
The Web Scraping Problem: Part 1


What is web scraping?
A ton of information and data is available online. Digital commerce and travel sites enable shoppers to browse their entire catalog 24/7; media sites offer thousands of articles on different topics; and social media platforms provide on-demand insight into individuals, their interests, and their opinions.
This represents a huge source of information that can be exploited and monetized. But before it can be exploited, it must be harvested — and there’s no better way to harvest information than by using a botnet. Botnets that collect information that’s freely available on the internet are called scrapers.
Web scraping is a complex problem. While some scraping activity is essential to a website's success, it can be challenging to determine the value of other activities — and the intention of the entity initiating the scraping.
In this three-part blog series, we’ll quantify the bot traffic on the internet, then discuss the different aspects of web scraping and how they affect various industries. Finally, we’ll review the characteristics of botnets and show you how to manage them effectively.
Three ways web scrapers affect websites
Scraping activity may target product detail pages, prices, or inventory (or all of these) and affect targeted websites in at least three ways.
Web scraping can sometimes be poorly calibrated and cause performance, stability, and availability issues for targeted websites. The perceived distributed denial of service (DDoS) can lead to revenue loss.
Scraping activity affects site metrics. One metric that website owners monitor closely is conversion rate, or the ratio of the total number of purchases to the total number of pages visited. Excess scraping traffic will significantly skew the data and reduce a company's visibility into the effectiveness of its marketing and product positioning strategies.
Scraping may also result in long-term revenue loss if the extracted intelligence is used to design a successful marketing campaign to hijack the audience from the targeted site.
How much internet traffic is driven by web scraping?
Of all use cases involving bots, web scraping represents the highest traffic volume by far. That’s why quantifying scraping activity helps us assess how much internet traffic comes from bots.
Depending on who you ask, the bot-to-overall traffic ratio will vary. In truth, nobody has precise numbers because nobody can monitor the entire internet and run bot detection on it. Even if they could, detection would not be 100% accurate despite the web security industry’s best efforts.
Bot activity comes and goes. Today’s web scraping traffic may not be the same as tomorrow’s. However, since Akamai carries up to 30% of internet traffic and is developing the next generation of scraper detection, we’re very well positioned to provide the most relevant statistics.
To look into the web scraping ratio question, we took a one-week traffic snapshot from a representative sample of customers who have been evaluating our new scraper detection technology over the last few months. This includes global fashion brands, major US retailers, international airlines, and hotel chains. The sample used for the study consists of 1.16 billion HTML pages and API requests. Requests for static content such as images, style sheets, JavaScript, videos, and fonts were ignored.
From the study, one fact became apparent: The level of bot activity a site may receive largely depends on the popularity of the brand’s products or services and their ranking in the market. Figure 1 shows an example of a sportswear brand catering to the US market. Only 17.7% of the traffic on their product pages comes from real humans, and more than 82.3% comes from bots. Of that 82.3%, only a small portion comes from good bots, such as web search engines, SEO, and social media. The rest comes from scrapers.
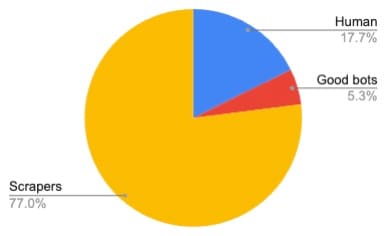 Fig. 1: Traffic distribution for a US sportswear company
Fig. 1: Traffic distribution for a US sportswear company
In contrast, Figure 2 shows the traffic distribution for a retailer selling auto parts online with a mild bot problem. In this case, just over 15% of the traffic comes from bots, two-thirds of which comes from good bots.
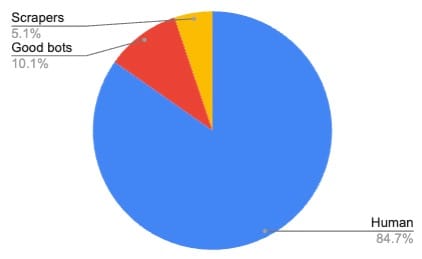 Fig. 2: Traffic distribution for an auto part retailer in the United States
Fig. 2: Traffic distribution for an auto part retailer in the United States
Figure 3 shows a home improvement company catering to the US market, where the distribution between scraper, human, and good bots is more evenly distributed. Yet, overall, bot activity accounts for 60% of the total traffic to the product pages.
