
Supresión del sonido: encadenamiento de vulnerabilidades para la ejecución remota de código en Outlook: parte 2


Introducción
Utilizando la vulnerabilidad descrita en la parte 1 de esta serie del blog, nuevamente tenemos la capacidad de reproducir un archivo de sonido personalizado en el destino, haciendo un uso indebido de la función de sonido de recordatorio de Outlook. Para aprovechar esta capacidad y transformarla en una ejecución remota de código (RCE) completa, empezamos a buscar vulnerabilidades en el análisis de archivos de sonido en Windows.
Superficies de ataque
El archivo de sonido que va a reproducir Outlook tiene el formato Waveform Audio File (WAV). Se reproduce a través de la función PlaySound , que recibe la ruta del archivo de sonido. PlaySound va a cargar el archivo, analizarlo y, a continuación, llamar a soundOpen , que llamará a las diferentes funciones de onda, como waveOutOpen.
Los archivos WAV actúan como un contenedor (o envoltorio) para varios códecs de audio. Un códec es un programa o código que codifica o descodifica un flujo de datos (como imagen, vídeo o audio). Normalmente, el códec será la codificación de modulación por impulsos codificados (PCM), que es una forma sencilla de representar señales analógicas para muestras.
Existen tres superficies de ataque principales en las que podemos buscar vulnerabilidades:
Análisis del formato WAV
Administrador de compresión de audio
Códecs de audio diferentes
Análisis del formato WAV
El análisis del formato WAV se implementa dentro de la función soundInitWavHdr en winmm.dll (la biblioteca que implementa la API multimedia de Windows). La superficie de ataque presentada no es grande y parece que ha sido revisada; no hemos encontrado ninguna vulnerabilidad en ella.
¿Qué es el administrador de compresión de audio?
El administrador de compresión de audio (ACM) es el código responsable de gestionar los casos en los que el códec que se utiliza en el archivo WAV no emplea una codificación PCM simple y, por lo tanto, lo debe descodificar un descodificador personalizado. Estos decodificadores se implementan en archivos con la extensión .acm. Un ejemplo popular es el códec MP3, que se implementa en l3codeca.acm. Cada códec lo gestiona un controlador (que no es igual que el controlador del modo kernel, pero similar en su función), el cual se registra a través del ACM.
Cuando se necesita una transformación, como la transformación de MP3 a PCM o viceversa, el ACM entra en acción y gestiona esta transformación. Cuando utilizamos un archivo WAV en el que no se utiliza PCM, se consultará al ACM para averiguar si existe el códec especificado en el propio archivo y puede gestionar la transformación (Figura 1).
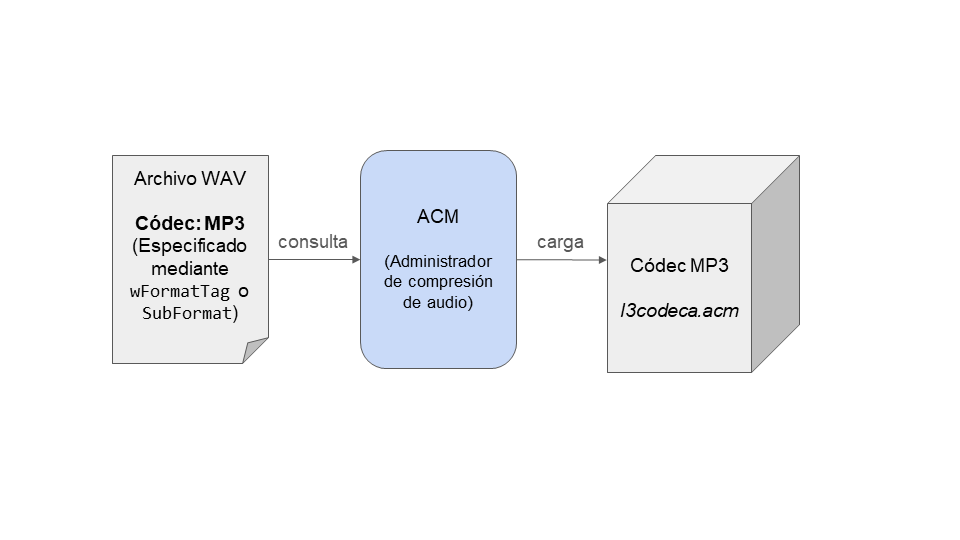
Cada controlador de ACM debe implementar funciones como acmdStreamSize y acmdStreamOpen. El primero devuelve el tamaño (en bytes) necesario para la salida de la transformación; el segundo crea una estructura de flujo y define los campos adecuados, como la función de devolución de llamada de descodificación.
