
Disattivazione dell'audio: concatenamento delle vulnerabilità per ottenere RCE su Outlook: Parte 2


Introduzione
Utilizzando la vulnerabilità che abbiamo descritto nella parte 1 di questa serie di blog, abbiamo ancora una volta la possibilità di riprodurre un file audio personalizzato sulla destinazione, sfruttando la funzionalità audio di promemoria di Outlook Per sfruttare questa possibilità e trasformarla in un'esecuzione di codice remoto (RCE) completa, abbiamo iniziato a cercare le vulnerabilità nell'analisi dei file audio su Windows.
Superfici di attacco
Il file audio che verrà riprodotto da Outlook è in formato WAV (Waveform Audio File). Viene riprodotto tramite la funzione PlaySound , che riceve il percorso del file audio. PlaySound caricherà il file, lo analizzerà e quindi chiamerà soundOpen che chiamerà le diverse funzioni Wave, ad esempio waveOutOpen.
I file WAV fungono da container (o contenitore) per più codec audio. Un codec è un programma o un codice che codifica o decodifica un flusso di dati (come immagini, video o audio). Di solito, il codec sarà la codifica PCM che rappresenta un modo semplice per rappresentare segnali analogici campionati.
Esistono tre principali superfici di attacco in cui possiamo cercare le vulnerabilità:
analisi del formato WAV
Audio Compression Manager
diversi codec audio
analisi del formato WAV
L'analisi del formato WAV è implementata all'interno della funzione soundInitWavHdr in winmm.dll (la libreria che implementa l'API multimediale di Windows). La superficie d'attacco lì presente non è ampia e sembra essere stata rivista; non è stata riscontrata alcuna vulnerabilità.
Che cos'è Audio Compression Manager?
Audio Compression Manager (ACM) è il codice responsabile della gestione dei casi in cui il codec utilizzato nel file WAV non utilizza una semplice codifica PCM e quindi deve essere decodificato da un decoder personalizzato. Questi decoder sono implementati in file con estensione .acm. Un esempio diffuso è il codec MP3, implementato in l3codeca.acm. Ogni codec è gestito da un driver (che non è uguale a un driver in modalità kernel, ma simile nella funzione), registrato tramite ACM.
Ogni volta che è necessaria una conversione, ad esempio convertire MP3 in PCM o viceversa, l'ACM entra in azione e gestisce questa conversione. Quando utilizziamo un file WAV in cui non viene utilizzato PCM, verrà interrogato l'ACM per verificare se il codec specificato nel file stesso esiste e può gestire la conversione (Figura 1).

Ogni driver ACM deve implementare funzioni quali acmdStreamSize e acmdStreamOpen. Il primo restituisce la dimensione (in byte) necessaria per l'output della conversione; il secondo crea una struttura del flusso e imposta i campi appropriati, come la funzione di callback di decodifica.
La superficie di attacco di ACM non è molto ampia. Tuttavia, siamo riusciti a trovare una vulnerabilità in quel codice, come mostreremo più avanti in questo post del blog.
diversi codec audio
Per l'ultima superficie di attacco, abbiamo diversi codec audio installati per impostazione predefinita. Il codec viene specificato nel file WAV utilizzando due modi diversi:
wFormatTag nella parte FORMAT
Se wFormatTag è WAVE_FORMAT_EXTENSIBLE, SubFormat manterrà il GUID per il codec audio.
L'elenco dei codec disponibili è descritto nell' Appendice.
Nozioni fondamentali sull'elaborazione del segnale audio
Prima di esaminare il codice, acquisiamo familiarità con alcune nozioni fondamentali sull'elaborazione del segnale audio. Se avete già familiarità con questi concetti, non esitate a passare alla sezione successiva.
Quando sentiamo il suono, ciò che effettivamente sentiamo è una vibrazione che si propaga tramite un mezzo di trasmissione. Il suono è la ricezione di quelle onde di vibrazione captate dalle nostre orecchie e percepite dal nostro cervello.
