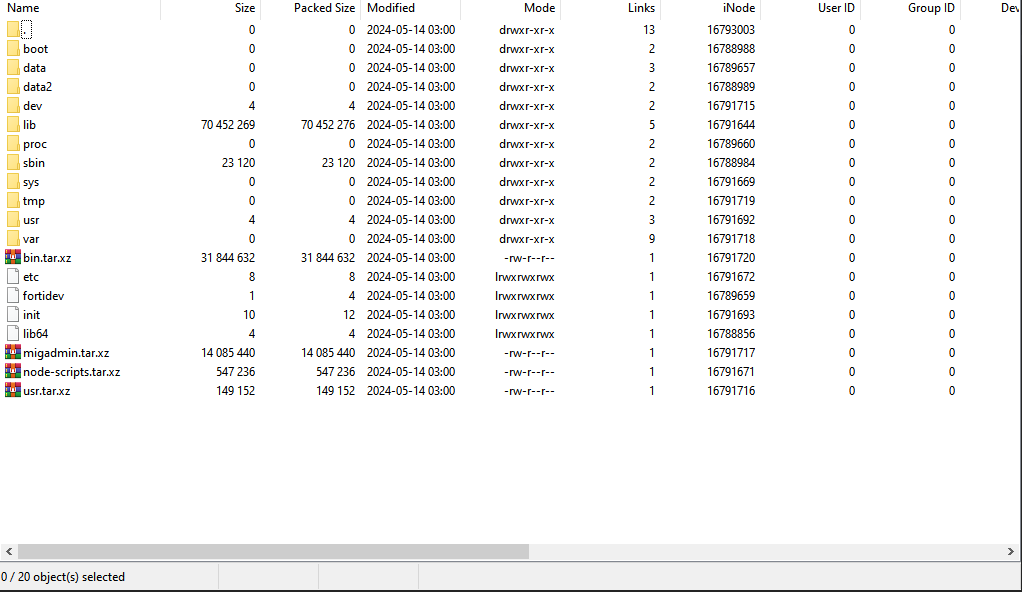 Fig. 9: Descifrado de los rootfs
Fig. 9: Descifrado de los rootfs
Esta vez no hemos creado un entorno modificado. Para ello, es necesario crear un archivo rootfs que se debe descifrar de la forma correcta como se ha descrito anteriormente. Otra opción es definir dinámicamente puntos de interrupción y sobrescribir la memoria con un rootfs descifrado.
Inversión del servidor web de administración
Por último, podemos invertir el servidor web de administración. Se basa en Apache y, en general, no debería ser accesible a Internet (a diferencia de la interfaz sslvpn, que es accesible a Internet).
Cuando abrimos la configuración httpd, podemos observar algunas directivas de ubicación que dirigen las URL a sus controladores (Figura 10).
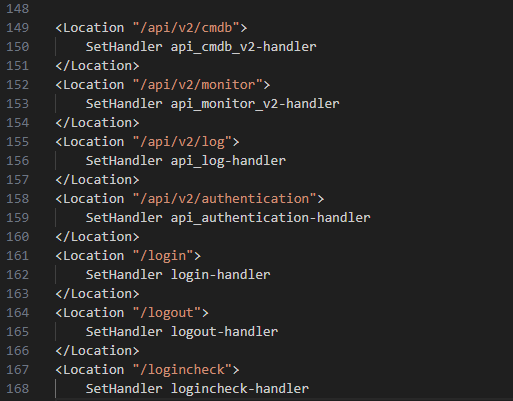 Fig. 10: Fragmento del archivo de configuración httpd
Fig. 10: Fragmento del archivo de configuración httpd
A continuación, podemos buscar en una de las cadenas del controlador en el binario para encontrar la tabla del controlador (Figura 11).
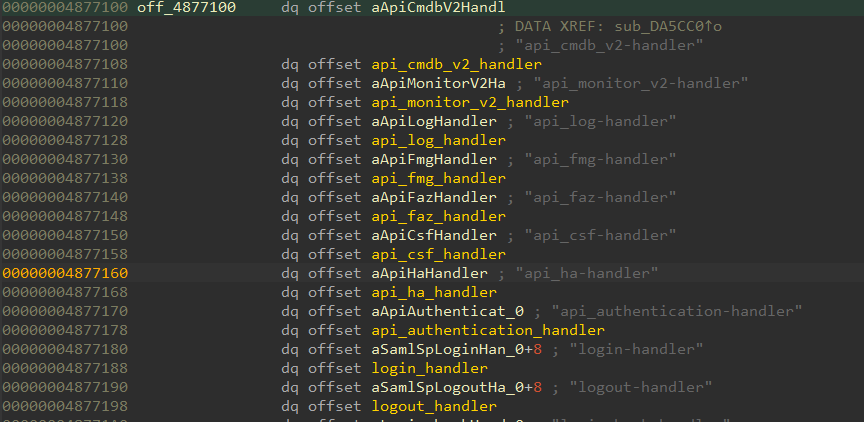 Fig. 11: Lista de controladores como se muestra en IDA
Fig. 11: Lista de controladores como se muestra en IDA
Dado que estábamos interesados en encontrar vulnerabilidades no autenticadas, decidimos centrarnos en api_authentication-handler, al que se puede acceder a través de la URL /api/v2/authentication.
