
Untersuchung von drei Sicherheitsschwachstellen bei Remotecodeausführung in der RPC-Laufzeit


Zusammenfassung
Ben Barnea, Forscher bei Akamai, fand drei wichtige Schwachstellen in der Microsoft Windows RPC-Laufzeit, die die Kennungen CVE-2023-24869, CVE-2023-24908und CVE-2023-23405erhalten haben und jeweils einen Basiswert von 8,1 aufweisen.
Diese Schwachstellen können zu Remotecodeausführung führen. Da die RPC-Laufzeitbibliothek auf alle RPC-Server geladen wird und Windows-Services diese üblicherweise verwenden, sind alle Windows-Versionen (Desktop und Server) betroffen.
Bei den Schwachstellen handelt es sich um Integer-Überläufe in drei Datenstrukturen, die von der RPC-Laufzeit verwendet werden.
Die Schwachstellen wurden verantwortungsvoll an Microsoft weitergegeben und im Patch Tuesday im März 2023 behoben..
Einführung
MS-RPC ist ein in Windows-Netzwerken häufig verwendetes Protokoll, auf dem viele Services und Anwendungen basieren. Daher können Schwachstellen in MS-RPC schwerwiegende Folgen haben. Die Akamai Security Intelligence Group untersucht MS-RPC jetzt seit einem Jahr. Wir haben Schwachstellen entdeckt und ausgenutzt, Forschungs-Tools entwickelt und einige der nicht dokumentierten internen Elemente des Protokolls aufgearbeitet.
Während sich frühere Blogbeiträge auf Schwachstellen in Services konzentrierten, werden in diesem Beitrag Schwachstellen in der RPC-Laufzeit untersucht – der "Engine" von MS-RPC. Diese Schwachstellen ähneln einer Sicherheitslücke, die wir im Mai 2022 entdeckt haben.
Der Integer-Überlauf als Gemeinsamkeit
Die drei neuen Schwachstellen haben ein gemeinsames Merkmal – sie alle existieren aufgrund eines Integer-Überlaufs beim Einfügen in drei Datenstrukturen:
SIMPLE_DICT (ein Wörterbuch, in dem nur Werte gespeichert werden)
SIMPLE_DICT2 (ein Wörterbuch, in dem sowohl Keys als auch Werte gespeichert werden)
Warteschlange
Alle diese Datenstrukturen werden mithilfe einer dynamischen Reihe implementiert, die mit jeder vollständigen Reihe wächst. Dies geschieht durch Zuweisung einer Speichermenge, die der zweifachen Speichermenge der aktuellen Reihe entspricht. Dieser Zuweisungsprozess ist anfällig für einen Integer-Überlauf.
Abbildung 1 zeigt dekompilierten Code aus der RPC-Laufzeit. Sie zeigt den Einfügevorgang in die SIMPLE_DICT-Struktur und die anfällige Codezeile (hervorgehoben), in der ein Integer-Überlauf ausgelöst werden kann.
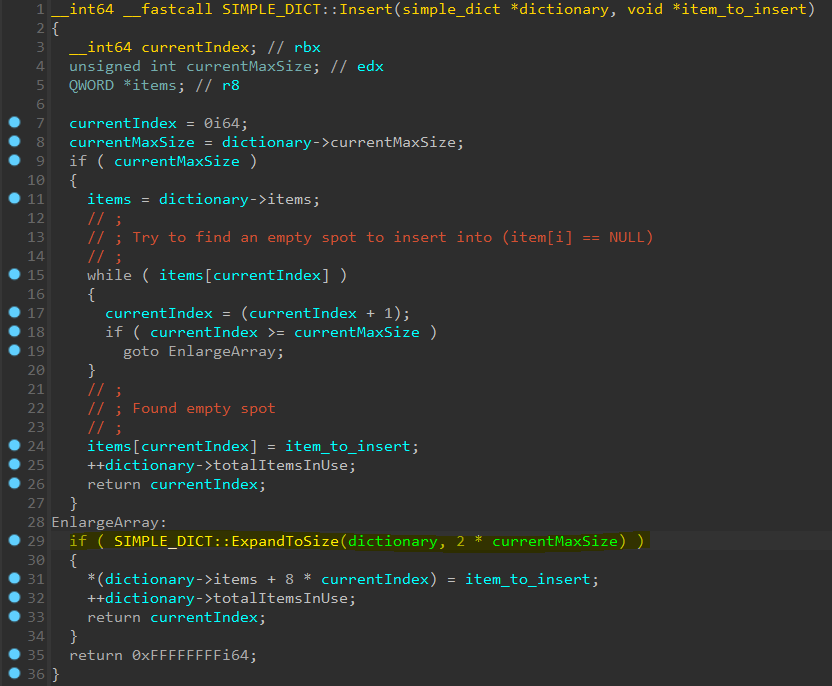 Abb. 1: Ein Integer-Überlauf in der Erweiterung der Struktur SIMPLE_DICT
Abb. 1: Ein Integer-Überlauf in der Erweiterung der Struktur SIMPLE_DICT
So wird eine Schwachstelle ausgenutzt
Um eine Schwachstelle auszulösen, müssen wir die zugrunde liegende Ursache verstehen, herausfinden, ob ein Datenstrom zu der anfälligen Funktion besteht und wissen, wie viel Zeit nötig ist, um sie auszulösen.