Un segnale audio è una forma d'onda continua. Per elaborarlo digitalmente, dobbiamo convertirlo da un segnale analogico a un segnale digitale (ad esempio, utilizzando un convertitore ADC). Questa conversione è la "discretizzazione" del segnale analogico. Per farlo, campioniamo il segnale analogico più volte in punti dati equidistanti (chiamati campioni). La velocità di campionamento (nota anche come frequenza di campionamento) determina il numero di campioni prelevati al secondo. Frequenze di campionamento più elevate catturano più dettagli, ma richiedono anche una maggiore capacità di archiviazione ed elaborazione.
Oltre alla frequenza di campionamento, abbiamo la dimensione del campione, ovvero quanti bit vengono utilizzati per ciascun campione. Ancora una volta, maggiore è la dimensione del campione, migliore sarà la qualità (o più simile al suono originale) del campione. Le dimensioni dei campioni sono generalmente di 16 bit o 24 bit a campione.
I codec audio si basano su modelli psicoacustici. La psicoacustica è lo studio scientifico della percezione del suono e dell'audiologia, ovvero il modo in cui il sistema uditivo umano percepisce i vari suoni. Ad esempio, il campo uditivo umano è compreso tra 20 Hz e 20.000 Hz. Pertanto, per ridurre ulteriormente le dimensioni del file, i codec audio potrebbero eliminare le frequenze non udibili dagli esseri umani. Inoltre, il codec audio può eliminare i segnali se il loro volume non è abbastanza forte da poter essere udito dall'orecchio umano. Ad esempio, un suono a 20 Hz non verrà udito se è inferiore a 60 decibel.
Esistono molti altri esempi di modelli psicoacustici; ad esempio, il mascheramento di segnali silenziosi quando in caso di frequenza o tempo vicini a un segnale forte.
L'analisi, l'interpretazione e la modifica dei segnali vengono eseguite utilizzando banchi di filtri, che dividono il segnale in sottobande: bande distinte di componenti che consentono un esame e una manipolazione più dettagliati di porzioni specifiche del segnale. I banchi di filtri comunemente utilizzati sono i banchi di filtri DCT e polifase.
Con queste nozioni fondamentali, possiamo esaminare in modo approfondito la ricerca di diversi codec.