Antes de profundizar en el trabajo de inversión, se recomienda crear algunas estructuras Apache y una estructura de conexión en IDA para facilitar el trabajo (Figuras 12 y 13).
struct __attribute__((aligned(8))) _request_rec
{
apr_pool_t *pool;
conn_rec *connection;
void *server;
_request_rec *next;
_request_rec *prev;
_request_rec *main;
char *the_request;
int assbackwards;
int proxyreq;
int header_only;
int proto_num;
char *protocol;
const char *hostname;
unsigned __int64 request_time;
const char *status_line;
int status;
enum http_methods method_number;
const char *method;
unsigned __int64 allowed;
void *allowed_xmethods;
void *allowed_methods;
unsigned __int64 sent_bodyct;
unsigned __int64 bytes_sent;
unsigned __int64 mtime;
const char *range;
unsigned __int64 clength;
int chunked;
int read_body;
int read_chunked;
unsigned int expecting_100;
void *kept_body;
void *body_table;
unsigned __int64 remaining;
unsigned __int64 read_length;
void *headers_in;
void *headers_out;
void *err_headers_out;
void *subprocess_env;
void *notes;
const char *content_type;
const char *handler;
const char *content_encoding;
void *content_languages;
char *vlist_validator;
char *user;
char *ap_auth_type;
char *unparsed_uri;
char *uri;
char *filename;
char *canonical_filename;
char *path_info;
char *args;
int used_path_info;
int eos_sent;
void *per_dir_config;
void *request_config;
void *log;
const char *log_id;
void *htaccess;
void *output_filters;
void *input_filters;
void *proto_output_filters;
void *proto_input_filters;
int no_cache;
int no_local_copy;
void *invoke_mtx;
apr_uri_t parsed_uri;
apr_finfo_t finfo;
void *useragent_addr;
char *useragent_ip;
void *trailers_in;
void *trailers_out;
char *useragent_host;
int double_reverse;
unsigned __int64 bnotes;
};
Fig. 12: Estructuras Apache
struct __attribute__((aligned(8))) conn_rec
{
apr_pool_t *pool;
void *base_server;
void *vhost_lookup_data;
apr_sockaddr_t *local_addr;
sockaddr *client_addr;
char *client_ip;
char *remote_host;
char *remote_logname;
char *local_ip;
char *local_host;
__int64 id;
void *conn_config;
void *notes;
void *input_filters;
void *output_filters;
void *sbh;
void *bucket_alloc;
void *cs;
int data_in_input_filters;
int data_in_output_filters;
unsigned __int32 clogging_input_filters : 1;
__int32 double_reverse : 2;
unsigned int aborted;
ap_conn_keepalive_e keepalive;
int keepalives;
void *log;
const char *log_id;
conn_rec *master;
int outgoing;
};
Fig. 13: Una estructura de conexión
Al invertir el controlador de autenticación, primero invertimos el controlador de métodos POST, denominado api_login_handler. La función recupera los parámetros de inicio de sesión de la solicitud llamando a api_login_parse_param. Esta función intenta analizar los datos de POST según el encabezado de tipo de contenido:
Si se establece en "multipart/form-data", la solicitud tiene un formulario HTML.
Si no es así, lee los datos de POST sin formato.
La segunda opción es bastante sencilla, por lo que nos centramos principalmente en la primera parte. Al mirar el código descompilado rápidamente notamos una cadena de depuración que nos apuntaba a la biblioteca libapreq (Figura 14).