Der Kürze halber werden wir nur eine der drei Schwachstellen beschreiben: die in der Datenstruktur einer Warteschlange. Da die anderen Integer-Überläufe ähnlich aussehen, gilt die Analyse in den folgenden Abschnitten für alle drei.
Was ist ein Integer-Überlauf?
Eine Warteschlange ist eine einfache FIFO-Datenstruktur (First in, First Out). Eine Warteschlange in der RPC-Laufzeit wird mithilfe eines Konstrukts implementiert, das eine Reihe von Warteschlangeneinträgen, die aktuelle Kapazität und die Position des letzten Elements in der Warteschlange enthält.
Wenn ein neuer Eintrag der Warteschlange hinzugefügt wird (vorausgesetzt, es gibt einen freien Platz), werden alle Elemente in der Reihe nach vorne verschoben und das neue Element wird am Anfang der Reihe eingefügt. Die Position des letzten Elements in der Warteschlange wird dann hochgezählt.
Beim Entfernen aus der Warteschlange wird das letzte Element herausgezogen und die Position des letzten Elements wird runtergezählt (Abbildung 2).
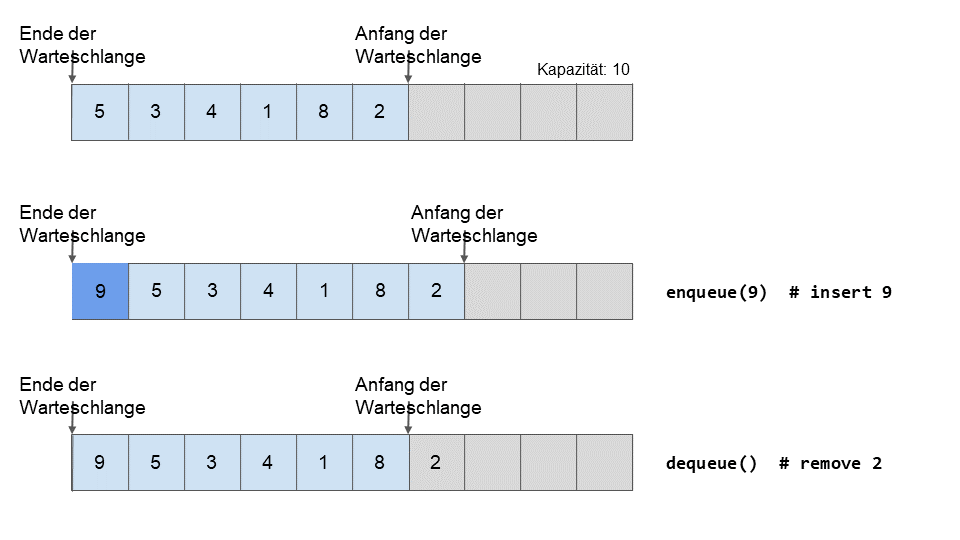 Abb. 2: Eine Warteschlangenstruktur während des Hinzufüge- und Entfernungsvorgangs
Abb. 2: Eine Warteschlangenstruktur während des Hinzufüge- und Entfernungsvorgangs
Wie bereits erwähnt, tritt die Sicherheitslücke beim Einfügen eines neuen Elements auf. Wenn die dynamische Reihe voll ist, bewirkt der Code Folgendes:
Eine neue Reihe mit der folgenden Größe wird zugewiesen:
CurrentCapacity * 2 * sizeof(QueueEntry)Die alten Elemente werden in die neue Reihe kopiert
Die alten Elemente werden aus der Reihe entfernt
Die Kapazität wird verdoppelt
Bei einem 32-Bit-System tritt der Überlauf bei der Berechnung der Größe der neuen Reihe auf:
Wir füllen die Warteschlange mit 0x10000000 (!) Elementen.