La superficie de ataque de ACM no es tan grande. Sin embargo, hemos logrado detectar una vulnerabilidad en ese código, como veremos más adelante en esta entrada de blog.
Códecs de audio diferentes
Para la última superficie de ataque, tenemos diferentes códecs de audio instalados de forma predeterminada. El códec se especifica en el archivo WAV de dos formas diferentes:
wFormatTag en el fragmento FORMAT
Si wFormatTag es WAVE_FORMAT_EXTENSIBLE, SubFormat contendrá el GUID del códec de audio.
La lista de códecs disponibles se describe en el Apéndice.
Conceptos básicos del procesamiento de señales de audio
Antes de profundizar en el código, vamos a familiarizarnos con algunos de los conceptos básicos del procesamiento de señales de audio. Si ya conoce estos conceptos, no dude en pasar directamente a la siguiente sección.
Cuando oímos un sonido, lo que realmente oímos es la vibración que se propaga a través de un medio de transmisión. El sonido es la recepción de esas ondas vibratorias tal y como las captan nuestros oídos y las percibe nuestro cerebro.
Una señal de audio es una onda continua. Para procesarla digitalmente, necesitamos convertirla de una señal analógica a una digital (por ejemplo, utilizando un convertidor ADC). Esta conversión es la discretización de la señal analógica. Para ello, muestreamos la señal analógica varias veces en puntos de datos espaciados de manera uniforme (denominados muestras). Esta tasa de muestreo (también conocida como frecuencia de muestreo) determina cuántas muestras se toman por segundo. Las tasas de muestreo más altas capturan más detalles, pero también requieren más almacenamiento y procesamiento.
Además de la tasa de muestreo, tenemos el tamaño de muestra, que indica cuántos bits se utilizan para cada muestra. También en este caso, cuanto mayor sea el tamaño de la muestra, mejor será la calidad de la muestra (o más cercana al sonido original). Los tamaños de las muestras suelen ser de 16 bits o 24 bits por muestra.
Los códecs de audio se basan en modelos psicoacústicos. La psicoacústica es el estudio científico de la percepción del sonido y la audiología: cómo percibe el sistema auditivo humano los diversos sonidos. Por ejemplo, el umbral de audición humano está entre 20 Hz y 20 000 Hz. Por ello, para reducir aún más el tamaño del archivo, los códecs de audio pueden eliminar las frecuencias que no pueden escuchar los humanos. Además, el códec de audio puede eliminar las señales si su volumen no es lo suficientemente fuerte como para que el oído humano lo perciba. Por ejemplo, un sonido de 20 Hz no se oye si es inferior a 60 decibelios.
Hay muchos más ejemplos de modelos psicoacústicos; por ejemplo, el enmascaramiento de señales silenciosas cuando son cercanas en frecuencia o tiempo a una señal fuerte.
El análisis, la interpretación y la modificación de las señales se realizan utilizando bancos de filtros, que dividen la señal en subbandas (distintas bandas de componentes que permiten un examen y manipulación más detallados de partes específicas de la señal). Los bancos de filtros más utilizados son los bancos de filtros polifásicos y DCT.
Teniendo en cuenta este conocimiento básico, podemos profundizar en la investigación de diferentes códecs.
Primer intento: escritura fuera de límites en el búfer de muestras
En primer lugar, intentamos observar el MP3, ya que en comparación con otros códecs, el MP3 es mucho más complejo. La mayoría de los códecs restantes solo realizan conversiones algo simples, mientras que el MP3 tiene varios pasos durante su proceso de descodificación (Figura 2).