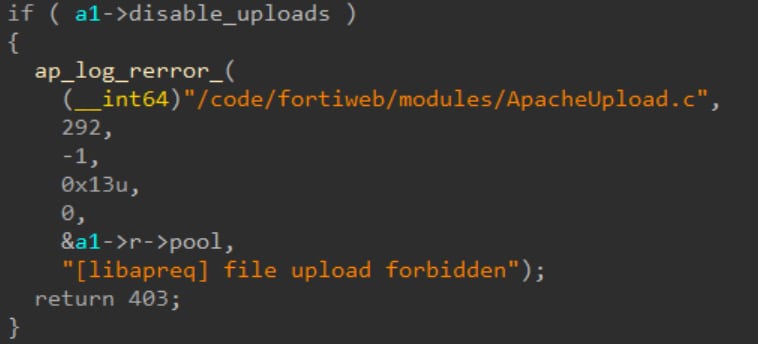 Fig. 14: Una cadena que indica que el código utiliza libapreq
Fig. 14: Una cadena que indica que el código utiliza libapreq
Puesto que libapreq es una biblioteca Apache de código abierto, (casi) no teníamos razón para buscar vulnerabilidades en el código descompilado en lugar del código fuente. Por lo tanto, lo primero que teníamos que hacer era encontrar la versión de la biblioteca. Después de algún tira y afloja, conseguimos reducir la acotar encontrando una cadena que está presente en el binario y una publicación específica, pero que se elimina una publicación más tarde (Figura 15).
 Fig. 15: Comparación entre el código binario descompilado y la publicación de código fuente que elimina la cadena
Fig. 15: Comparación entre el código binario descompilado y la publicación de código fuente que elimina la cadena
Lo sorprendente es que la biblioteca presente en el binario es la versión más antigua disponible desde marzo de 2000 (Figura 16).
 Fig. 16: Versión acotada de libapreq
Fig. 16: Versión acotada de libapreq
Vulnerabilidades
Fortinet utiliza el módulo casi exactamente igual a como lo hacía hace 25 años, excepto por cambios muy pequeños por motivos de optimización. Cuando vimos esto por primera vez, pensamos que no había posibilidad de que el código de 2000 no tuviera vulnerabilidades. ¡Y teníamos razón!
Antes de echar un vistazo a las vulnerabilidades, vamos a explicar el propósito y el uso de la biblioteca. Apreq es una biblioteca Apache que se utiliza para gestionar datos de solicitudes de clientes. Una forma común de recibir datos de un usuario son los formularios HTML. Los datos del formulario relleno se pueden pasar al servidor utilizando diferentes métodos de codificación, pero los métodos comunes son application/x-www-form-urlencoded y multipart/form-data.
Cuando se utiliza multipart/form-data, el cliente (normalmente el explorador) elige un texto arbitrario como límite entre los distintos campos de los datos del formulario. El límite se especifica a través de un encabezado HTTP. El límite también se utiliza para indicar el final de los datos del formulario (Figura 17).
POST /foo HTTP/1.1
Content-Length: 68137
Content-Type: multipart/form-data; boundary=ExampleBoundaryString
--ExampleBoundaryString
Content-Disposition: form-data; name="description"
Description input value
--ExampleBoundaryString
Content-Disposition: form-data; name="myFile"; filename="foo.txt"
Content-Type: text/plain
[content of the file foo.txt chosen by the user]
--ExampleBoundaryString--
Figura 17: Ejemplo de un formulario de límite HTTP (Fuente)
Ahora, echemos un vistazo a algunas de las vulnerabilidades que encontramos, incluidas la escritura fuera de los límites (OOB) de byte nulo, la copia brutal, DoS a dispositivo, DoS al servidor web y la lectura OOB.
Escritura OOB de byte nulo
Después de que multipart_buffer_read llene el búfer interno y busque el límite, devuelve la cadena entre la posición actual y el límite encontrado. El error es que si el límite no está al principio del búfer interno, devuelve la cadena después de eliminar los dos últimos caracteres que se supone que son el final de la línea ("\r\n"). El código supone incorrectamente que la longitud devuelta de la cadena es mayor que 2.
En la figura 18, retval es la cadena devuelta y start es su longitud, que es igual a 1. En este caso, blen también es igual a start. A continuación, se reduce en dos hasta el valor -1. Por lo tanto, tenemos la capacidad de escribir NULL un byte antes del búfer.