Es findet eine Expansion statt. Die Größe der neuen Zuweisung wird berechnet: 0x10000000 * 16. Da ein Überlauf stattfindet, beträgt die Größe der neuen Zuweisung 0.
Eine Reihe mit der Größe 0 wird zugewiesen.
Der Code kopiert die alte Reihe von Elementen in die neue, kleine Reihe. Dadurch entsteht eine Wild Copy (eine Kopie in linearer Größe).
Auf einem 64-Bit-System kann diese Schwachstelle nicht ausgenutzt werden, da eine riesige Zuweisung fehlschlagen wird. Dies führt dazu, dass der Code ordnungsgemäß beendet wird, ohne Out-of-Bound-Schreibvorgänge auszulösen. Obwohl 64-Bit-Systeme nicht von diesem Problem betroffen sind, sind sie anfällig für andere Integer-Überläufe (In SIMPLE_DICT und SIMPLE_DICT2).
Codeablauf
Eine RPC-Verbindung wird mit der Klasse OSF_SCONNECTION dargestellt. Jede Verbindung kann mehrere Clientaufrufe (OSF_SCALL) umfassen, es kann jedoch immer nur ein Aufruf zur Zeit auf der Verbindung ausgeführt werden, während die anderen in die Warteschlange gestellt werden.
Darum ist eine interessante Funktion, die eine Warteschlange verwendet, die Funktion OSF_SCONNECTION::MaybeQueueThisCall. Sie wird als Teil des Sendevorgangs eines neuen Aufrufs, der über die Verbindung eingegangen ist, aufgerufen. In diesem Fall wird die Warteschlange verwendet, um eingehende Aufrufe "zu halten", während ein anderer Aufruf verarbeitet wird.
Es gibt also eine nutzergesteuerte Möglichkeit, eine Warteschlange zu füllen (indem Clientaufrufe nacheinander gesendet werden), aber diese Funktion umfasst eine Anforderung: Ein Aufruf wird derzeit von der Verbindung verarbeitet. Das bedeutet, dass wir zum Füllen der Warteschlange einen Aufruf haben müssen, dessen Abschluss etwas Zeit in Anspruch nimmt. Während der Aufruf verarbeitet wird, senden wir mehrere neue Aufrufe, die die Dispatch-Warteschlange füllen.
Der Abschluss welcher Art von Funktionsaufruf dauert also am längsten?
Am besten wählen wir eine Funktion, in der wir eine Endlosschleife verursachen können.
Die zweitbeste Option ist eine Schwachstelle, bei der eine Authentifizierung erzwungen wird, da der Server dann eine Verbindung zu uns herstellt. Somit haben wir die Kontrolle über die Reaktionszeit.
Als letzte Instanz können wir eine komplexe Funktion mit einer komplizierten Logik oder eine Funktion, die viele Daten verarbeitet und daher viel Zeit in Anspruch nimmt, wählen.
Wir haben uns entschieden, unsere eigene Schwachstelle, bei der eine Authentifizierung erzwungen wird, zu verwenden.
Benötigte Zeit bis zum Auslösen
Jetzt wissen wir, was nötig ist, um die Warteschlange zu befüllen, und wie dies getan werden kann. Aber es stellt sich noch eine wichtige Frage: Ist das praktisch?
Wir haben nur minimale Kontrolle über die Variable, in der der Integer-Überlauf auftritt – wir können sie nur einzeln erhöhen – ähnlich wie bei Refcount-Überläufen (Referenzzählung). Diese Art von Integer-Überlauf ist geringfügig schlimmer als Integer-Überläufe, bei denen zwei Variablen, die wir vollständig kontrollieren, hinzugefügt oder multipliziert werden, oder bei denen die hinzugefügte Größe in irgendeiner Form gesteuert werden kann (z. B. Paketgröße).