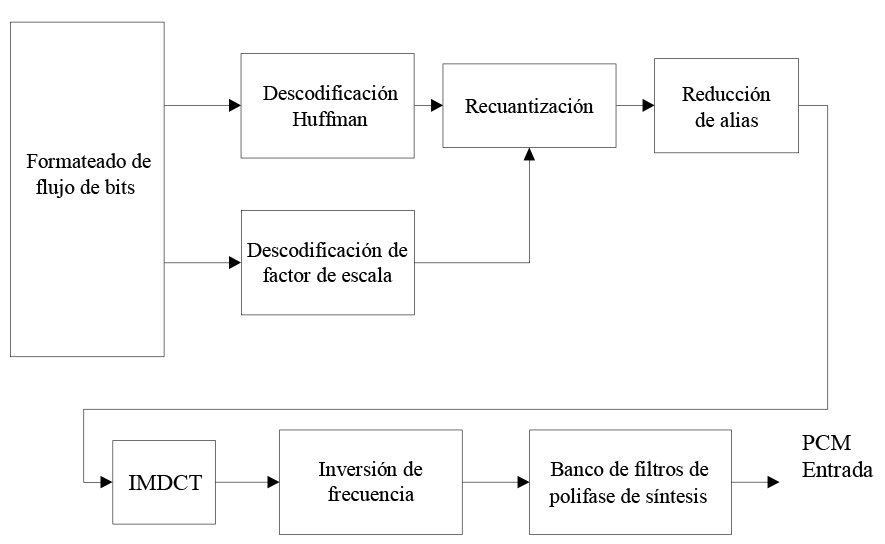
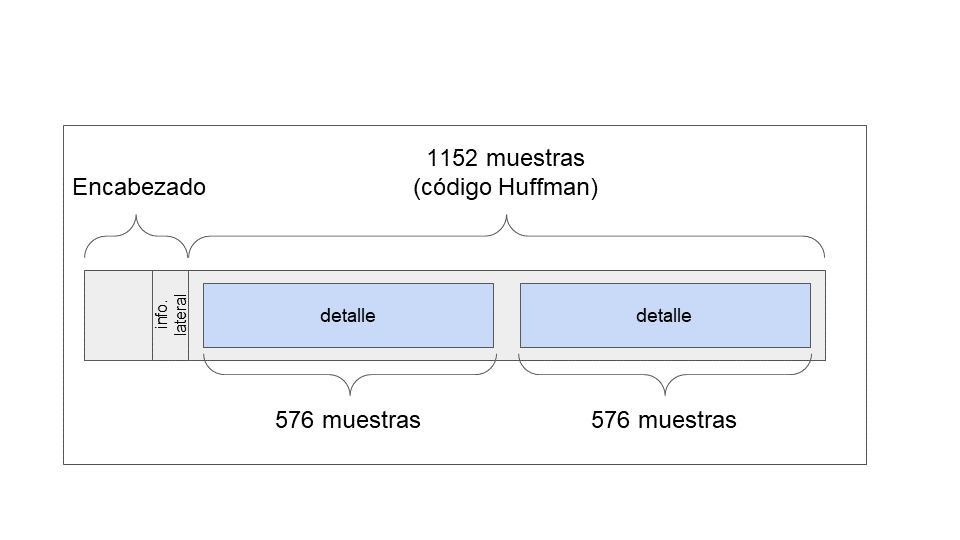
Los datos de audio MP3 se organizan en una serie de frames, cada uno de los cuales representa un pequeño segmento de audio. Un frame consta de un encabezado y los datos de audio. Los datos de audio se comprimen mediante la codificación Huffman. Cada frame representa exactamente 1152 muestras del dominio de la frecuencia por canal (mono/estéreo). Este se divide en dos fragmentos denominados gránulos, cada uno de 576 muestras. Cada frame también contiene información relacionada con su descodificación, denominada información complementaria (Figura 3).
La mayoría de las operaciones realizadas como parte del proceso de descodificación MP3 son complejas y, aunque en teoría podrían ser un lugar interesante (y excelente) para buscar vulnerabilidades sutiles, en la práctica muchas de las operaciones (como el DCT modificado, el banco de filtros polifásicos y la reducción de alias) se llevan a cabo en un búfer que guarda constantemente los valores de 576 muestras. Por ello, encontrar aquí una vulnerabilidad de escritura fuera de límites no es plausible. Un lugar interesante es la descodificación Huffman, ya que funciona naturalmente con datos más dinámicos (a diferencia del búfer de 576 muestras).
