
Exploration d'un dispositif VPN : le parcours d'un chercheur


- Ben Barnea, chercheur chez Akamai, a découvert plusieurs vulnérabilités dans FortiOS de Fortinet.
- Un attaquant non authentifié peut exploiter des vulnérabilités pour déclencher des attaques de type DoS et RCE
- La vulnérabilité DoS est facile à exploiter et entraîne le dysfonctionnement du dispositif FortiGate.
- Nous supposons que la vulnérabilité RCE est difficile à exploiter.
- Les vulnérabilités ont été divulguées de manière responsable à Fortinet et ont été attribuées à CVE-2024-46666 et CVE-2024-46668.
- Fortinet a traité les vulnérabilités découvertes par Barnea le 14 janvier 2025, et les terminaux dotés de versions FortiOS à jour sont protégés.
Introduction
Au cours des dernières années, les solutions VPN ont souffert de nombreuses vulnérabilités critiques qui ont été exploitées par des acteurs malveillants. Certaines de ces vulnérabilités sont incroyablement faciles à exploiter et ont un impact dévastateur, avec l'exécution de code à distance (RCE) sur un dispositif VPN exposé à Internet. Une fois à l'intérieur du réseau, les pirates peuvent se déplacer latéralement pour accéder aux données sensibles, à la propriété intellectuelle et à d'autres ressources e grande valeur.
En plus de l'exploitation initiale des vulnérabilités des VPN, Ori David, chercheur chez Akamai, a également documenté les techniques de post-exploitation et a montré qu'un serveur VPN compromis pouvait permettre aux attaquants de prendre facilement le contrôle d'autres ressources critiques du réseau.
Malheureusement, les chercheurs en sécurité qui souhaitent examiner les dispositifs VPN ont du mal à commencer leur recherche, car les micrologiciels ne sont pas toujours facilement disponibles et sont protégés par des mécanismes de chiffrement déployés par les fabricants. Cependant, étant donné que les dispositifs VPN sont des cibles privilégiées pour l'exploitation, il peut être utile pour les pirates de surmonter ces protections.
Dans cet article de blog, nous allons étudier le processus de recherche de la solution VPN de Fortinet. Nous allons passer en revue les processus d'obtention du micrologiciel, de déchiffrement, de configuration d'un débogueur et enfin de recherche de vulnérabilités.
Certaines des recherches présentées dans ce post ne sont pas nouvelles : d'importantes recherches sur FortiOS ont été menées par Optistream, Bishop Fox, Assetnote, Lexfo et plus encore. Nous avons mis à jour leurs recherches initiales avec la version la plus récente de FortiOS, car Fortinet modifie souvent les méthodes de chiffrement et de déchiffrement, ce qui rend l'analyse du terminal plus difficile.
Obtention d'une image de micrologiciel
Traditionnellement, les VPN étaient vendus sous forme de dispositif physique distinct, ce qui pouvait compliquer leur acquisition et l'extraction de leur micrologiciel. Aujourd'hui, cependant, il est beaucoup plus courant de trouver des dispositifs VPN comme des dispositifs virtuels pouvant être déployés sur une machine virtuelle (VM).
Heureusement pour nous, Fortinet propose une version d'essai de la VM qu'il est possible de télécharger après s'être inscrit sur son site Web (Figure 1). La VM est limitée : un seul CPU est autorisé et il est limité à 2 Go de RAM.
 Fig. 1 : Versions d'essai de VM téléchargeables
Fig. 1 : Versions d'essai de VM téléchargeables
Création d'un environnement de débogage
La VM fournie contient deux points d'intérêt : (1) une image de démarrage, ainsi qu'une image de noyau (appelée flatkc), et (2) un système de fichiers chiffré rootfs qui contient la plupart des fichiers intéressants. Une fois le système de fichiers déchiffré, nous pouvons trouver un fichier binaire nommé init dans le répertoire /bin/.
La plupart des fichiers binaires de la VM ont été compilés de manière statique dans ce binaire. SSLVPND et le serveur Web de gestion sont deux binaires intéressants présents dans /bin/init. Nous reviendrons plus tard sur ces fichiers binaires.
Nous souhaitons créer un environnement dans lequel nous disposons d'un shell complet, et non de la CLI contrainte que nous recevons de Fortinet. En outre, nous voulions disposer d'un fichier binaire gdb qui nous permettrait de déboguer facilement les fichiers binaires.
Pour créer un tel environnement, il faut procéder comme suit :
- Décompresser le fichier CPIO compressé GZIP (format d'archive de fichier).
- Utiliser le script de Bishop Fox pour déchiffrer le rootfs
- Décompresser l'archive bin.tar.xz
- Appliquer le correctif au contrôle d'intégrité /bin/init
- Convertir le flatkc en ELF avec vmlinux-to-elf
- Rechercher l'adresse de fgt_verify_initrd dans IDA, afin de pouvoir appliquer un correctif pendant la durée d'exécution et désactiver les autres contrôles d'intégrité
- Déposez un busybox compilé statiquement et un gdb à l'intérieur de /bin/.
- Compiler un fichier stub qui crée un serveur telnet ; remplacer /bin/smartctl par ce fichier stub
- Compresser en tar le dossier /bin/
- Réempaqueter le rootfs, le chiffrer
- Ajouter un remplissage à la fin du répertoire racine chiffré
- Remplacer le rootfs dans le VMDK en utilisant une VM Ubuntu d'aide (qui monte le VMDK)
Les étapes illustrées sur la Figure 2 permettent de créer une machine virtuelle modifiée avec des fonctionnalités de débogage. Étant donné que le contrôle d'intégrité du rootfs échoue, le noyau arrête l'exécution. Par conséquent, nous devons appliquer un correctif au noyau (flatkc), puis en appliquer un autre au code de vérification de l'intégrité du chargeur d'amorçage, ou nous devons appliquer un correctif dynamique au contrôle d'intégrité du noyau. Nous avons décidé d'adopter cette dernière approche.
 Fig. 2 : Application de correctifs à FortiGate pour un environnement de recherche
Fig. 2 : Application de correctifs à FortiGate pour un environnement de recherche
Nous avons essayé d'utiliser la fonction de débogage de VM de VMware en modifiant le fichier VMDK. Cela devrait configurer un débogueur GDB qui sera disponible une fois la machine exécutée. Malheureusement, nous avons rencontré un problème avec l'implémentation de cette fonctionnalité lors de l'exécution sur une machine sur laquelle Hyper-V est activé. Dès qu'un point d'arrêt est rencontré, la machine tombe en panne. Cela semble être dû à une implémentation incomplète de la fonction de débogage du noyau lorsqu'elle est exécutée sur une machine Hyper-V.
