
What’s That Scraping Sound? How Web Scraper Bots Erode Ecommerce Profits


For ecommerce organizations, bots are like insects in a garden: Some are beneficial, but others are destructive pests. Bots can bring traffic to your site, redirect traffic to their own fake site, or execute other nefarious schemes like credential stuffing.
Recently, one particular species of bot has grabbed the attention of ecommerce organizations: web scraper bots. Their ability to evade detection enables these bots to secretly scrape away at their victims’ bottom lines.
What is a scraper bot?
As their name suggests, these bots crawl in and scrape all the publicly accessible data and content — think images, product details, pricing information, and inventory availability information — from a website.
This content can be leveraged in a variety of ways. It can be used for competitive analysis, for example, including product prices, discounts, inventory, and product SKU numbers, categories, and descriptions. The legitimate site may also be duplicated as part of a phishing or brand impersonation campaign to undercut prices that take business to the competition.
Less threatening web scrapers can still diminish website performance and drive up compute and server costs by flooding the site with GET requests. Whatever their purpose, scraper bots can decrease revenue, increase IT costs, and erode the customer experience — leaving you at a competitive disadvantage.
We explored this phenomenon — and what ecommerce organizations can do to protect themselves — in a new State of the Internet (SOTI) report, Scraping Away Your Bottom Line: How Web Scrapers Impact Ecommerce.
Headless browsers: An evasive threat
What makes web scraper bots different — and so concerning — is that their true economic impacts are often hidden beneath the surface. Detecting these types of malicious bots is difficult, due in part to their use of headless browsers (i.e., browsers that lack a graphical user interface, often used for testing — and scraping — websites). This makes them extremely evasive.
Leading use cases that impact commerce
Our research has also identified examples of web scraper bots that are used to perpetrate a variety of unwanted activities, including:
counterfeit site creation
inventory hoarding
intelligence gathering
Counterfeit site creation
Hospitality businesses are a prime target for scraper bots, which grab content and set up fake reservation sites to steal credit card numbers and other personally identifiable information.
Inventory hoarding
Another use case is inventory hoarding, in which scalpers ping targeted sites repeatedly looking for products to become available. Then they add the products to shopping carts, which makes them unavailable to legitimate customers, often during the holiday season when online shopping peaks and every dollar counts.
This technique may also impact search, as other retailers appear in results because the item is “out of stock” on the scalped site. This not only robs the seller of revenue and harms their search ranking, but is a deterrent to legitimate customers, who may decide to shop elsewhere in the future.
Intelligence gathering
Web scraper bots are also used to gather competitive intelligence, such as pricing and special offers data that enables a retailer to undercut their rival. A variety of third-party web scraping tools and services have popped up to facilitate this information gathering.