Descodificación Huffman de MP3
La codificación Huffman de un gránulo (576 muestras) se implementa mediante tablas de código (en lugar de un árbol binario). El rango de frecuencia total de 0 a 22 050 (frecuencia de Nyquist) se divide en cinco regiones (Figura 4):
1., 2. y 3. Tres regiones de "big values" (valores grandes): muestras cuyo valor está comprendido entre -8206 y 8206
4. "count1 region": cuádruples de valores -1, 0 o 1
5. "rzero region": se supone que los valores de frecuencia más altos tienen amplitudes bajas y, por lo tanto, no es necesario codificarlos; estos valores son iguales a 0.
 Fig. 4: Partición de las líneas de frecuencia de la muestra 576 en las diferentes regiones [http://www.mp3-tech.org/programmer/docs/mp3_theory.pdf]
Fig. 4: Partición de las líneas de frecuencia de la muestra 576 en las diferentes regiones [http://www.mp3-tech.org/programmer/docs/mp3_theory.pdf]
Cada región tiene sus propias tablas Huffman (excepto la región 0), por lo que las muestras de diferentes frecuencias se codifican de forma diferente.
La clasificación de las muestras en regiones se basa en las siguientes variables:
big_values: especifica cuántas muestras totales hay en la región de valores grandes
region0_count y region1_count: particiona los big_values en subregiones; al restarle su suma a big_values se obtiene el número de muestras de region2.
Part2_3length: especifica cuántos bits se utilizan para los factores de escala (parte 2) y cuántos para la codificación Huffman (parte 3)
El proceso de descodificación de las 576 muestras tiene lugar de la siguiente manera:
Descodificación de las muestras de la región big_values
Descodificación de las muestras de la región count1
Si el número de bits procesados es mayor que part2_3length, prácticamente hemos descodificado todos los datos de entrada, e incluso se han vuelto a leer los datos, por lo tanto, se resta 4 de total_samples_read (es decir, se desechan estos bits de entrada)
Si quedan muestras, se rellenan con 0 (esto crea la región 0)
Esta lógica de la Tabla 1 se muestra como pseudocódigo.
total_samples_read = 0;
// Decode big_values region
[redacted for brevity]
// Decode count1 region [1]
for (int i = 0; i < count1; i++) {
samples[total_samples_read++] = huff_decode(bitstream, count1_huff_table);
}
if (bits_processed > part2_3length) [2] {
// Overread. Throw last 4 samples
total_samples_read -= 4;
}
// Fill rzero region with zeros
for (int i = total_samples_read; i < 576; i++) {
samples[total_samples_read++] = 0; [3]
}
Tabla 1: Pseudocódigo de la lógica de descodificación Huffman
Desafortunadamente, el código no tiene un caso específico de borde, lo que causa un subdesbordamiento de enteros.
El tamaño de la región de valores grandes es 0
El tamaño de la región count1 es 0
Part2_3length es 0
Bits_processed es superior a 0
En este caso específico, bits_processed va a ser mayor que part2_3length (alcanza un valor distinto de cero antes del proceso de descodificación durante la descodificación de los factores de escala). Por lo tanto, el código va a “lanzar” las cuatro últimas muestras. Dado que el código no ha procesado ninguna muestra, total_samples_read es 0. Aquí vamos a tener un subdesbordamiento, y el código piensa que hemos procesado -4 muestras. A continuación, va a rellenar la región 0 de la siguiente manera:
Define el puntero del búfer en &samples[total_samples_read]. Esto apunta a 16 bytes antes del búfer de muestras.
Define el tamaño de escritura como 576 - total_samples_read = 576 - (-4) = 580 enteros.
Por lo tanto, tenemos una escritura fuera de límites justo antes del búfer de muestras con el valor cero. ¡Excelente!