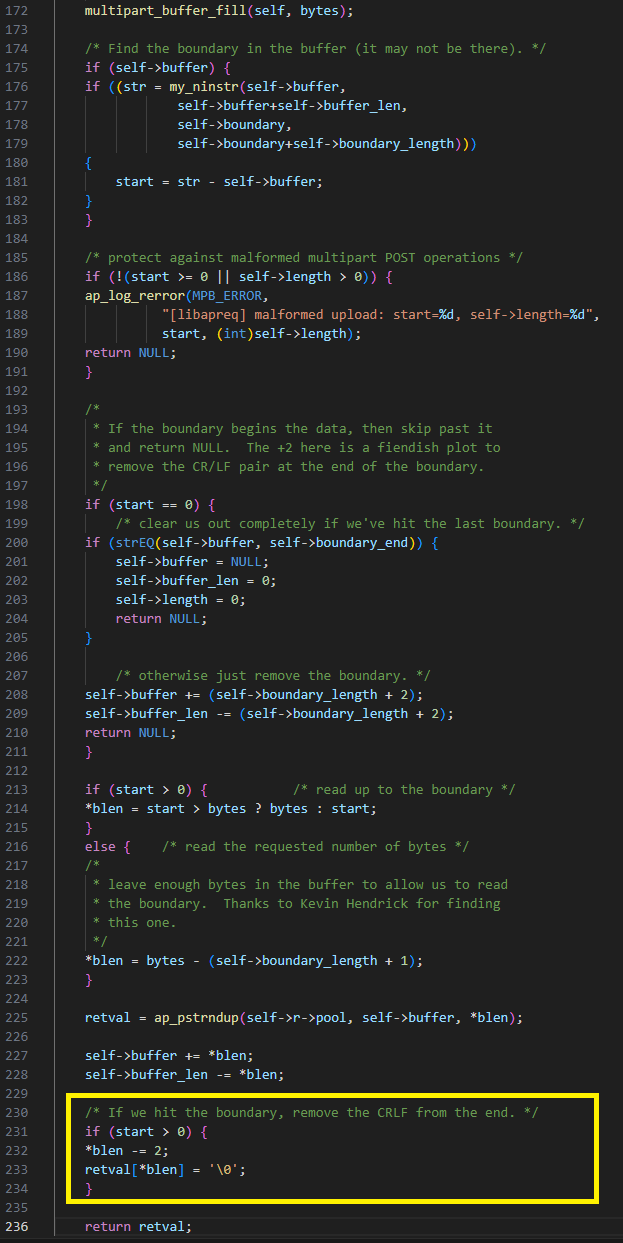 Fig. 18: Vulnerabilidad que provoca una escritura OOB de NULL antes del búfer
Fig. 18: Vulnerabilidad que provoca una escritura OOB de NULL antes del búfer
Intentos de explotación
Aunque un desbordamiento de un byte, incluso un desbordamiento de un bit, puede ser suficiente para lograr la ejecución de código, creemos que es poco probable que esta vulnerabilidad se pueda explotar en la práctica. En primer lugar, solo podemos escribir un byte nulo, y solo un byte antes del búfer. El búfer se asigna en el montón; por lo tanto, hay dos opciones:
1. El búfer es el primer búfer que se asigna en el nodo del montón. En este caso, tendremos los metadatos del nodo del montón antes de nuestra asignación (Figura 19).
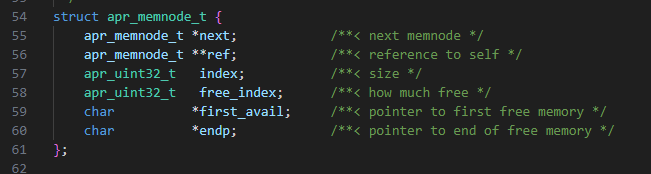 Fig. 19: Estructura que representa un nodo del montón de memoria de Apache
Fig. 19: Estructura que representa un nodo del montón de memoria de Apache
Sobrescribiremos un byte del puntero endp. Esto no afectaría al valor del puntero porque sobrescribimos el byte más alto del puntero debido a la endianness. Puesto que la VM es x64, este byte siempre será 0.
2. Si ha habido una asignación antes que nosotros, podremos sobrescribir un byte de datos. Desafortunadamente, como en el ejemplo anterior, en la mayoría de los casos, tendremos un puntero al final de la estructura, relleno o una cadena C que ya está terminada en NULL.
Encontramos un objeto interesante: la estructura de C multipart_buffer (Figura 20).
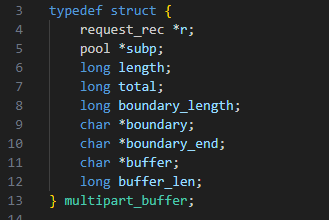 Fig. 20: Estructura C multipart_buffer
Fig. 20: Estructura C multipart_buffer
En este caso, pensamos que podríamos hacer que buffer_len, la última variable de la estructura, fuera negativa a través de la vulnerabilidad anterior y, a continuación, cambiarla de menos a un valor positivo grande con esta vulnerabilidad (sobrescribiendo el byte MSB que marca el número como negativo).
Aunque este enfoque parecía interesante, hay dos problemas:
1. La estructura se crea solo una vez: al crear el analizador de formularios. Esto significa que no podríamos pulverizar este objeto fácilmente.
2. Una vez utilizada la vulnerabilidad anterior, limitamos la longitud leída en la función de relleno. Esto significa que una vez finalizada la función de llenado, self->length es 0 después de leer los datos POST de la solicitud completa. La próxima vez que el código llame a multipart_buffer_read, no encontraría el límite en el búfer avanzado (ya que hicimos que el puntero final apareciera antes de su comienzo), y como self->length es 0, saldría avisando de una carga mal formada.