Tentative de création d'une VM en cours d'exécution avec QEMU
Après plusieurs tentatives infructueuses d'exécution du débogage du noyau avec VMware, nous avons décidé d'essayer de créer une VM en cours d'exécution avec QEMU. Nous avons créé la VM modifiée de manière statique en suivant les mêmes étapes, sauf pour la conversion entre les formats de fichier qcow2 et VMDK.
Pour déboguer le noyau en utilisant QEMU, nous pouvons fournir l'indicateur -s à qemu-system. Enfin, nous exécutons la machine virtuelle, joignons GDB et ajoutons un point de rupture pour écraser le contrôle d'intégrité. Nous arrivons alors sur l'interface de ligne de commande. (Figure 3).
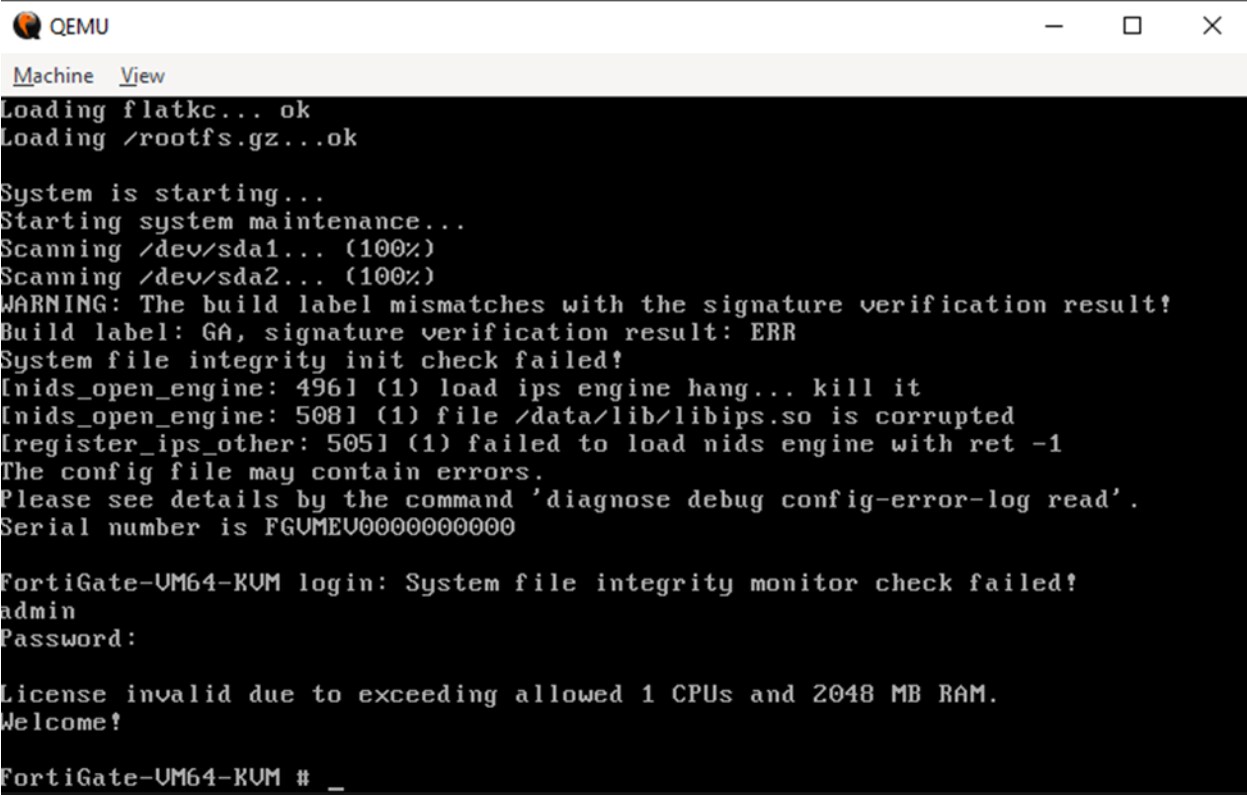 Fig. 3 : Une machine virtuelle en état de marche avec CLI
Fig. 3 : Une machine virtuelle en état de marche avec CLI
Après avoir configuré les paramètres réseau et reçu une adresse IP valide du serveur DHCP, nous pouvons exécuter le code binaire smartctl modifié qui imprime le contenu du répertoire actuel, la commande id de Linux, et ouvre une session telnet busybox. (Figure 4).
 Fig. 4 : Activation de la porte dérobée
Fig. 4 : Activation de la porte dérobée
Enfin, la Figure 5 montre que nous nous sommes connectés au nouveau serveur telnet.
 Fig. 5 : Connexion au shell
Fig. 5 : Connexion au shell
Est-ce que nous avons terminé ? Non.
Comme vous pouvez le voir sur la Figure 6, nous ne disposons pas d'une licence valide et ne pouvons donc pas interagir avec le panneau d'administration.
 Fig. 6 : Erreur de licence
Fig. 6 : Erreur de licence
Vous ne dériverez pas
Au début, nous pensions que la licence n'était pas valide, car nous avions dépassé la limite de 1 CPU et 2 048 Mo de RAM. Nous avions donc deux options : accepter cette limite et avoir une VM très lente, ou la contourner.
Après une inversion, nous avons trouvé la fonction upd_vm_check_license qui est appelée périodiquement dans un démon (Figure 7). La fonction vérifie que la RAM de la machine et le nombre de CPU ne dépassent pas les limites.
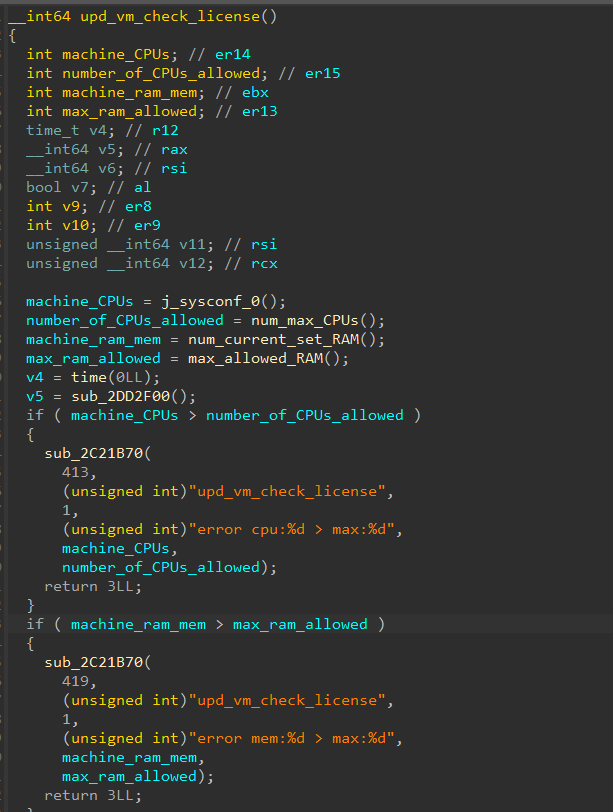 Fig. 7 : Code décompilé responsable des contraintes de la VM
Fig. 7 : Code décompilé responsable des contraintes de la VM
Après avoir contourné les restrictions en modifiant dynamiquement la valeur de retour de num_max_CPUs() et max_allowed_RAM(), nous disposons désormais d'une machine virtuelle puissante sans contrainte et recevons moins d'erreurs lorsque nous démarrons la machine, mais nous recevons toujours une erreur de licence non valide.