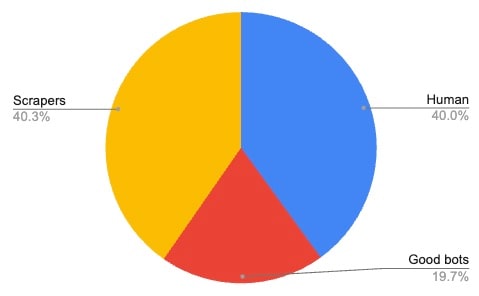 Fig. 3: Traffic distribution for a US home improvement company
Fig. 3: Traffic distribution for a US home improvement company
Looking at all the sampled customers, the average bot-to-human traffic ratio is about 70:30, as seen in Figure 4. The sample used for the study is not large enough to conclude that 70% of the internet consists of bot traffic, but we can safely conclude that the great majority of traffic on the internet originates from bots.
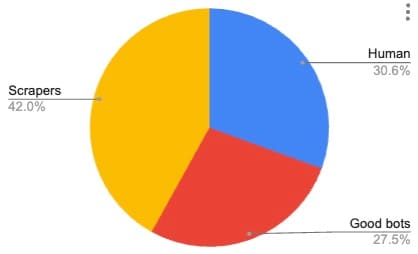 Fig. 4: Average website traffic distribution
Fig. 4: Average website traffic distribution
The impact of web scraping by industry
When a botnet scrapes a website, it’s harvesting publicly available information. The botnet operators regularly trigger scraping activity to collect their desired information, including product details, pricing, and inventory. Web scraping is a nuisance and violates most website’s acceptable use policies (AUPs). But is it illegal?
As with many legal issues, the answer is “it depends.” There are few recent legal regulations on this issue. Additionally, scraping activity may come from countries (or even US states) with different regulations from those in the country where the site is hosted, leading to difficulties in enforcing the AUP or in determining what legal regulation applies. Lastly, although the scraping activity can be detected, bot operators are masters of hiding their tracks, making it challenging to attribute the activity to any particular person or entity for prosecution.
Within web scraping, there are different use cases; depending on the context, not all have a negative impact. Ecommerce, travel, hospitality, and media are the most affected. Figure 5 shows the consequences of scraping based on industry and intent.
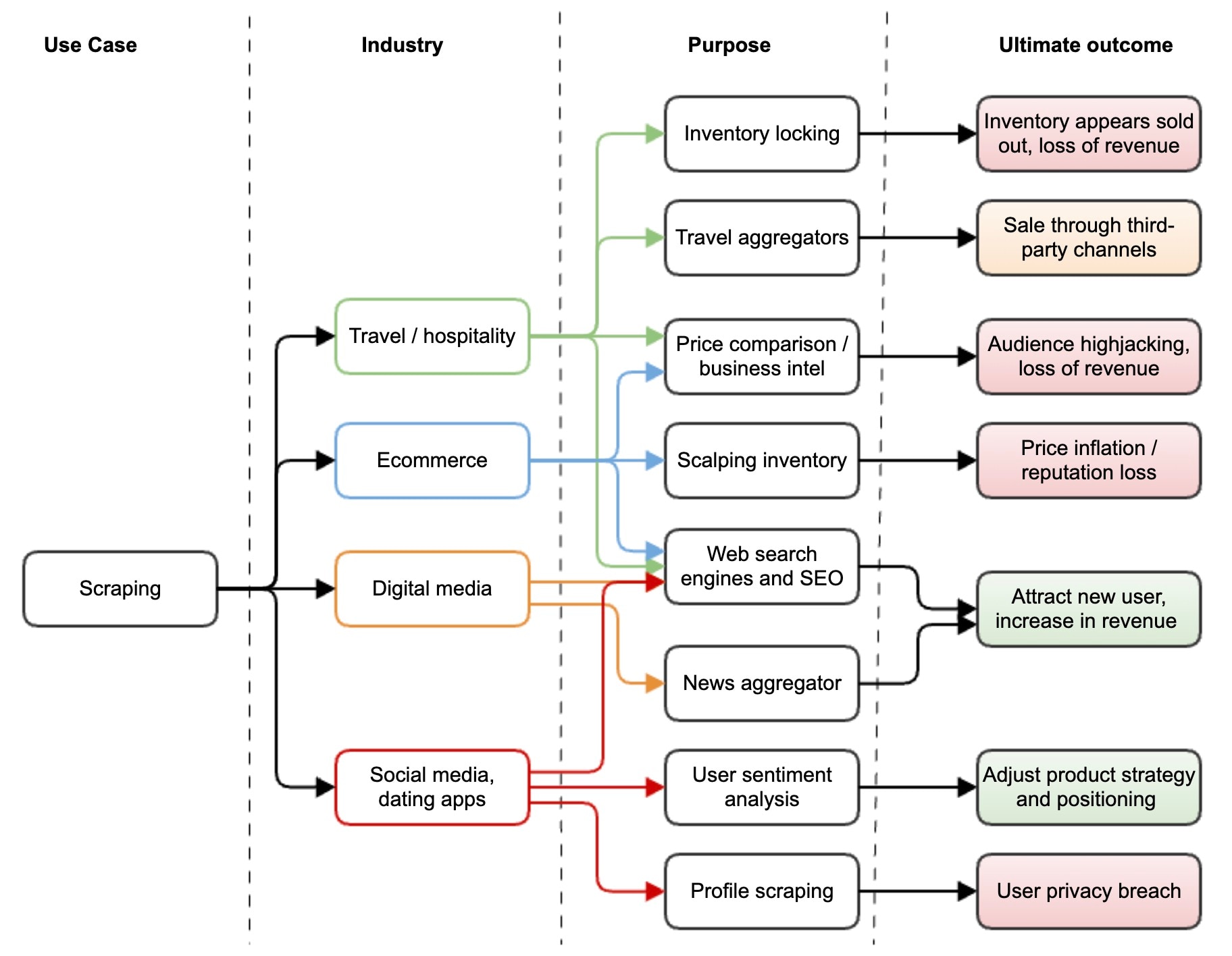 Fig. 5: The outcome of web scraping activity by industry
Fig. 5: The outcome of web scraping activity by industry
All industries share a common need to serve their content to web search engines, SEO, or social media bots that scrape their sites to ensure content is visible and attracts customers. Site monitoring services also regularly pull content from the site to evaluate response times and availability across the globe.
Traffic coming from these so-called known bots, like Googlebot or Bingbot, must be accurately identified to prevent serving content to impersonators. In general, most website owners would like to avoid scraping activity that’s difficult to attribute to any specific entity.
Travel and hospitality
Travel aggregators and booking engines scrape travel and hospitality websites. These sites allow travelers to easily find flights, hotel rooms, car rentals, and even entertainment at their destination. Booking engines may sell their own products or services on top of the consumer’s airfare or accommodations.
To make the content readily available to the account aggregator, the airline or hotel may make the data accessible through APIs or allow the aggregator to scrape their site. There is typically a mutually beneficial agreement in place between the two parties.