Pensamos en intentar explotarlo en un intento de condición de carrera, pero si observamos el modo de multiprocesamiento (MPM) de Apache, vemos la figura 21.
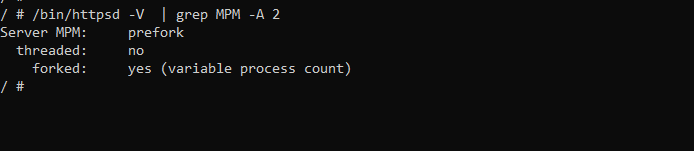 Fig. 21: Comprobación del modo MPM de Apache
Fig. 21: Comprobación del modo MPM de Apache
Esto significa que Apache bifurcará varios procesos y que cada uno manejará una solicitud. También podemos observar que esos procesos no tienen varios subprocesos. Esto significa que no podremos explotarlos en condiciones de carrera.
Copia brutal
En la misma función, multipart_buffer_read, si el código no encuentra el límite (el inicio es igual a -1), devuelve solo parte del búfer interno: (bytes - boundary_length). El error aquí es que bytes se establece en el valor constante 5120, mientras que la longitud del límite puede ser mucho mayor (hasta el límite de la longitud del encabezado).
Por lo tanto, al enviar un campo en el que el límite no está en el primer fragmento, y la longitud del límite es mayor que 5120, podemos hacer que "blen" sea negativo. Esto lleva a que el código configure self->buffer antes del búfer y self->buffer_len en un valor mayor (Figura 22).
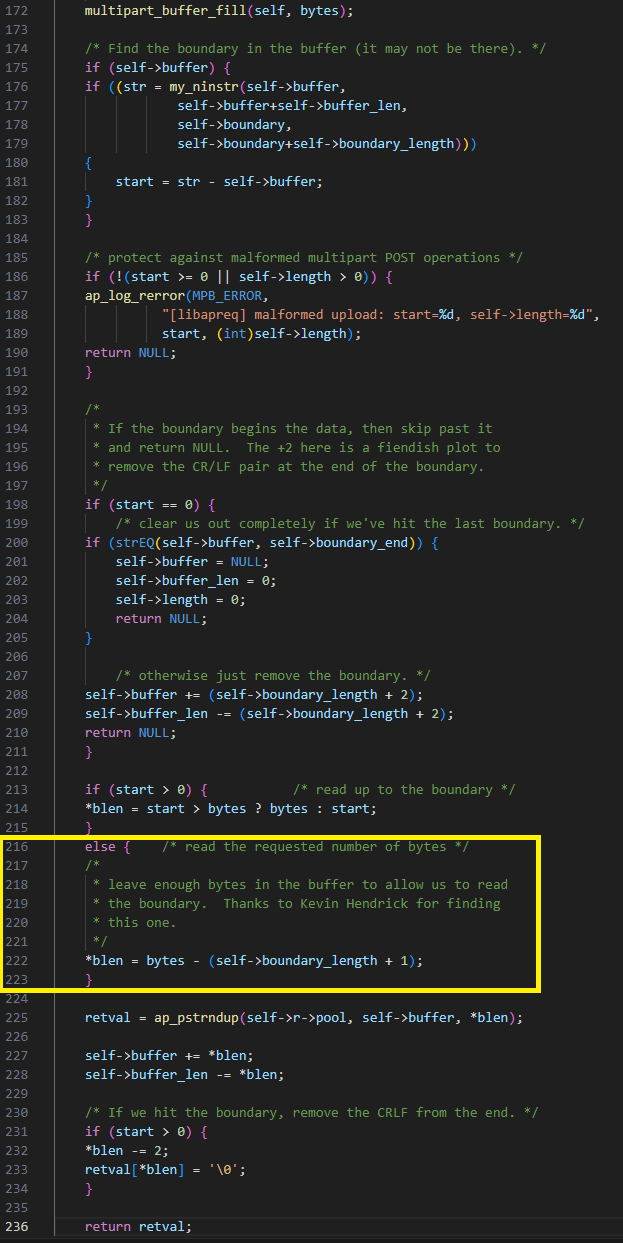 Fig. 22: Vulnerabilidad debido a un subdesbordamiento de enteros
Fig. 22: Vulnerabilidad debido a un subdesbordamiento de enteros
Intentos de explotación
Hay una diferencia entre esta vulnerabilidad y la anterior: esta vez, dado que el inicio es negativo (no se encontró el límite), no llegamos al código que escribe un byte nulo.