Après avoir passé beaucoup trop de temps à inverser la fonction de validation de licence et à réfléchir aux choix de durée de vie qui nous ont conduits à y parvenir, nous avons finalement découvert que la licence utilise la clé série de la machine, qui a été construite à l'aide de l'UUID SMBIOS. Puisque nous n'en avons pas fourni à QEMU, il a utilisé un NULL, et c'est pourquoi le numéro de série créé était « FGVMEV0000000000 ». Après avoir fourni un UUID SMBIOS à QEMU avec l'indicateur suivant :
-smbios type=1,manufacturer=t1manufacturer,product=t1product,version=t1version,serial=t1serial,
uuid=25359cc8-5fe7-4d50-ab82-9fd15ecaf221,sku=t1sku,family=t1family
Nous avons enfin démarré la machine et reçu une licence valide.
Nouvelle version. Nouveau chiffrement. POURQUOI ?
À ce stade, nous disposons d'un environnement de débogage opérationnel. Nous avons commencé à étudier le serveur Web de gestion et avons découvert certaines vulnérabilités que nous décrirons plus tard dans cet article. Lorsque nous avons détecté ces vulnérabilités, nous avons remarqué que Fortinet avait publié la version 7.4.4 de FortiOS.
Nous voulions voir si les vulnérabilités existaient toujours dans la nouvelle version, mais après avoir omis de déchiffrer les répertoires racine de la machine virtuelle mise à jour, nous avons abouti à un chiffrement complètement différent, encore plus difficile à déchiffrer. Cette fois-ci, nous avons décidé de déchiffrer le nouveau rootfs, mais pas de créer un environnement de débogage, car l'objectif principal à ce stade était de vérifier que les vulnérabilités existent toujours.
Commençons par décrire l'ancienne méthode (antérieure à la version 7.4.4) de déchiffrage du rootfs :
1. Le noyau vérifie l'intégrité du rootfs. S'il est valide, il passe à l'étape suivante.
2. Le noyau appelle fgt_veritifer_key_iv, qui calcule une clé et un IV comme suit :
a. Clé : sha256() d'une donnée globale
b. IV : sha256() d'une autre partie des mêmes données globales ; puis, tronque le résultat à 16 octets
3. Il décrypte les répertoires racine à l'aide de Chacha20 avec key et IV comme ci-dessus
Examinons maintenant le nouvel algorithme (Figure 8) :
1. Le code de déchiffrement calcule key et IV avec sha256() appartenant à un tampon de données global, comme dans l'algorithme précédent
2. ChaCha décrypte un bloc de mémoire à l'aide de key et de IV ; ce bloc de mémoire est un ASN1 représentant une clé privée RSA
3. Prend d,n depuis la clé privée RSA et déchiffre un bloc de données présent dans les 256 derniers octets du micrologiciel chiffré avec la formule connue M = Cd mod N
4. À partir du bloc de données, prend :
16 octets pour nonce + counter
32 octets clés
5. Effectue le déchiffrement AES en mode CTR, avec key et nonce + counter ; le code utilise un ajout CTR personnalisé
6. L'ajout est le résultat de l'opération OU exclusif aux octets de nonce + counter
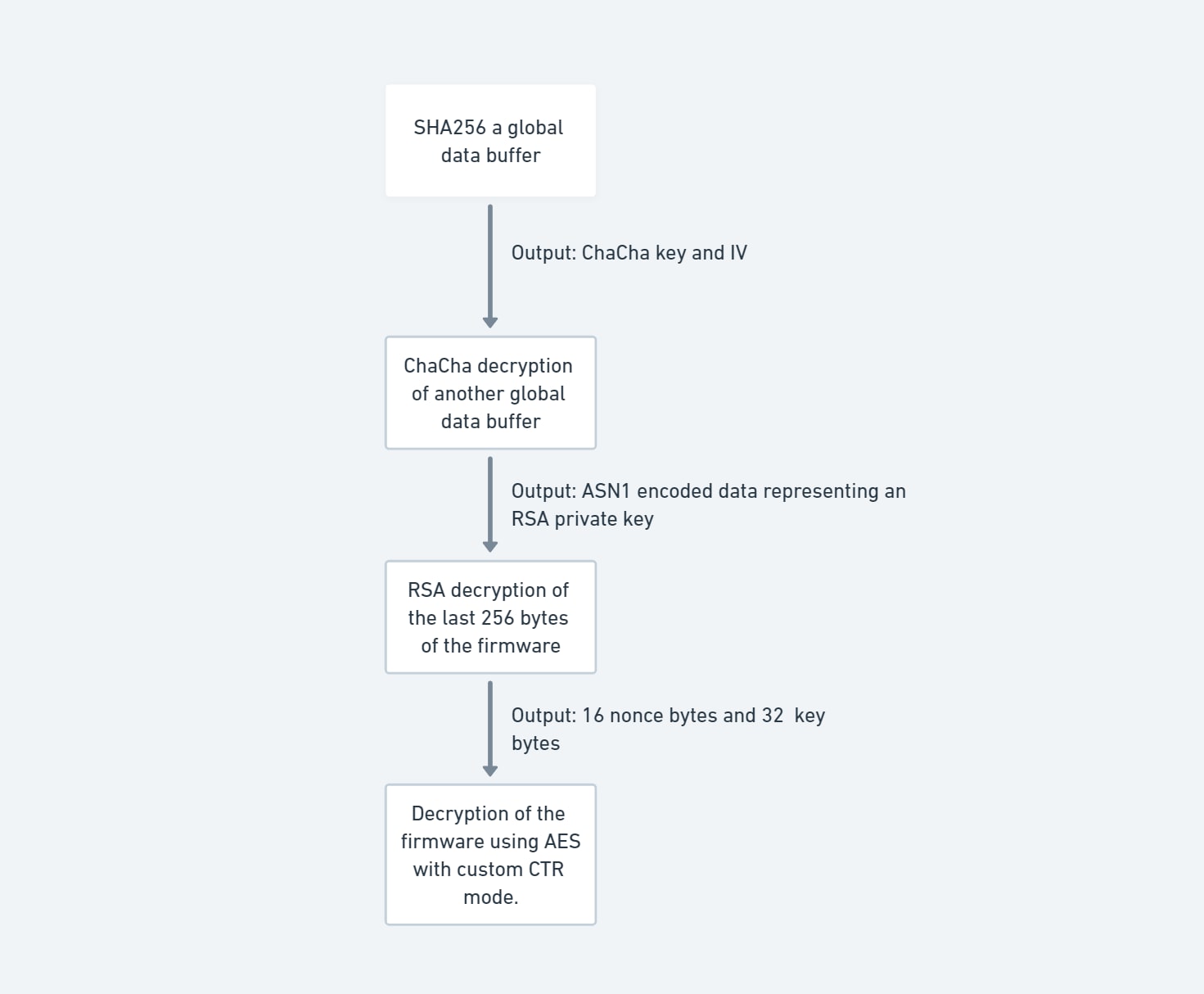 Fig. 8 : Organigramme de déchiffrement du micrologiciel
Fig. 8 : Organigramme de déchiffrement du micrologiciel
Pour ajouter de la complexité à cet algorithme de déchiffrement à plusieurs étapes, le nouveau flatkc n'a plus de symboles, ce qui rend plus difficile l'écriture d'outils pour déchiffrer automatiquement le micrologiciel (par exemple, la recherche des données globales utilisées pour le déchiffrement ChaCha et la clé privée RSA chiffrée).