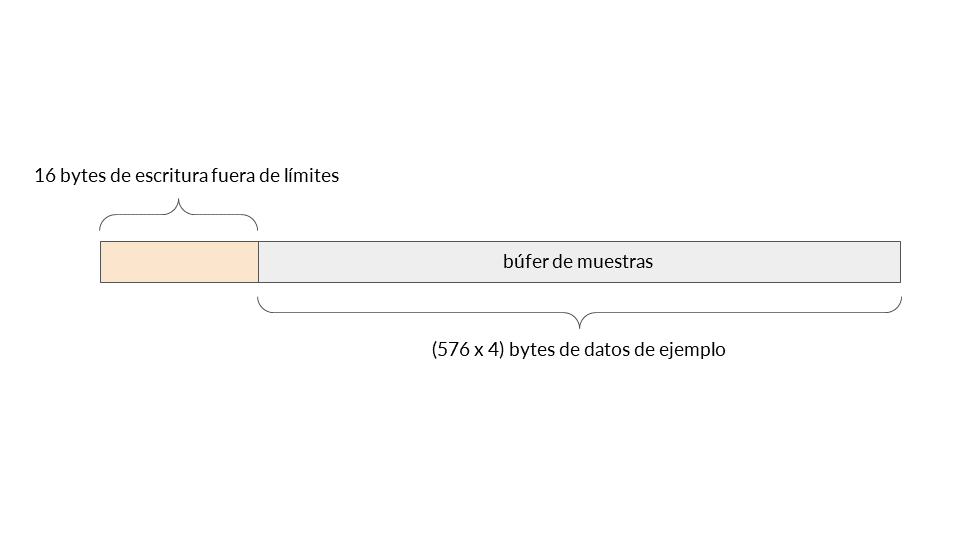
Entonces, ¿por qué no ha recibido esta vulnerabilidad una CVE? El búfer de muestras forma parte de una estructura, y el campo situado justo antes del búfer de muestras es la matriz de factor de escala. Se trata de una matriz con campos que ya controlamos, y por lo tanto no tiene realmente un impacto interesante aquí.
La misma vulnerabilidad se produce también después de que el código haya descuantizado las muestras. Nuevamente, rellena la región 0, esta vez con el búfer descuantizado. ¿Adivina qué hay antes del búfer descuantizado? El búfer de muestras con descodificación Huffman. Es el mismo búfer de muestras que hemos visto previamente y sobre el que también tenemos control. Por lo que, de nuevo, no tenemos un impacto real.
Esas escrituras fuera de límites siguen existiendo en el descodificador MP3 (accesibles a través de WAV y de los archivos .mp3) y, según Microsoft se pueden corregir en el futuro. Aunque no se ha encontrado ninguna vulnerabilidad que tenga algún impacto durante la inversión del códec, creemos que puede haber vulnerabilidades que se ocultan en las diferentes operaciones complejas que lleva a cabo el descodificador.
Segundo intento: desbordamiento de enteros en el códec IMA ADPCM
Nuestro siguiente intento será el códec IMA ADPCM, que se implementa en imaadp32.acm. Como ya sabemos, el ACM va a gestionar las transformaciones desde y entre diferentes códecs. Para registrar un códec, el código debe implementar funciones de ACM. Una de estas funciones es acmStreamSize, que devuelve el número de bytes necesarios para el búfer de destino.
El códec IMA ADPCM calcula el tamaño del búfer de destino en función del tamaño de la carga útil de entrada (cbSrcLength), la alineación (nBlockAlign) y las muestras por bloque (wSamplesPerBlock; Tabla 2).
(cbSrcLength / pwfxSrc->nBlockAlign) *(pwfxSrc->wSamplesPerBlock * pwfxDst->nBlockAlign)
Tabla 2: Cálculo del tamaño del búfer
Antes de la multiplicación, el código se asegura de que el cálculo no producirá un desbordamiento de enteros (Tabla 3).