El parámetro "blen" está dentro de la función multipart_buffer_read, así que observemos la función multipart_buffer_read_body que lo llama y recibe "blen" como resultado.
La figura 23 muestra que "blen" se utiliza dos veces:
1. Si es el primer búfer creado, la cadena recibida de multipart_buffer_read se duplica mediante "blen". En este caso, Apache genera un error de falta de memoria (OOM) y se anula el código. Esto se puede utilizar para lanzar un ataque DoS.
2. Si es el segundo bloque, el anterior y el actual se unen mediante la función my_join. La función llama a "memcpy" con un número negativo, lo que provoca una copia brutal.
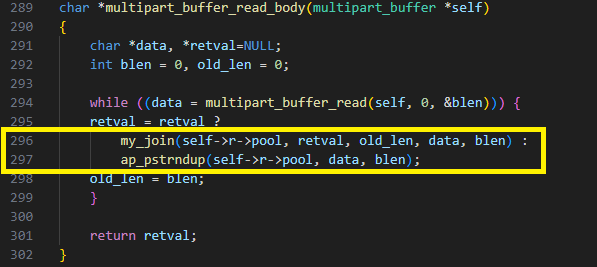 Fig. 23: Los dos flujos diferentes en multipart_buffer_read_body
Fig. 23: Los dos flujos diferentes en multipart_buffer_read_body
(Algunos de ustedes pueden haber notado otro error en este código; "old_len" se actualiza para que sea "blen" en lugar de "old_len + blen", lo que conduce a un truncamiento de los datos de los usuarios).
Explotar esa copia brutal sería muy difícil, si es que fuera posible. Primero, no tenemos ninguna opción para "detener" la copia brutal, es una copia de memoria (memcpy) con un gran tamaño. En segundo lugar, no hay varios subprocesos, por lo que no podemos sobrescribir un objeto que se utilizará en otro subproceso simultáneamente. Asumimos que la única opción posible es explotar el controlador de señales si no realiza una salida segura.
DoS a dispositivo
En realidad, esta vulnerabilidad no se encuentra en la biblioteca en sí, sino en el código de Fortinet que utiliza la biblioteca.
Cuando el usuario carga un archivo a través del formulario, que se especifica con un encabezado Content-Disposition dentro de los datos POST (consulte la figura 17), se crea un nuevo archivo dentro de la carpeta /tmp/ con el nombre de archivo /tmp/uploadXXXXXX, donde las X son caracteres aleatorios.
Para cada carga de archivos, se crea una estructura adecuada y se inserta en una lista vinculada de archivos cargados. El error aparece al final del análisis cuando solo se elimina el archivo del primer nodo de la lista vinculada. Esto permite a un atacante iniciar un ataque rellenando la carpeta /tmp/. Como /tmp/ es un sistema de archivos tmpfs, los datos se almacenan en la RAM. Esto provoca un caso de OOM completo del sistema, lo que provoca que el dispositivo se bloquee.
Solo al reiniciar el dispositivo, este vuelve a su uso normal, e incluso eso no está garantizado. En uno de nuestros intentos, hemos causado algún tipo de bloqueo en la red del dispositivo: Incluso después de reiniciar el dispositivo, la funcionalidad de red no funcionaba correctamente y no pudimos utilizar o conectar con el dispositivo.
Intentos de explotación
Esta vulnerabilidad es bastante fácil de explotar. Todo lo que se necesita es enviar solicitudes repetidamente con un formulario que contenga varios archivos. Después de un breve periodo de tiempo, el dispositivo se bloqueará (Figura 24).