However, some airlines or hotel brands may only want to be associated with their specific booking engine partners. Aggregators sometimes scrape these sites directly, advertise, and resell the airfares or hotel rooms without the brand’s consent, which violates the AUP. Depending on the website's architecture, scraping activity may lock the airfare or room inventory for a few minutes, making it unavailable to legitimate users.
Ecommerce
Ecommerce sites receive a significant amount of activity from bot operators that scrape a site in search of items for sale during an event — an activity commonly referred to as scalping. This activity is usually punctual and sporadic.
The web scraping activity behind most traffic usually comes from entities harvesting data to extract business intelligence. This can be initiated by well-funded companies that specialize in data extraction or individual companies that want to monitor their competition. In any case, a company generally uses the data to define its marketing and product strategy.
Digital media
Digital media websites want to attract as many users as possible who may be interested in the content they produce. News outlets generally welcome scraping activity from new aggregators or larger news organizations to potentially have their content referenced, which increases their visibility. More readers or viewers translate into more subscriptions, ad impressions, and revenue.
For premium media services like The Wall Street Journal, content may only be available to paid subscribers. Although it’s essential that web search engines or social media bots be able to index and reference the content behind a paywall, these good bots must be identified to ensure the full content is safe from scrapers that attempt to impersonate legitimate bots like Googlebot and Facebook.
Social media
Consumers have long used social media like X (formerly Twitter), Instagram, and Facebook to share their opinions. These platforms have become a huge source of information that marketers can use to infer user sentiment toward products, companies, and even social issues.
Companies that specialize in business intelligence and product marketing also scrape social media sites to collect and process data through complex machine learning algorithms, extracting valuable insights that they can use to optimize product strategy. Social media sites may sell that data or restrict scraping activity.
Social media and dating sites hold a trove of personal data about individual users, making user profile scraping a major privacy concern. While a company searching on LinkedIn for professionals to hire is entirely acceptable and in line with the site's purpose, it is unacceptable for a company or individual to scrape all profiles to build a personal information database that could later be sold for profit.
Shield yourself from malicious scraping activity
Botnets can be complex and unpredictable. No matter your industry or background, it’s wise to protect your data from web scrapers — and drive better, more productive traffic in the process.
Akamai Content Protector can help. As the next generation of scraper protection, it’s built to detect and mitigate most scraping activity, even as attack strategies evolve. It’s also been tested by major online brands, including those with major web scraping challenges.
In today’s fast-paced cyber landscape, the right tools are more important than ever. With Akamai, you get just that — along with the confidence you need to thrive over the long term.