SrcNumberOfBlocks = cbSrcLength / pwfxSrc->WaveFormat.nBlockAlign;
v14 = pwfxSrc->wSamplesPerBlock * pwfxDst->nBlockAlign;
if ( 0xFFFFFFFF / v14 < SrcNumberOfBlocks )
return ERROR_OVERFLOW;
IsThereRemainder = cbSrcLength % pwfxSrc->WaveFormat.nBlockAlign;
if ( IsThereRemainder )
++SrcNumberOfBlocks;
DstBufferLengthInBytes = v14 * SrcNumberOfBlocks;
Tabla 3: Comprobación de cálculo para evitar el desbordamiento de enteros
Aparentemente, esta comprobación no es suficiente para evitar un desbordamiento. Si hay un resto en la división de cbSrcLength / pwfxSrc->nBlockAlign, el código incrementa el resultado de (cbSrcLength / pwfxSrc->nBlockAlign), que se utiliza en la multiplicación. La comprobación de desbordamiento no cubre este incremento. Como resultado, podemos desbordar la longitud del búfer de destino especificando valores personalizados.
Tenemos que proporcionar cbSrcLength que tiene un resto cuando se divide por pwfxSrc->nBlockAlign.
En la Tabla 4 se muestra un ejemplo de valores que dan lugar a un desbordamiento de enteros.
cbSrcLength = 0x71c71c72
pwfxSrc->nBlockAlign = 8
pwfxSrc->wSamplesPerBlock = 9
pwfxDst->nBlockAlign = 2
Tabla 4: Ejemplo de valores que dan lugar a un desbordamiento de enteros
Esto da como resultado un búfer de destino de 0xE bytes, cuando el búfer de destino debería ser mucho mayor.
Aunque esto parece un desbordamiento de enteros que puede dar lugar a una escritura fuera de límites, la función de descodificación se asegura correctamente de que no se produzcan escrituras después del búfer asignado y no asume que el búfer ha asignado con el tamaño correcto.
De ese modo, aunque proporcionemos varios ejemplos, en la práctica, cuando el búfer de destino está lleno, el código se detiene. El mismo comportamiento se produce en el códec AD PCM (implementado en msadp32.acm).
Tercer intento: desbordamiento de enteros en ACM (CVE-2023-36710)
Por último, encontramos una gran vulnerabilidad en el código ACM. Como parte del proceso de reproducción de un archivo WAV, se llama a la función mapWavePrepareHeader del gestor ACM (implementado en msacm32.drv).
Esta función presenta una vulnerabilidad de desbordamiento de enteros. Llama a acmStreamSize, que llama a la devolución de llamada del controlador. Recuerde que esta función devuelve el tamaño necesario para el búfer de destino. Después de recibir este tamaño, mapWavePrepareHeader agrega 176 bytes (el tamaño del encabezado de flujo que seguirá al búfer de destino) sin comprobaciones de desbordamiento. El resultado de esta adición se transfiere a GlobalAlloc (Figura 6).
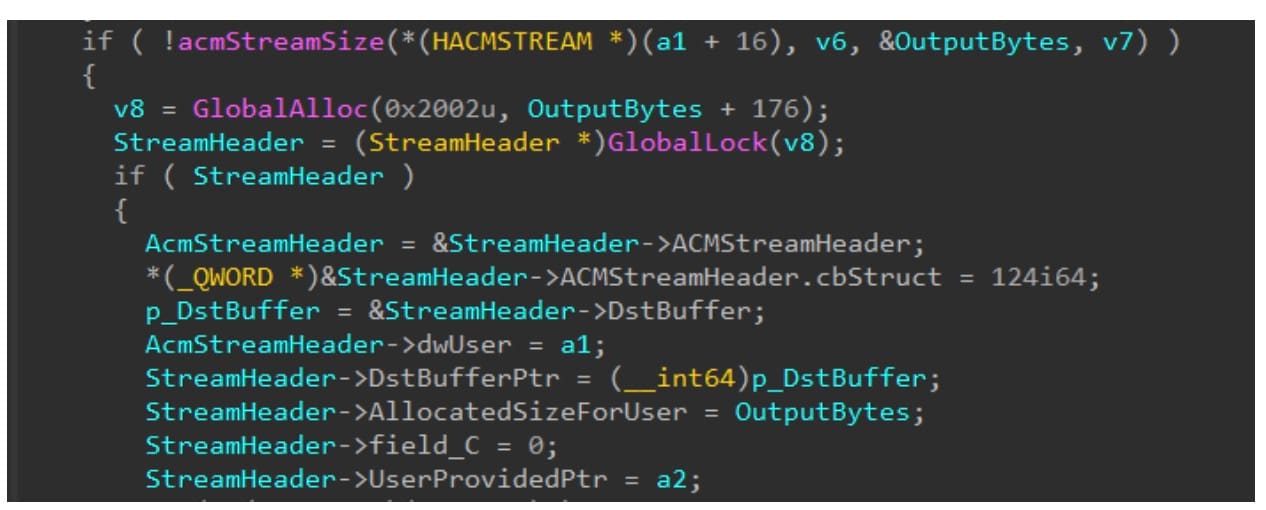 Fig. 6: Código vulnerable en mapWavePrepareHeader
Fig. 6: Código vulnerable en mapWavePrepareHeader
Se trata de un problema que se puede explotar. Podemos causar que GlobalAlloc asigne un búfer realmente pequeño en lugar de uno grande causando que acmStreamSize Devuelva un valor entre 0xffffffff50 y 0xffffffff. Después de esta asignación, podemos provocar dos escrituras fuera de límites:
Los valores de encabezado de flujo, como el tamaño de la estructura, el origen, y los punteros y tamaños del búfer de destino. Estos valores se pueden controlar parcialmente.