Primo tentativo: Scrittura fuori banda nel buffer dei campioni
Per prima cosa abbiamo provato a esaminare MP3, poiché rispetto agli altri codec, MP3 è molto più complesso. La maggior parte degli altri codec esegue solo conversioni piuttosto semplici, mentre MP3 prevede più passaggi durante il processo di decodifica (Figura 2).
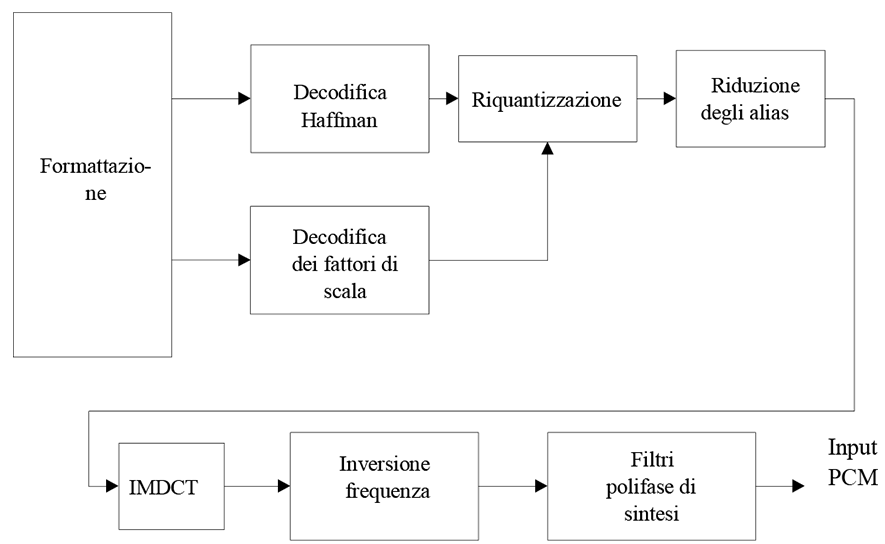
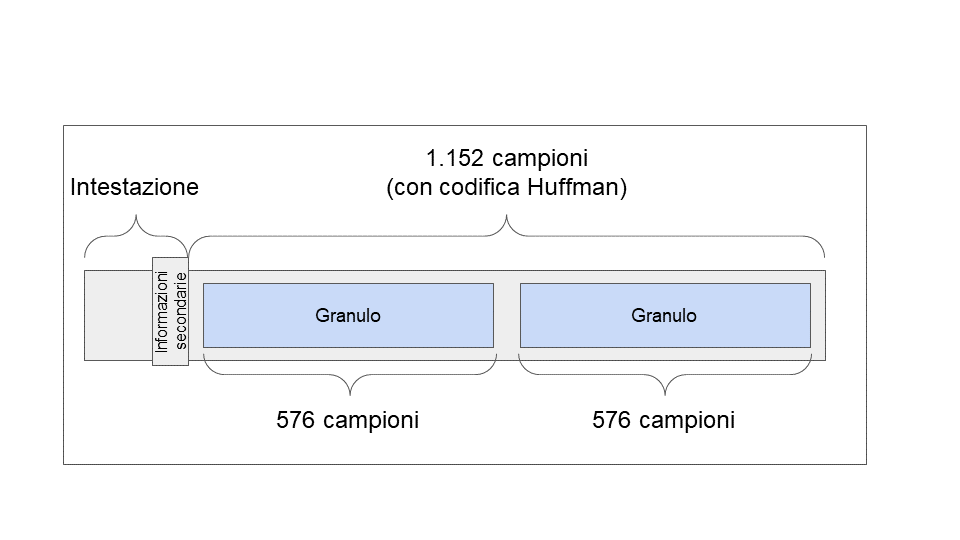
I dati audio MP3 sono organizzati in una serie di fotogrammi, ciascuno dei quali rappresenta un piccolo segmento di audio. Un fotogramma è costituito da un'intestazione e dai dati audio. I dati audio vengono compressi utilizzando la codifica Huffman. Ogni fotogramma rappresenta esattamente 1.152 campioni nel dominio della frequenza per canale (mono/stereo). Questo è suddiviso in due parti chiamate granuli, ciascuna di 576 campioni. Ogni fotogramma contiene anche informazioni relative alla sua decodifica, chiamate informazioni secondarie (Figura 3).
La maggior parte delle operazioni eseguite come parte del processo di decodifica MP3 sono complesse e, sebbene in teoria potrebbero essere un posto interessante (e attraente) in cui cercare vulnerabilità sottili, in pratica molte delle operazioni (come il DCT modificato, il banco di filtri polifase e la riduzione degli alias) viene eseguita su un buffer che mantiene costantemente i valori per 576 campioni. Pertanto, trovare una vulnerabilità di scrittura fuori qui non è plausibile. Un posto interessante è la decodifica Huffman, poiché naturalmente funziona su dati più dinamici (al contrario del buffer di 576 campioni).
Decodifica MP3 Huffman
La codifica Huffman di un granulo (576 campioni) viene implementata utilizzando tabelle di codici (invece di una struttura binaria). L'intervallo di frequenza totale da 0 a 22.050 (frequenza di Nyquist) è suddiviso in cinque regioni (Figura 4):
1., 2. e 3. Tre regioni di "valori elevati", ossia, campioni il cui valore è compreso tra -8.206 e 8.206
4. "regione count1": quadrupli dei valori -1, 0 o 1
5. "regione rzero": si presuppone che i valori di frequenza più elevati abbiano ampiezze basse e pertanto non è necessario codificarli; questi valori sono uguali a 0.