Après avoir suivi toutes les étapes décrites ci-dessus, nous pouvons afficher les rootfs (Figure 9).
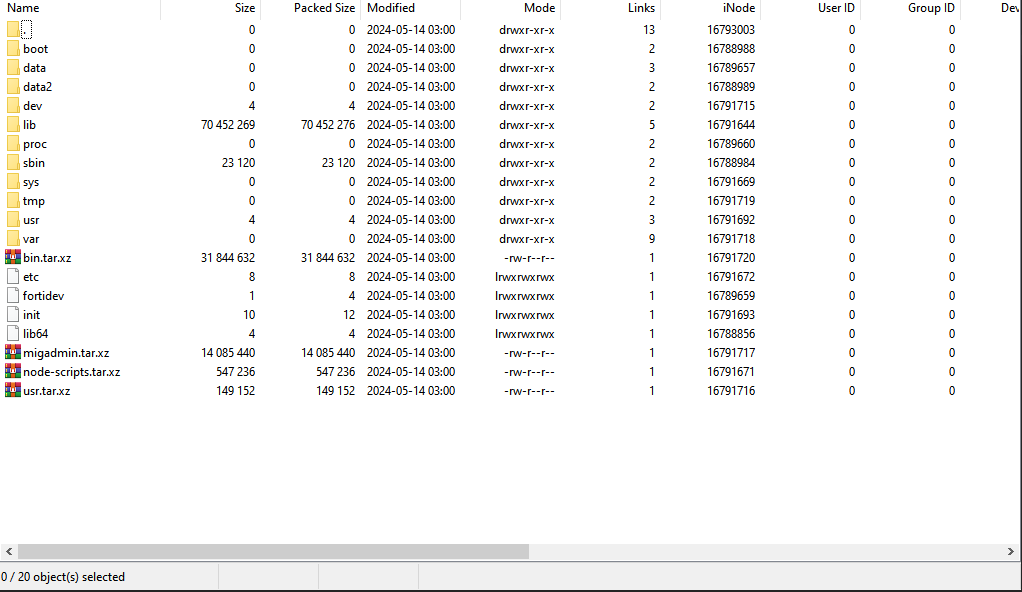 Fig. 9 : La compression du répertoire racine
Fig. 9 : La compression du répertoire racine
Cette fois, nous n'avons pas créé d'environnement modifié. Pour ce faire, vous devez créer une archive rootfs qui doit être correctement déchiffrée comme décrit ci-dessus. Une autre option consiste à définir dynamiquement les points d'arrêt et à remplacer la mémoire par un rootfs déchiffré.
Inversion du serveur Web d'administration
Nous pouvons enfin inverser le serveur Web d'administration. Il est basé sur Apache et, en général, ne doit pas être accessible à Internet (contrairement à l'interface sslvpn).
Lorsque nous ouvrons la configuration httpd, nous pouvons remarquer certaines directives d'emplacement qui pointent les URL vers leurs gestionnaires (Figure 10).
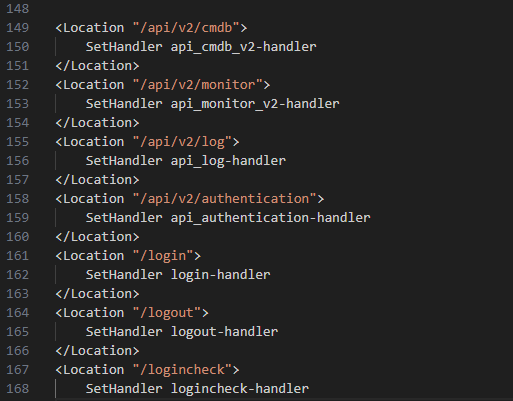 Fig. 10 : Extrait du fichier de configuration httpd
Fig. 10 : Extrait du fichier de configuration httpd
Nous pouvons ensuite rechercher l'une des chaînes de gestionnaire dans le fichier binaire pour trouver la table de gestionnaire (Figure 11).
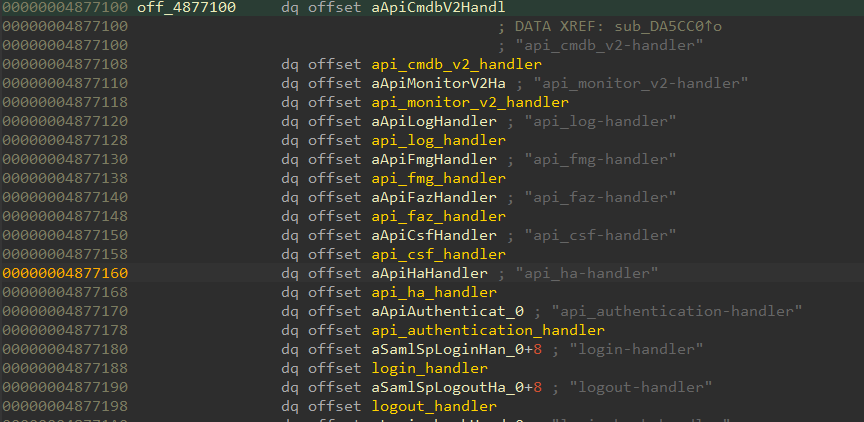 Fig. 11 : Liste des gestionnaires comme indiqué dans IDA
Fig. 11 : Liste des gestionnaires comme indiqué dans IDA
Étant donné que nous étions intéressés par la recherche de vulnérabilités non authentifiées, nous avons décidé de nous concentrer sur api_authentication-handler accessible via l'URL /api/v2/authentication.