Los valores descodificados del códec. Estos valores están totalmente controlados.
Para activar la vulnerabilidad, necesitamos proporcionar una muestra WAV con un tamaño, cuando está descodificado, que sea mayor o igual que 0xffffff50. Aunque esto pueda parecer fácil de lograr, en nuestros intentos pudimos comprobar que no era posible en algunos códecs. Por ejemplo, con el códec MP3, como parte del cálculo hay una multiplicación por 1152 o 576 (que son el número de muestras por frame). El resultado de ese cálculo nunca estará en el rango que deseamos.
Por último, logramos activar la vulnerabilidad mediante el códec IMA ADP. El tamaño del archivo es de aproximadamente 1,8 GB. Al realizar la operación de límite matemático en el cálculo, podemos concluir que el tamaño de archivo más pequeño posible con el códec IMA ADP es de 1 GB.
La explotación de dicha vulnerabilidad se hace más fácil cuando hay un motor de scripts disponible para crear una explotación de forma dinámica. Dado que Windows Media Player no cuenta con uno, su explotación puede suponer un mayor desafío. Todavía podría ser posible (como demuestra Chris Evans en su entrada de blog "Advancing exploitation: a scriptless 0day exploit against Linux desktops« [Adelantándose a la explotación: explotación de día cero sin script en escritorios Linux]). No obstante, hay más posibilidades de que esta vulnerabilidad se explote con éxito en el contexto de la aplicación Outlook (u otras aplicaciones de mensajería instantánea).
Resumen
En esta serie del blog se ha tratado una investigación que se inició con una vulnerabilidad explotada en el mundo real. (Lea la Parte 1, si aún no lo ha hecho). El proceso de investigación continuó con la búsqueda de omisiones y, finalmente, detectó una vulnerabilidad complementaria a la que encadenarla para lograr una cadena de RCE sin clic. Aunque estas vulnerabilidades se han corregido, los atacantes siguen buscando superficies de ataque y vulnerabilidades similares que se puedan explotar de forma remota.
A día de hoy, la superficie de ataque de Outlook que hemos investigado sigue existiendo, y se pueden encontrar y explotar nuevas vulnerabilidades. Aunque Microsoft ha aplicado parches en Exchange para que elimine los correos electrónicos que contengan la propiedad PidLidReminderFileParameter, no podemos descartar la posibilidad de que se omita esta mitigación.
Apéndice
En este sitio se enumeran todos los tipos de medios y códecs disponibles en Media Foundation de Microsoft.
Nuestras pruebas indican que en la práctica solo están disponibles los siguientes códecs a través de WAV:
1 — PCM
2 — ADPCM
6 — A-LAW
7 — U-LAW
11 — IMA ADPCM
31 — GSM 6.10
55 — MPEG-1 Audio Layer III (MP3)
00000003_0000_0010_8000_00aa00389b71 — IEEE Float
00000008-0000-0010-8000-00aa00389b71 — DTS Audio
00000092-0000-0010-8000-00aa00389b71 — Dolby Digital
00000164-0000-0010-8000-00aa00389b71 — Microsoft WMA