 Figura 4. La partizione delle 576 linee di frequenza del campione nelle diverse regioni [http://www.mp3-tech.org/programmer/docs/mp3_theory.pdf]
Figura 4. La partizione delle 576 linee di frequenza del campione nelle diverse regioni [http://www.mp3-tech.org/programmer/docs/mp3_theory.pdf]
Ogni regione ha le proprie tabelle di Huffman (ad eccezione della regione 0) e quindi i campioni di frequenze diverse sono codificati in modo diverso.
La classificazione dei campioni in regioni si basa sulle seguenti variabili:
big_values: specifica il numero totale di campioni presenti nella regione dei valori elevati
region0_count e region1_count: partiziona big_values in sottoregioni; sottraendo la loro somma da big_values si ottiene il numero di campioni nella regione 2.
part2_3length: specifica quanti bit vengono utilizzati per i fattori di scala (parte 2) e quanti per la codifica Huffman (parte 3)
Il processo di decodifica dei 576 campioni avviene come segue:
Decodifica dei campioni nella regione big_values
Decodifica dei campioni nella regione count1
Se il numero di bit elaborati è maggiore di part2_3length, abbiamo praticamente decodificato tutti i dati di input e persino i dati over-read: pertanto, sottraete 4 da total_samples_read (ovvero, scartate questi bit di input)
Se sono rimasti campioni, inserite uno 0 (questo forma la regione 0)
Questa logica nella Tabella 1 viene mostrata come pseudocodice.
total_samples_read = 0;
// Decode big_values region
[redacted for brevity]
// Decode count1 region [1]
for (int i = 0; i < count1; i++) {
samples[total_samples_read++] = huff_decode(bitstream, count1_huff_table);
}
if (bits_processed > part2_3length) [2] {
// Overread. Throw last 4 samples
total_samples_read -= 4;
}
// Fill rzero region with zeros
for (int i = total_samples_read; i < 576; i++) {
samples[total_samples_read++] = 0; [3]
}
Tabella 1: Pseudo-codice della logica di decodifica Huffman
Sfortunatamente, nel codice manca un caso limite specifico, e ciò comporta un underflow dei numeri interi.
La dimensione della regione dei valori elevati è 0
La dimensione della regione Count1 è 0
Part2_3length è 0
Bits_processed è maggiore di 0
In questo caso specifico, bits_processed sarà maggiore di part2_3length (raggiunge un valore diverso da zero prima del processo di decodifica durante la decodifica dei fattori di scala). Pertanto, il codice "scartare" gli ultimi quattro campioni. Poiché il codice non ha elaborato alcun campione, total_samples_read è 0. Qui si verificherà un underflow e il codice considera che abbiamo elaborato -4 campioni. Per cui riempirà la regione 0 come segue:
Imposta il puntatore del buffer su &samples[total_samples_read]. Questo punta a 16 byte prima buffer dei campioni.
Impostate la dimensione di scrittura come 576 - total_samples_read = 576 - (-4) = 580 numeri interi.
Pertanto, abbiamo una scrittura fuori banda immediatamente prima del buffer dei campioni con il valore zero. Bene!
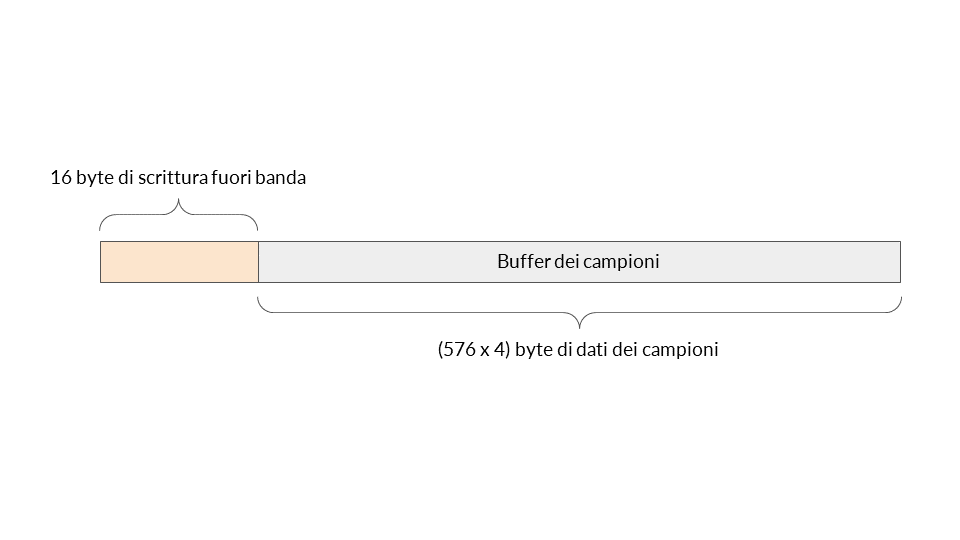
Allora perché a questa vulnerabilità non è stata assegnata una CVE? Il buffer dei campioni fa parte di una struttura e il campo subito prima del buffer dei campioni è l'array del fattore di scala. Questo è un array con campi che già controlliamo e quindi non vi è un impatto davvero interessante qui.