Avant de passer au travail de rétroaction, il est recommandé de créer quelques structures Apache et une structure de connexion dans IDA pour faciliter le travail (Figures 12 et 13).
struct __attribute__((aligned(8))) _request_rec
{
apr_pool_t *pool;
conn_rec *connection;
void *server;
_request_rec *next;
_request_rec *prev;
_request_rec *main;
char *the_request;
int assbackwards;
int proxyreq;
int header_only;
int proto_num;
char *protocol;
const char *hostname;
unsigned __int64 request_time;
const char *status_line;
int status;
enum http_methods method_number;
const char *method;
unsigned __int64 allowed;
void *allowed_xmethods;
void *allowed_methods;
unsigned __int64 sent_bodyct;
unsigned __int64 bytes_sent;
unsigned __int64 mtime;
const char *range;
unsigned __int64 clength;
int chunked;
int read_body;
int read_chunked;
unsigned int expecting_100;
void *kept_body;
void *body_table;
unsigned __int64 remaining;
unsigned __int64 read_length;
void *headers_in;
void *headers_out;
void *err_headers_out;
void *subprocess_env;
void *notes;
const char *content_type;
const char *handler;
const char *content_encoding;
void *content_languages;
char *vlist_validator;
char *user;
char *ap_auth_type;
char *unparsed_uri;
char *uri;
char *filename;
char *canonical_filename;
char *path_info;
char *args;
int used_path_info;
int eos_sent;
void *per_dir_config;
void *request_config;
void *log;
const char *log_id;
void *htaccess;
void *output_filters;
void *input_filters;
void *proto_output_filters;
void *proto_input_filters;
int no_cache;
int no_local_copy;
void *invoke_mtx;
apr_uri_t parsed_uri;
apr_finfo_t finfo;
void *useragent_addr;
char *useragent_ip;
void *trailers_in;
void *trailers_out;
char *useragent_host;
int double_reverse;
unsigned __int64 bnotes;
};
Fig. 12 : Structures Apache
struct __attribute__((aligned(8))) conn_rec
{
apr_pool_t *pool;
void *base_server;
void *vhost_lookup_data;
apr_sockaddr_t *local_addr;
sockaddr *client_addr;
char *client_ip;
char *remote_host;
char *remote_logname;
char *local_ip;
char *local_host;
__int64 id;
void *conn_config;
void *notes;
void *input_filters;
void *output_filters;
void *sbh;
void *bucket_alloc;
void *cs;
int data_in_input_filters;
int data_in_output_filters;
unsigned __int32 clogging_input_filters : 1;
__int32 double_reverse : 2;
unsigned int aborted;
ap_conn_keepalive_e keepalive;
int keepalives;
void *log;
const char *log_id;
conn_rec *master;
int outgoing;
};
Fig. 13 : Une structure de connexion
Lors de l'inversion du gestionnaire d'authentification, nous avons d'abord inversé le gestionnaire de méthode POST, nommé api_login_handler. La fonction récupère les paramètres de connexion à partir de la demande en appelant api_login_parse_param. Cette fonction tente d'analyser les données POST en fonction de l'en-tête du type de contenu :
Si elle est définie sur « multipart/form-data », la requête a un formulaire HTML
Si ce n'est pas le cas, lisez les données POST simples
La deuxième option est assez simple, nous nous sommes donc principalement concentrés sur la première partie. En examinant le code décompilé, nous avons rapidement identifié une chaîne de débogage dirigeant vers la bibliothèque libapreq (Figure 14).
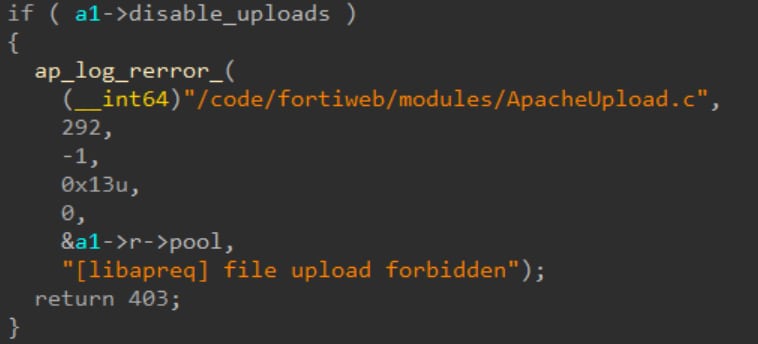 Fig. 14 : Chaîne indiquant que le code utilise la bibliothèque libapreq
Fig. 14 : Chaîne indiquant que le code utilise la bibliothèque libapreq
Libapreq étant une bibliothèque Apache open source, nous n'avions (presque) aucune raison de rechercher des vulnérabilités dans le code décompressé au lieu du code source. La première chose à faire était donc de trouver la version de la bibliothèque. Après quelques allers-retours, nous avons pu affiner la version en trouvant une chaîne dans le code binaire et dans un enregistrement spécifique, mais celle-ci est supprimée dans l'enregistrement qui suit (Figure 15).
 Fig. 15 : Comparaison entre le code binaire décompilé et l'enregistrement du code source supprimant la chaîne
Fig. 15 : Comparaison entre le code binaire décompilé et l'enregistrement du code source supprimant la chaîne
Le point surprenant est que la bibliothèque présente dans le fichier binaire est la plus ancienne version disponible depuis mars 2000 (Figure 16).
 Fig. 16 : Version simplifiée de la bibliothèque libapreq
Fig. 16 : Version simplifiée de la bibliothèque libapreq
Vulnérabilités
Fortinet utilise le module presque exactement comme il y a 25 ans, sauf pour des modifications très mineures à des fins d'optimisation. Lorsque nous avons vu cela pour la première fois, nous avons pensé qu'il n'y avait aucune chance que le code de la version de 2000 ne présente aucune vulnérabilité. Et nous avons eu raison !
Avant d'examiner les vulnérabilités, voyons l'objectif et l'utilisation de la bibliothèque. Apreq est une bibliothèque Apache utilisée pour gérer les données de demande client. Les formulaires HTML constituent un moyen courant de recevoir des données d'un utilisateur. Les données de formulaire indiquées peuvent être transmises au serveur à l'aide de différentes méthodes d'encodage, mais les méthodes courantes sont application/x-www-form-urlencoded et multipart/form-data.
Lorsque multipart/form-data est utilisé, le client (généralement le navigateur) choisit un texte arbitraire en tant que limite entre différents champs des données du formulaire. La limite est spécifiée via un en-tête HTTP. Elle est également utilisée pour indiquer la fin des données du formulaire (Figure 17).