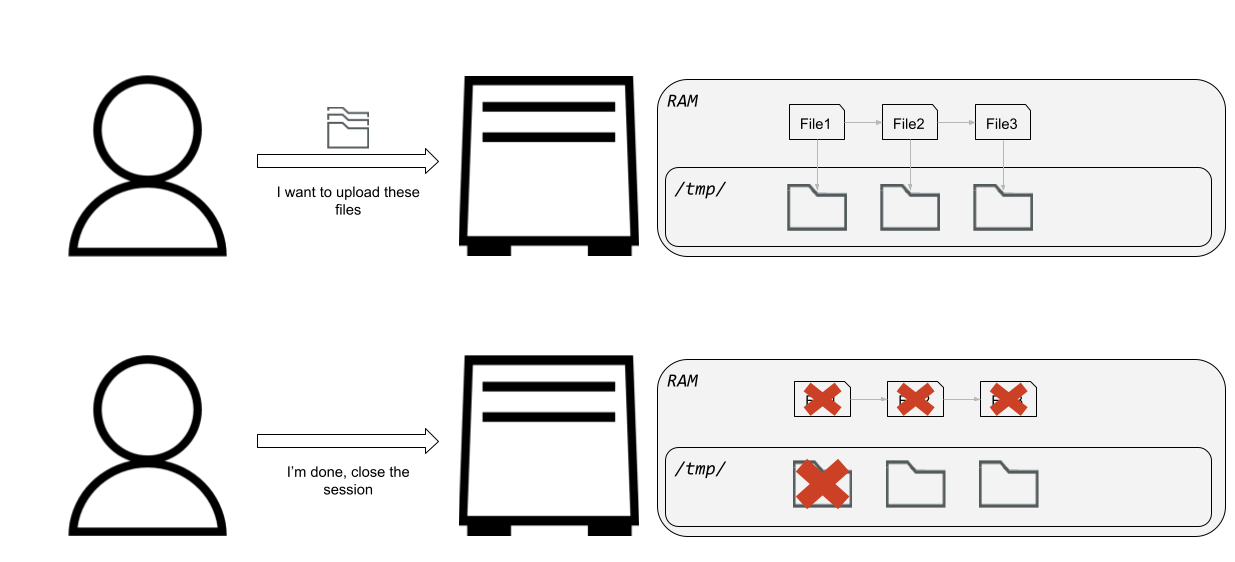 Fig. 24: Llenado de la RAM del dispositivo VPN con archivos no eliminados, logrando finalmente una DoS debido a la falta de memoria
Fig. 24: Llenado de la RAM del dispositivo VPN con archivos no eliminados, logrando finalmente una DoS debido a la falta de memoria
DoS al servidor web
Se trata de una vulnerabilidad menor en la función multipart_buffer_headers. Llama a multipart_buffer_fill, que rellena el búfer interno y, a continuación, busca una línea doble que termine en el búfer interno.
El error es que el código no comprueba que el búfer interno sea válido después de llamar a multipart_buffer_fill. Si el cliente borró la conexión mientras multipart_buffer_fill esperaba la entrada, define el búfer en NULL y esto lleva a una desreferencia NULL (Figura 25).
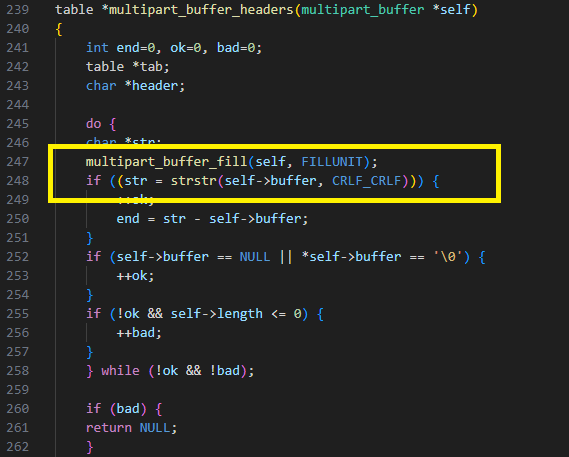 Fig. 25: Acceso al búfer interno sin comprobar si es válido
Fig. 25: Acceso al búfer interno sin comprobar si es válido
Intentos de explotación
Esta vulnerabilidad también es bastante fácil de explotar. Un atacante puede crear varios subprocesos que creen una conexión y envíen la solicitud de bloqueo. Dado que el MPM de Apache previo a la bifurcación no proporciona un gran rendimiento, el servidor no podrá manejar los múltiples bloqueos y no podrá servir a otros clientes mientras el ataque esté en curso.
Lectura OOB
La biblioteca utiliza un búfer interno que se llena con regularidad. Cuando se rellena, el cálculo de cuántos bytes se deben leer es el siguiente:
1. Calcular (bytes_requested - current_internal_buffer_len)
2. Añadir longitud de límite + 2 (para "\r\n\r\n")
3. Calcular el mínimo entre este resultado y los bytes disponibles para leer de los datos POST
La vulnerabilidad se encuentra en multipart_buffer_read. Si encuentra el límite al principio del búfer interno y no es el límite el que marca el final del formulario, hace avanzar el puntero del búfer interno más allá del límite y agrega otros 2 bytes al final de línea.
El error aquí es que un atacante puede hacer que el búfer interno tenga exactamente el tamaño del límite, haciendo que el código avance dos bytes más allá del final del búfer interno (Figura 26). Esto se puede hacer dado que podemos "limitar" el cálculo del búfer interno proporcionando una cantidad de bytes menor que boundary_length + bytes_requested.