There are even dedicated conferences —- like ScrapeCon — during which attendees share best practices and techniques to evade anti-bot mitigation technologies. Although web scraping of public content is not inherently illegal, many use third-party tools to later commit malicious acts.
AI raises the scraping stakes
As with other types of threats, scraper bots powered by artificial intelligence (AI) raise the stakes for organizations that are looking to stop them. AI bots not only collect data, but also extract and process that data.
This enables the bot to efficiently recognize essential information, which streamlines the process of cherry-picking information on prices, discounts, inventory, and product SKU numbers, categories, and descriptions. This can be used to supercharge competitive intel or scalping campaigns.
The value of specialized detection
There is good news for ecommerce organizations that are concerned about web scraping. Bot management solutions that are designed to specifically detect and stop scraper bots have been shown to significantly reduce high-risk bot traffic and improve business outcomes.
Recently, Akamai researchers studied one week of traffic for a set of ecommerce companies. They analyzed 6.9 billion requests to identify and characterize them (Figure 1). Here’s what they found:
49.3% of requests were from human users
42.1% were from bots (8.7% were mixed or unclassified)
65.3% of bot traffic was from scrapers classified as bad bots
34.7% of bot traffic was from scrapers classified as good bots
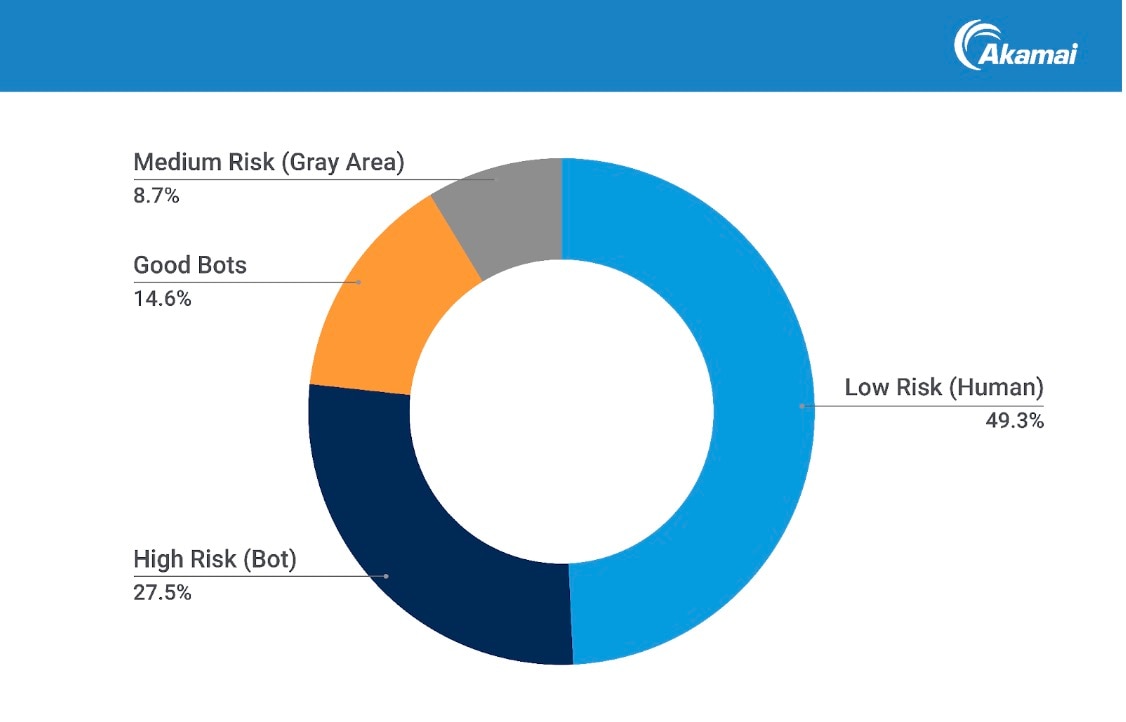 Fig. 1: Traffic activity classification breakdown
Fig. 1: Traffic activity classification breakdown
Mitigating the bad bots
Differentiating good from bad bot traffic enabled targeted mitigation. Once activated, mitigation with Akamai Content Protector resulted in a dramatic reduction in high-risk bot requests, lowering malicious activity substantially (Figure 2).
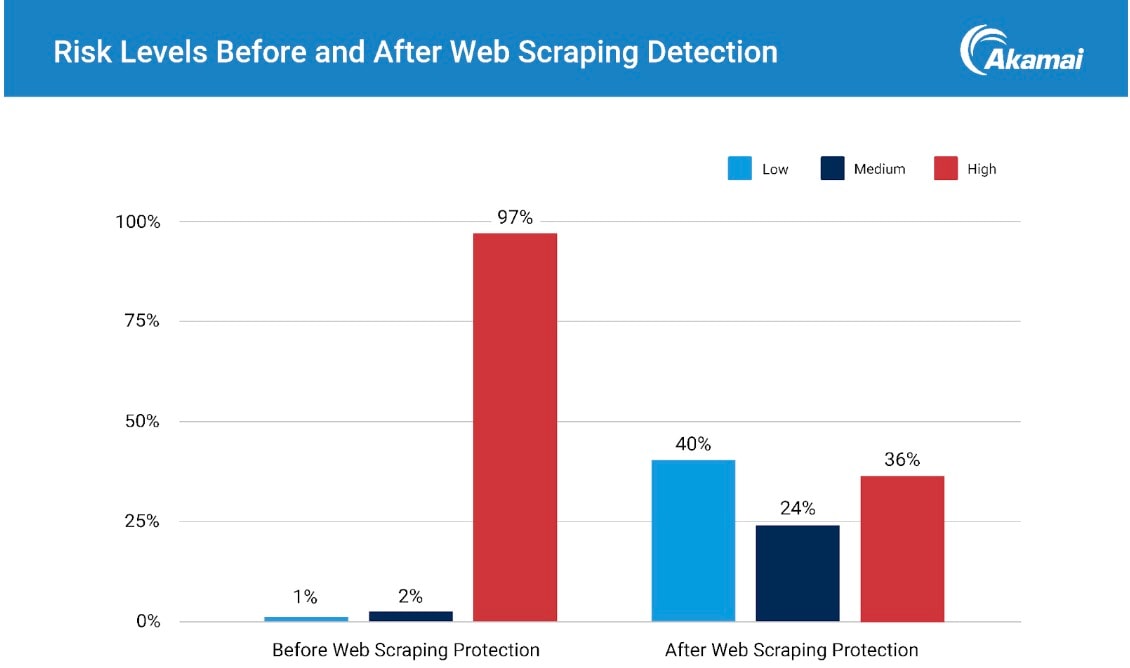 Fig. 2: Risk levels before and after mitigation with Akamai Content Protector
Fig. 2: Risk levels before and after mitigation with Akamai Content Protector
Improving business outcomes
Web scraper mitigation resulted in a lower risk of malicious activity, and also significantly reduced the traffic that was consuming website resources. The reduction of high-risk traffic leads to a variety of improved business outcomes, such as improved site performance, higher conversion rates, more accurate site metrics, and reduced IT costs. Having accurate metrics on beneficial traffic also enables companies to make better investment decisions to drive revenue growth.
Stemming the tide of web scraper bots
Bot herders are clever and their tactics are constantly advancing. Detecting and mitigating bad web scraper bots demands tools and expertise as sophisticated as the bots themselves. Working with a partner that has these capabilities can be invaluable in stemming the tide of bad web scraper bots.
The bot landscape is continually evolving and posing new security challenges to ecommerce organizations. Understanding the threat of web scraping is a critical first step toward protecting your business from fraud losses — and toward ensuring your ecommerce business is healthy, productive, and pest-free.
Learn more
Get the full story: Download the new State of the Internet (SOTI) report, Scraping Away Your Bottom Line: How Web Scrapers Impact Ecommerce.