POST /foo HTTP/1.1
Content-Length: 68137
Content-Type: multipart/form-data; boundary=ExampleBoundaryString
--ExampleBoundaryString
Content-Disposition: form-data; name="description"
Description input value
--ExampleBoundaryString
Content-Disposition: form-data; name="myFile"; filename="foo.txt"
Content-Type: text/plain
[content of the file foo.txt chosen by the user]
--ExampleBoundaryString--
Figure 17 : Exemple de formulaire de limite HTTP (Source)
Examinons maintenant certaines vulnérabilités que nous avons identifiées, notamment l'écriture hors limites (OOB) de l'octet NULL, la copie générique, les terminaux DoS, les serveurs Web DoS et la lecture OOB.
Écriture OOB de l'octet NULL
Lorsque multipart_buffer_read remplit le tampon interne et recherche la limite, il renvoie la chaîne entre la position actuelle et la limite trouvée. Un bug survient si la limite n'est pas au début du tampon interne : la chaîne est renvoyée après la suppression des deux derniers caractères censés être la fin de la ligne (« \r\n »). Le code suppose à tort que la longueur de la chaîne renvoyée est supérieure à 2.
Dans la Figure 18, retval est la chaîne de caractères renvoyée et start est sa longueur, qui équivaut à 1. Dans ce cas, blen est également égal à start. Il est ensuite diminué de deux par rapport à la valeur -1. Nous avons donc la possibilité d'écrire NULL un octet avant le tampon.
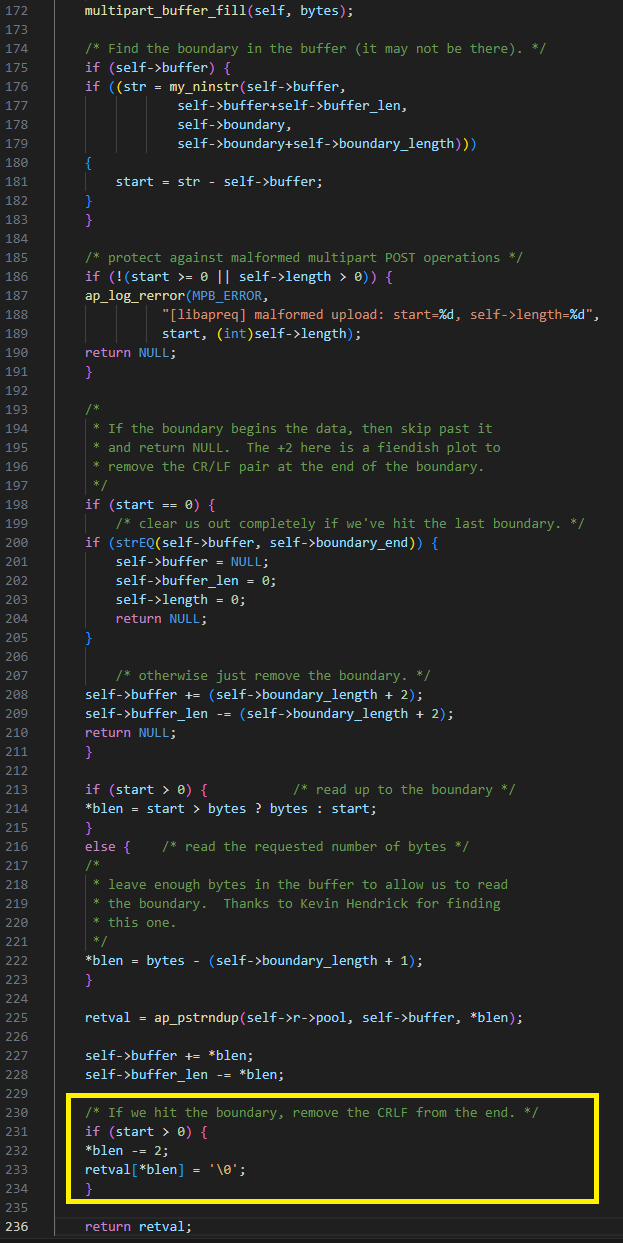 Fig. 18 : La vulnérabilité entraînant une écriture hors limites de NULL avant le tampon
Fig. 18 : La vulnérabilité entraînant une écriture hors limites de NULL avant le tampon
Tentatives d'exploitation
Bien que le dépassement d'un octet (ou même le dépassement d'un bit) puisse suffire pour exécuter le code, nous pensons que cette vulnérabilité est peu susceptible d'être exploitée dans la pratique. Tout d'abord, nous ne pouvons écrire qu'un octet NULL, et un seul octet, avant la mémoire tampon. La mémoire tampon est allouée sur le segment de mémoire ; il existe donc deux options :
1. Le tampon est le premier à être alloué dans le nœud du tas. Dans ce cas, les métadonnées du nœud du tas figurerons avant notre allocation (Figure 19).
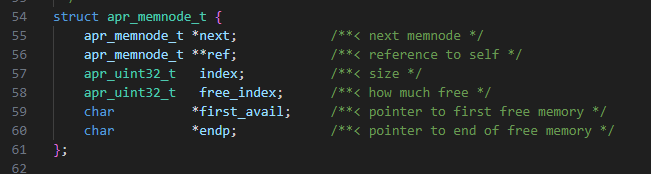 Fig. 19 : Structure représentant un nœud de segment de mémoire Apache
Fig. 19 : Structure représentant un nœud de segment de mémoire Apache
Nous allons remplacer un octet du pointeur endp. Cela n'aurait pas d'impact sur la valeur du pointeur, car nous écrasons l'octet le plus élevé du pointeur en raison de son boutisme. Étant donné que la VM est x64, cet octet sera toujours 0.
2. Si une allocation a été effectuée avant nous, nous pourrons écraser un octet de données. Malheureusement, comme dans l'exemple précédent, dans la plupart des cas, nous aurons soit un pointeur à la fin de la structure, soit du remplissage, soit une chaîne C déjà terminée par une écriture NULL.
Nous avons trouvé un objet intéressant : la structure C de multipart_buffer (Figure 20).
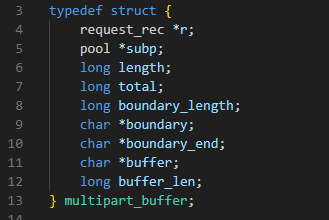 Fig. 20 : La structure C de multipart_buffer
Fig. 20 : La structure C de multipart_buffer
Dans ce cas, nous avons pensé que buffer_len, la dernière variable de la structure, pourrait être négative par rapport à la vulnérabilité précédente, puis que nous pourrions la remplacer par une valeur positive importante avec cette vulnérabilité (en écrasant l'octet MSB marquant le nombre comme négatif).
Même si cette approche semblait intéressante, il y a deux problèmes :
1. La structure n'est créée qu'une seule fois, lors de la création de l'analyseur de formulaires. Cela signifie que nous ne pourrions pas vaporiser cet objet facilement.