La stessa vulnerabilità si verifica anche dopo che il codice ha dequantizzato i campioni. Riempie ancora una volta la regione 0, questa volta con il buffer dequantizzato. Volete sapere cosa c'è prima del buffer dequantizzato? Il buffer dei campioni decodificati da Huffman. Questo è lo stesso buffer di campioni che abbiamo descritto in precedenza, sul quale abbiamo anche il controllo. Quindi, ancora una volta, non c'è un impatto reale.
Queste scritture fuori banda esistono ancora nel decoder MP3 (accessibili sia tramite WAV che tramite file .mp3) e secondo Microsoft potrebbero essere risolte in futuro. Sebbene non sia stata rilevata alcuna vulnerabilità di impatto durante la decompilazione del codec, riteniamo che potrebbero esserci delle vulnerabilità che si nascondono nelle diverse operazioni complesse effettuate dal decoder.
Secondo tentativo: overflow di numeri interi nel codec IMA ADPCM
Il nostro prossimo tentativo sarà il codec IMA ADPCM, implementato in imaadp32.acm. Come ora sappiamo, l'ACM gestirà le conversioni da e tra diversi codec. Per registrare un codec, il codice deve implementare le funzioni ACM. Una di queste funzioni è acmStreamSize, che restituisce il numero di byte necessari per il buffer di destinazione.
Il codec IMA ADPCM calcola la dimensione del buffer di destinazione in base alla dimensione del payload di input (cbSrcLength), l'allineamento (nBlockAlign) e i e campioni per blocco (wSamplesPerBlock; Tabella 2).
(cbSrcLength / pwfxSrc->nBlockAlign) *(pwfxSrc->wSamplesPerBlock * pwfxDst->nBlockAlign)
Tabella 2. Calcolo della dimensione del buffer
Prima di eseguire la moltiplicazione, il codice verifica che il calcolo non provochi un overflow di numeri interi (Tabella 3).
SrcNumberOfBlocks = cbSrcLength / pwfxSrc->WaveFormat.nBlockAlign;
v14 = pwfxSrc->wSamplesPerBlock * pwfxDst->nBlockAlign;
if ( 0xFFFFFFFF / v14 < SrcNumberOfBlocks )
return ERROR_OVERFLOW;
IsThereRemainder = cbSrcLength % pwfxSrc->WaveFormat.nBlockAlign;
if ( IsThereRemainder )
++SrcNumberOfBlocks;
DstBufferLengthInBytes = v14 * SrcNumberOfBlocks;
Tabella 3: Controllo di calcolo inteso a prevenire l'overflow di numeri interi
Apparentemente questo controllo non è sufficiente per evitare un overflow. Se c'è un avanzo nella divisione di cbSrcLength / pwfxSrc->nBlockAlign, il codice incrementa il risultato di (cbSrcLength / pwfxSrc->nBlockAlign), che viene utilizzato nella moltiplicazione. Il controllo di overflow non copre questo incremento. Di conseguenza, possiamo ancora superare la lunghezza del buffer di destinazione specificando valori personalizzati.