Wie bereits erwähnt, müssen wir 0x10000000 (~268M) Elemente zuweisen. Das ist eine große Menge.
Der Versuch, die Schwachstelle auf meinem Computer auszulösen, führte zu einer Rate von ca. 15 bis 20 Aufrufen, die pro Sekunde in die Warteschlange gestellt werden. Das bedeutet, dass es bei einer durchschnittlichen Maschine etwa 155 Tage dauern würde, bis die Schwachstelle ausgelöst wird! Wir haben erwartet, dass wir eine höhere Anzahl von Aufrufen pro Sekunde in die Warteschlange zu stellen. Gibt es einen Grund, warum die RPC-Laufzeit so langsam ist? Verfügt sie nicht über Multithreading?
Wir gingen davon aus, dass mehrere Threads verschiedene Aufrufe für dieselbe Verbindung gleichzeitig verarbeiten und in die Warteschlange stellen. Nach einer gewissen Menge an Reverse Engineering haben wir festgestellt, dass der Fluss in der Praxis ein wenig anders aussieht.
MS-RPC-Paketverarbeitung
Kurz bevor ein Aufruf gesendet wird, startet der Code (falls erforderlich) einen neuen Thread und ruft OSF_SCONNECTION::TransAsyncReceive auf. TransAsyncReceive versucht, auf derselben Verbindung eine Anfrage zu empfangen. Anschließend leitet es die Anfrage an den neuen Thread weiter (indem es CO_SubmitRead aufruft).
Der andere Thread wählt die Anfrage von TppWorkerThread aus und führt schließlich zum Aufruf von ProcessReceiveComplete, das MaybeQueueThisCall aufruft, um den SCALL in die Dispatch-Warteschlange zu stellen. Danach expandiert er und versucht, eine neue Anfrage für diese Verbindung zu empfangen.
Obwohl mehrere Threads ausgeführt werden können, wird in der Praxis nur einer für die Verbindung verwendet. Das bedeutet, dass wir nicht gleichzeitig Aufrufe aus mehreren Threads zur Warteschlange hinzufügen können.
„Paketreste“
Wir haben versucht, mehr Aufrufe pro Sekunde zu tätigen, um die Zeit bis zum Auslösen der Schwachstelle zu minimieren. Wir haben beim Reverse Engineering des Empfangscodes festgestellt, dass die RPC-Laufzeit den Rest speichert, wenn die Länge eines Pakets größer als die tatsächliche RPC-Anfrage ist. Wenn sie später nach neuen Anfragen sucht, verwendet sie nicht sofort den Socket. Sie prüft zunächst, ob das Paket „Reste“ enthält, und wenn ja, stellt sie mit den Resten eine neue Anfrage.
Dadurch konnten wir viel weniger Pakete senden, von denen jedes die maximale Anzahl an Anfragen enthielt. Die Anzahl der Aufrufe in der Warteschlange pro Sekunde blieb relativ unverändert, als wir genau das versuchten. Das schien also nichts zu ändern.
Zusammenfassung
Trotz der zu erwartenden geringen Wahrscheinlichkeit, dass diese Schwachstellen ausgenutzt werden, haben wir sie in die Liste der wichtigsten Schwachstellen, die wir im letzten Jahr unserer Forschung zu MS-RPC gefunden haben, aufgenommen. Es ist wichtig, sich klarzumachen, dass selbst schwer ausnutzbare Schwachstellen einem kompetenten (und geduldigen) Angreifer eine Chance bieten können.
Obwohl MS-RPC bereits seit mehreren Jahrzehnten existiert, gibt es immer noch Schwachstellen, die darauf warten, entdeckt zu werden.
Wir hoffen, dass diese Forschung andere Forscher ermutigen wird, sich mit MS-RPC und der Angriffsfläche, die es darstellt, auseinanderzusetzen. Wir möchten uns bei Microsoft für die schnelle Reaktion und die Behebung der Probleme bedanken.
Unsere GitHub-Repository ist voller Tools und Techniken, die Ihnen den Einstieg erleichtern.