2. Après avoir utilisé la vulnérabilité précédente, nous avons limité la longueur de la lecture dans la fonction de remplissage. Cela signifie que lorsque la fonction de remplissage se termine, self->length est égal à 0 après avoir lu les données POST complètes de la demande. La prochaine fois que le code appellerait multipart_buffer_read, il ne trouverait pas la limite dans le tampon avancé (puisque nous avons fait apparaître le pointeur de fin avant son début) et comme self->length est égal à 0, une alerte de téléchargement incorrect surviendrait.
Nous avons envisagé d'essayer de l'exploiter face à des concurrences critiques, mais en examinant le mode de multitraitement Apache (MPM), nous voyons ce qui est présenté à la Figure 21.
 Fig. 21 : Vérification du mode MPM Apache
Fig. 21 : Vérification du mode MPM Apache
Cela signifie qu'Apache forge plusieurs processus qui traitent chacun une demande. Nous pouvons également remarquer que ces processus ne sont pas multithread. Cela signifie que nous ne serons pas en mesure de l'exploiter face à des concurrences critiques.
Texte générique
Dans la même fonction multipart_buffer_read, si le code ne trouve pas la limite (start est égal à -1), il renvoie uniquement une partie du tampon interne : (octets - boundary_length). Une erreur survient, car les octets sont définis sur la valeur constante 5120, alors que la longueur limite peut être beaucoup plus grande (jusqu'à la limite de la longueur de l'en-tête).
Par conséquent, en envoyant un champ dans lequel la limite ne se trouve pas dans le premier bloc avec une longueur de limite supérieure à 5120, nous pouvons générer un blen négatif. Cela conduit à l'apparition du code définissant self->buffer avant le tampon, et self->buffer_len recevant une valeur plus grande (Figure 22).
 Fig. 22 : La vulnérabilité due à un sous-flux d'entiers
Fig. 22 : La vulnérabilité due à un sous-flux d'entiers
Tentatives d'exploitation
Il existe une différence entre cette vulnérabilité et la précédente : cette fois-ci, comme start est négatif (et que la limite n'a pas été trouvée), nous n'avons pas accès au code écrivant un octet NULL.
blen est un paramètre de la fonction multipart_buffer_read. Observons donc la fonction multipart_buffer_read_body qui l'appelle et reçoit blen en tant que sortie.
La Figure 23 montre que le blen est utilisé deux fois :
1. S'il s'agit du premier tampon créé, la chaîne reçue depuis multipart_buffer_read est dupliquée à l'aide de blen. Dans ce cas, Apache génère une erreur de mémoire insuffisante (OOM) et le code est annulé. Il peut être utilisé pour lancer une attaque DoS.
2. S'il s'agit du deuxième segment, le segment précédent et l'actuel sont joints à l'aide de la fonction my_join. La fonction appelle memcpy avec un nombre négatif, ce qui entraîne la création de texte générique.
 Fig. 23 : Les deux flux différents dans multipart_buffer_read_body
Fig. 23 : Les deux flux différents dans multipart_buffer_read_body
(Certains d'entre vous aurez peut-être constaté un autre bug dans ce code ; à savoir que old_len est mis à jour pour afficher blen au lieu de old_len + blen, ce qui entraîne la troncature des données des utilisateurs.)
L'exploitation d'un tel texte générique serait très difficile ou presque impossible. Tout d'abord, nous n'avons pas la possibilité d'arrêter le texte générique : il s'agit d'une mémoire memcpy de grande taille. Deuxièmement, il n'y a pas de multithreading, donc nous ne pouvons pas remplacer un objet qui sera utilisé dans un autre thread en parallèle. Nous supposons que la seule option possible est d'exploiter le gestionnaire de signaux s'il n'effectue pas de sortie sécurisée.
Terminal DoS
Cette vulnérabilité ne se trouve pas dans la bibliothèque elle-même, mais dans le code de Fortinet qui utilise la bibliothèque.
Lorsque l'utilisateur charge un fichier via le formulaire, et que ce fichier est spécifié avec un en-tête Content-Disposition dans les données POST (voir Figure 17), un nouveau fichier est créé dans le dossier /tmp/ avec un nom de fichier prenant la forme /tmp/uploadXXXXXX, où les X sont des caractères aléatoires.
Pour chaque téléchargement de fichier, une structure appropriée est créée et insérée dans une liste liée de fichiers téléchargés. La faute apparaît à la fin de l'analyse, lorsque seul le fichier se trouvant dans le premier nœud de la liste associée est supprimé. Cela permet à un attaquant de lancer une attaque en remplissant le dossier /tmp/. Étant donné que /tmp/ est un système de fichiers tmpfs, les données sont stockées sur la RAM. Cela entraîne une panne complète du système et provoque le blocage du terminal.
Seul le redémarrage du terminal permet de rétablir son usage normal, et même cela n'est pas garanti. Dans l'une de nos tentatives, nous avons provoqué une sorte de bloc réseau sur le terminal : même après le redémarrage du terminal, la fonctionnalité réseau ne fonctionnait pas correctement et nous n'avons pas pu l'utiliser ni nous y connecter.
Tentatives d'exploitation
Cette vulnérabilité est assez facile à exploiter. Il suffit d'envoyer plusieurs fois des demandes avec un formulaire contenant plusieurs fichiers. Après un court instant, le terminal est bloqué (Figure 24).
 Fig. 24 : Remplissage de la RAM du dispositif VPN avec des fichiers non supprimés, permettant finalement d'atteindre le DoS en raison d'une mémoire insuffisante
Fig. 24 : Remplissage de la RAM du dispositif VPN avec des fichiers non supprimés, permettant finalement d'atteindre le DoS en raison d'une mémoire insuffisante
Serveur Web DoS
Il s'agit d'une vulnérabilité mineure dans la fonction multipart_buffer_headers. Elle appelle multipart_buffer_fill qui remplit le tampon interne, puis elle recherche une ligne double se terminant dans le tampon interne.
Le bug est que le code ne vérifie pas la validité du tampon interne après avoir appelé multipart_buffer_fill. Si le client interrompt la connexion alors que multipart_buffer_fill attendait une entrée, il définit le tampon sur NULL et cela entraîne un déréférencement NULL (Figure 25).
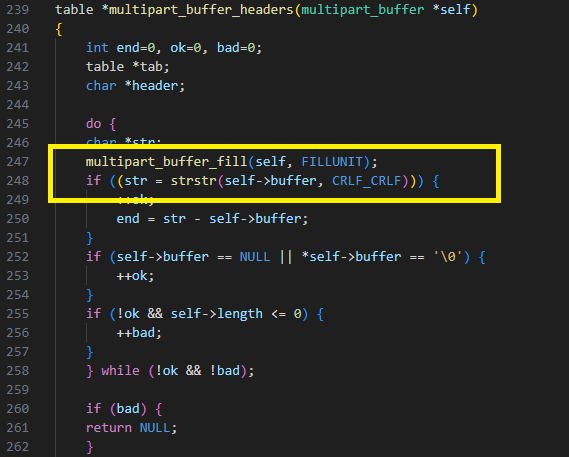 Fig. 25 : Accès au tampon interne sans vérifier s'il est valide
Fig. 25 : Accès au tampon interne sans vérifier s'il est valide
Tentatives d'exploitation
Cette vulnérabilité est également assez facile à exploiter. Un attaquant peut créer plusieurs threads qui créent une connexion et envoient la requête de panne. Comme le module MPM Apache Pre-Fork ne fournit pas d'excellentes performances, le serveur ne sera pas en mesure de gérer les différentes pannes et ne sera pas en mesure de servir d'autres clients pendant l'attaque.