Dobbiamo fornire cbSrcLength che abbia un avanzo quando viene diviso per pwfxSrc->nBlockAlign.
La tabella 4 mostra un esempio di valori che portano a un overflow di numeri interi.
cbSrcLength = 0x71c71c72
pwfxSrc->nBlockAlign = 8
pwfxSrc->wSamplesPerBlock = 9
pwfxDst->nBlockAlign = 2
Tabella 4. Esempio di valori che producono un overflow di numeri interi
Ciò produce un buffer di destinazione di 0xE byte, mentre il buffer di destinazione dovrebbe essere molto più grande.
Anche se questo sembra un overflow di numeri interi che può generare una scrittura fuori banda, la funzione di decodifica si assicura correttamente che non avvengano scritture dopo il buffer allocato e non presuppone che il buffer sia stato allocato con la dimensione corretta.
Quindi, nonostante forniamo più campioni, in pratica quando il buffer di destinazione è pieno, il codice si ferma. Lo stesso comportamento si verifica nel codec AD PCM (implementato in msadp32.acm(Secure Access Service Edge).
Terzo tentativo: overflow di numeri interi in ACM (CVE-2023-36710)
Infine, abbiamo trovato un'interessante vulnerabilità nel codice ACM. Come parte del processo di riproduzione di un file WAV, viene chiamata la funzione mapWavePrepareHeader in ACM manager (implementato in msacm32.drv).
Questa funzione presenta una vulnerabilità di overflow di numeri interi. Chiama acmStreamSize, che a sua volta chiama il callback del driver. Tenete presente che questa funzione restituisce la dimensione necessaria per il buffer di destinazione. Dopo aver ricevuto questa dimensione, mapWavePrepareHeader aggiunge 176 byte (la dimensione dell'intestazione del flusso che precederà il buffer di destinazione) senza controlli degli overflow. Il risultato di questa aggiunta viene passato a GlobalAlloc (Figura 6).
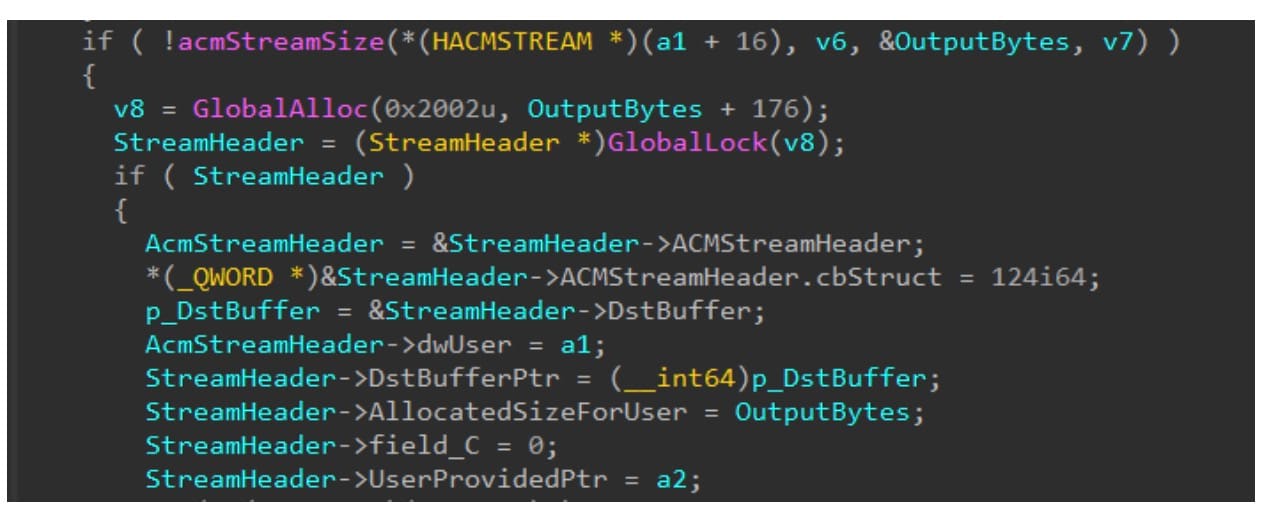 Figura 6. Il codice vulnerabile in mapWavePrepareHeader
Figura 6. Il codice vulnerabile in mapWavePrepareHeader
Questo è un problema sfruttabile. Possiamo fare in modo che GlobalAlloc allochi un buffer veramente piccolo invece di uno grande facendo sì che acmStreamSize restituisca un valore compreso tra 0xffffff50 e 0xffffffff. Dopo questa allocazione possiamo causare due scritture fuori banda:
I valori dell'intestazione del flusso, ad esempio la dimensione della struttura, i puntatori e le dimensioni del buffer di origine e destinazione. Questi valori sono parzialmente controllabili.