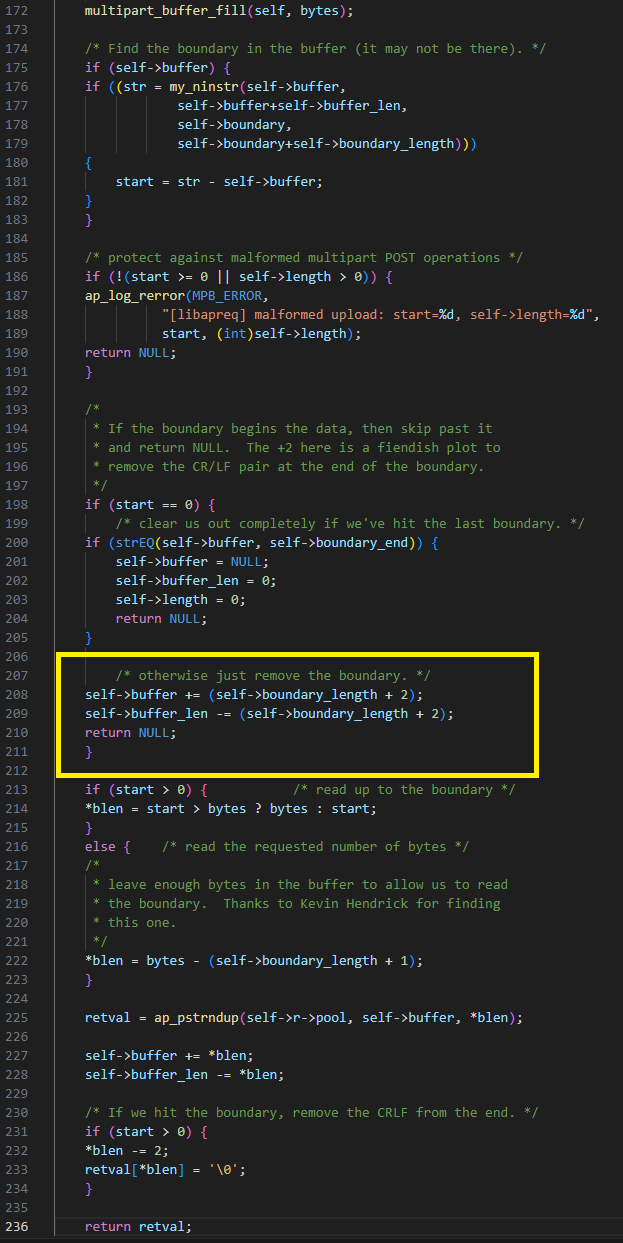 Fig. 26: Haciendo avanzar el búfer interno más allá de su extremo
Fig. 26: Haciendo avanzar el búfer interno más allá de su extremo
Intentos de explotación
Como se muestra en la figura 26, el código devuelve NULL. Sin embargo, como vimos en el error anterior, el código en multipart_buffer_headers accede directamente al búfer interno, y no al valor devuelto. Esto hará que el código busque "\r\n" después del búfer y lo devuelva como un encabezado.
En el uso de Apreq en el controlador de inicio de sesión, el código lee los campos del formulario, pero no los devuelve al cliente, por lo que no podemos utilizar la vulnerabilidad OOB como una fuga de información en este caso. La biblioteca también se utiliza varias veces en el servidor web, pero parece que solo está disponible para usuarios autenticados, por lo que, como mucho, un atacante con credenciales de usuario con privilegios bajos podría utilizarla como una vulnerabilidad de escala de privilegios leyendo las credenciales de usuario con privilegios altos de la memoria.
SSLVPND
SSLVPND es el daemon responsable de gestionar el componente SSL-VPN de Fortinet. Es accesible a Internet. La biblioteca Apreq también se utiliza en el SSLVPND. La biblioteca que se utiliza allí se basa en la misma versión antigua de Apreq, con algunas modificaciones. Todas las vulnerabilidades descritas anteriormente, a excepción de la vulnerabilidad DoS al dispositivo, también existen en SSLVPND.
Lamentablemente, no hemos podido activar la biblioteca Apreq en SSLVPND, por lo que no podemos confirmar si esas vulnerabilidades son accesibles para usuarios no autenticados o si dichas vulnerabilidades podrían explotarse en el contexto SSLVPND.
Resumen
Los atacantes suelen dirigirse a las VPN debido a su naturaleza de acceso a Internet. En esta entrada de blog, analizamos un ejemplo de un enfoque para investigar un dispositivo VPN. Aunque no se identificaron vulnerabilidades críticas, creemos que es seguro suponer que hay vulnerabilidades adicionales a la espera de ser descubiertas.
Dado que las VPN son una puerta de enlace a la red de una organización, las vulnerabilidades de esos dispositivos tienen un gran impacto en las organizaciones. Esperamos que esta entrada de blog también anime a otros investigadores sobre seguridad a buscar vulnerabilidades de VPN.