Lecture OOB
La bibliothèque utilise un tampon interne qui est rempli régulièrement. Lorsqu'il est rempli, le calcul du nombre d'octets à lire est le suivant :
1. Calculer (bytes_requested - current_internal_buffer_len)
2. Ajouter une longueur limite + 2 (pour « r\n\r\n »)
3. Calculer le minimum entre ce résultat et les octets disponibles à lire à partir des données POST
La vulnérabilité se trouve dans multipart_buffer_read. Si elle a trouvé la limite au début du tampon interne et qu'il ne s'agit pas de la limite marquant la fin du formulaire, elle fait avancer le pointeur du tampon interne au-delà de la limite et ajoute 2 octets supplémentaires à la fin de la ligne.
L'erreur illustrée ici montre qu'un pirate peut faire en sorte que le tampon interne ait exactement la taille de la limite, ce qui fait avancer le code de deux octets au-delà de la fin du tampon interne (Figure 26). Cela peut survenir, car nous pouvons « limiter » le calcul du tampon interne en fournissant une quantité d'octets inférieure à celle de boundary_length + bytes_requested.
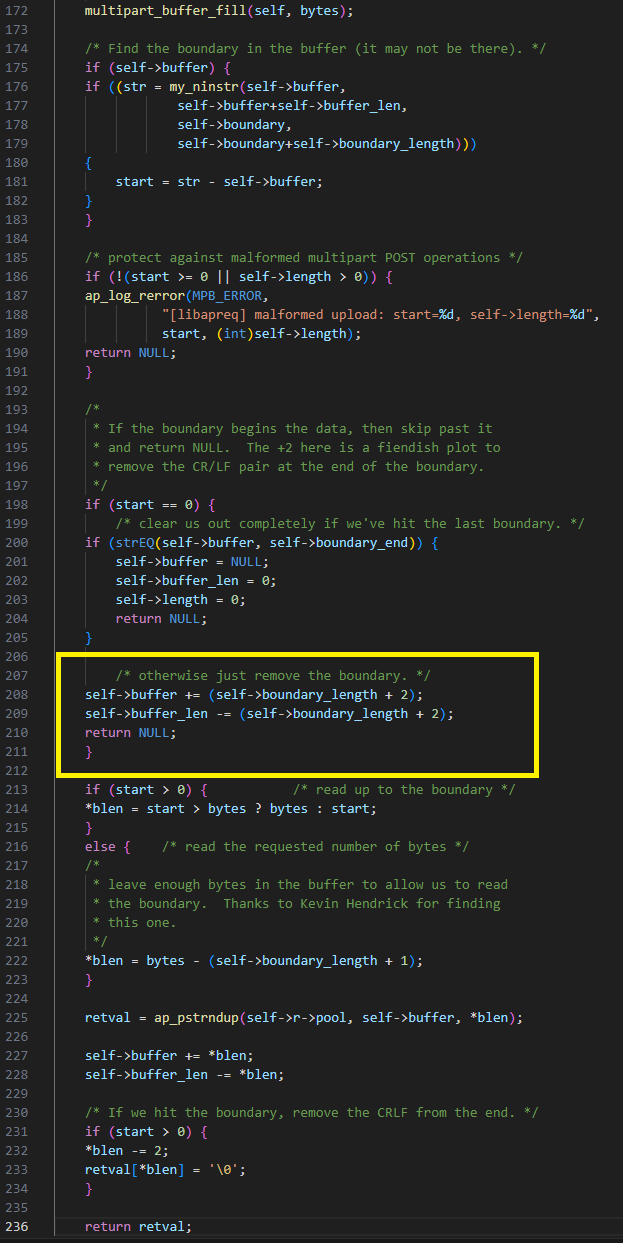 Fig. 26 : Avancer le tampon interne au-delà de sa fin
Fig. 26 : Avancer le tampon interne au-delà de sa fin
Tentatives d'exploitation
Comme illustré à la Figure 26, le code renvoie NULL. Pourtant, comme nous l'avons vu dans le bug précédent, le code dans multipart_buffer_headers accède directement au tampon interne, et non à la valeur renvoyée. Le code recherche alors l'élément « \r\n » après le tampon et le renvoie en tant qu'en-tête.
Lors de l'utilisation d'apreq dans le gestionnaire de connexion, le code lit les champs du formulaire, mais il ne les renvoie pas au client. La vulnérabilité OOB ne peut donc pas être utilisée en tant que fuite d'informations dans ce cas. La bibliothèque est également utilisée plusieurs fois dans le serveur Web, mais il semble que ces bibliothèques ne soient disponibles que pour les utilisateurs authentifiés. Par conséquent, la plupart des pirates disposant d'identifiants utilisateur à faible privilège peuvent l'utiliser comme vulnérabilité d'élévation des privilèges en lisant les identifiants utilisateur à privilège élevé depuis la mémoire.
SSLVPND
SSLVPND est le démon responsable de la gestion du composant SSL-VPN de Fortinet. Il est accessible à Internet. La bibliothèque apreq est également utilisée dans SSLVPND. Elle est basée sur la même ancienne version d'apreq, avec quelques modifications. Toutes les vulnérabilités décrites ci-dessus, à l'exception de la vulnérabilité Device DoS, existent également dans SSLVPND.
Malheureusement, nous n'avons pas pu déclencher la bibliothèque apreq dans SSLVPND. Nous ne sommes donc pas en mesure de confirmer si ces vulnérabilités sont accessibles aux utilisateurs non authentifiés ou si ces vulnérabilités peuvent être exploitables dans le contexte de SSLVPND.
Synthèse
Les attaquants ciblent souvent les VPN en raison de leur nature accessible sur Internet. Dans cet article de blog, nous avons examiné un exemple d'approche pour la recherche d'un dispositif VPN. Bien qu'aucune vulnérabilité critique n'ait été identifiée, nous pensons qu'il est raisonnable de supposer que d'autres vulnérabilités attendent d'être découvertes.
Les VPN étant une passerelle vers le réseau de l'entreprise, les vulnérabilités de ces dispositifs ont un impact majeur sur les entreprises. Nous espérons que cet article de blog encouragera également d'autres chercheurs en sécurité à rechercher les vulnérabilités du VPN.