I valori decodificati del codec. Questi valori sono completamente controllati.
Per attivare la vulnerabilità dobbiamo fornire un campione WAV con una dimensione, una volta decodificato, che sarà maggiore o uguale a 0xffffff50. Anche se sembra facile da realizzare, durante i nostri tentativi abbiamo riscontrato che potrebbe non essere possibile ottenerlo con alcuni codec. Ad esempio, con il codec MP3, il calcolo include una moltiplicazione per 1.152 o 576 (che è il numero di campioni per fotogramma). Il risultato di quel calcolo non rientrerà mai nell'intervallo che desideriamo.
Alla fine siamo riusciti ad attivare la vulnerabilità utilizzando il codec IMA ADP. La dimensione del file è di circa 1,8 GB. Eseguendo l'operazione di limite matematico sul calcolo possiamo concludere che la dimensione minima del file possibile con il codec IMA ADP è 1 GB.
Lo sfruttamento di tale vulnerabilità è reso più semplice quando è disponibile un motore di scripting per creare dinamicamente un exploit. Poiché Windows Media Player non ne ha uno, lo sfruttamento può essere più impegnativo. Ciò potrebbe essere ancora possibile, come dimostrato da Chris Evans nel suo post sul blog "Advancing exploitation: a scriptless 0day exploit against Linux desktops(Sfruttamento avanzato: un explot 0day senza script contro i desktop Linux). Tuttavia, esistono diverse possibilità che questa vulnerabilità venga sfruttata con successo nel contesto dell'applicazione Outlook (o altre applicazioni di messaggistica istantanea).
Riepilogo
Questa serie di blog ha illustrato una ricerca iniziata con una vulnerabilità sfruttata in rete. (Leggete la Parte 1, se non l'avete ancora fatto). Il percorso di ricerca è poi continuato cercando possibili metodi di aggiramento e infine ha trovato una vulnerabilità complementare a cui concatenarla per ottenere una catena RCE a zero clic. Anche se queste vulnerabilità sono state risolte, gli autori di attacchi continuano a cercare superfici di attacco e vulnerabilità simili che possano essere sfruttate da remoto.
Al momento, la superficie di attacco in Outlook da noi analizzata esiste ancora ed è possibile individuare e sfruttare nuove vulnerabilità. Sebbene Microsoft abbia applicato una patch a Exchange per eliminare i messaggi di posta contenenti la proprietà PidLidReminderFileParameter, non possiamo escludere la possibilità di aggirare tale mitigazione.
Appendice
In questo sito sono elencati tutti i tipi di media e i codec disponibili in Media Foundation di Microsoft.
I nostri test indicano che nella pratica solo i seguenti codec sono disponibili tramite WAV:
1 - PCM
2 - ADPCM
6 - A-LAW
7 - U-LAW
11 - IMA ADPCM
31 - GSM 6.10
55 - MPEG-1 Audio Layer III (MP3)
00000003_0000_0010_8000_00aa00389b71 - IEEE Float
00000008-0000-0010-8000-00aa00389b71 - DTS Audio
00000092-0000-0010-8000-00aa00389b71 - Dolby Digital
00000164-0000-0010-8000-00aa00389b71 - Microsoft WMA
