
Kennzeichnung von 13 Millionen schädlichen Domains in einem Monat dank NDO‑Datensatz


Von Stijn Tilborghs und Gregorio Ferreira
Zusammenfassung
Akamai-Forscher haben in der ersten Jahreshälfte 2022 fast 79 Millionen Domains als schädlich gekennzeichnet, basierend auf einem Datensatz neu beobachteter Domains (Newly Observed Domains, NODs). Das entspricht etwa 13 Millionen schädlichen Domains pro Monat und macht 20,1 % aller NODs aus, die erfolgreich aufgelöst wurden.
Wir haben einen NOD‑basierten Erkennungsansatz mit einem anderen bekannten Threat-Intelligence-Aggregator in Bezug auf die Abdeckung und die mittlere Erkennungszeit verglichen und festgestellt, dass sie sich hervorragend ergänzen.
Mit der NOD‑basierten Bedrohungserkennung können wir uns sogenannte „Long Tail“-DNS‑Abfragen (zu Deutsch: langer Schwanz) ansehen und neue Bedrohungen schon sehr früh in ihrem Lebenszyklus erkennen.
Einführung
Akamai CacheServe-Instanzen verarbeiten derzeit mehr als 80 Millionen DNS‑Abfragen pro Sekunde oder täglich etwa sieben Billionen Anfragen aus der ganzen Welt. Eine anonymisierte Teilmenge dieser Daten erreicht unser Team aus Forschern, die hart daran arbeiten, das Leben im Internet sicherer zu machen.
Wir sind Teil von Akamai Security Research. Wir erstellen DNS- und IP‑Informationen für Internetanbieter und Unternehmen, damit Endnutzer wie Sie und ich sicher und geschützt im Internet surfen können.
Wie Sie zweifellos wissen, sind die Ziele von Weblinks nicht immer sicher. Wenn wir ein Ziel als schädlich identifizieren, können unsere Systeme eingreifen, damit Sie nicht Opfer von Malware, Phishing und vielen anderen Bedrohungen werden.
In diesem Artikel erfahren Sie mehr über eines unserer mächtigsten Assets, den NDO‑Datensatz, und darüber, wie wir ihn verwenden, um neue schädliche Domainnamen mit einer sehr kurzen mittleren Erkennungszeit (Mean Time to Detect, MTTD) zu kennzeichnen.
Wir stellen das Konzept der NODs vor und zeigen Ihnen, wie sie unser Team in die Lage versetzen, Kunden und Endnutzer zu schützen. In einem zukünftigen Beitrag werden wir uns näher mit dem Prozess hinter dieser Forschung befassen, aus Perspektive des maschinellen Lernens.
Neu beobachtete Domains
Einige unserer CacheServe-Kunden (in der Regel Internetanbieter) stellen uns anonymisierte DNS‑Abfragefelder zur Verfügung, wie den angeforderten FQDN und die aufgelöste IP‑Adresse. Aus diesen Daten extrahieren wir die Domainnamen und verfolgen, wann die einzelnen Namen zuletzt beobachtet wurden. Wenn ein Domainname in den letzten 60 Tagen zum ersten Mal abgefragt wird, betrachten wir ihn als neu beobachtete Domäne (oder Newly Observed Domain, NOD).
Mit dem NOD-Datensatz können wir uns stärker auf den sogenannten „Long Tail“ konzentrieren – in diesem Fall der Long Tail von DNS‑Abfragen. In diesem Datensatz finden Sie frisch registrierte Domainnamen, Tippfehler und Domains, die nur sehr selten auf globaler Ebene abgefragt werden.
Andere Organisationen, von denen wir wissen, dass sie NODs überwachen, haben angegeben, dass sie ein Zeitfenster von 30 Minuten bis 72 Stunden verwenden. Das ist weit von dem 60‑Tage-Fenster entfernt, das wir nutzen. Wir verwenden ein so langes Fenster, um sicherzustellen, dass wir nur die neuesten und am seltensten abgefragten Domainnamen betrachten. In dieser Teilmenge haben unsere Forscher große Mengen neuer und aufkommender DNS‑basierter Cyberbedrohungen gefunden.
Darüber hinaus verfolgen wir auch DNS‑Abfragen, die nie erfolgreich aufgelöst wurden (NXDOMAIN). Wir tun dies, da die meisten Domains, mit denen Malware eine Verbindung herstellt, nicht einmal registriert sind. Dadurch steigt unsere Datenmenge zwar um ein Vielfaches an, doch so können unsere Sicherheitsforscher sich ein vollständiges Bild machen, anstatt nur eine verzerrte Stichprobe zu untersuchen.
Das ist unser NOD‑Datensatz. Er bietet uns außerdem eine Fülle von Optionen für die Analyse.
Schädliche Aktivitäten in NOD‑Daten
Um Ihnen zu vermitteln, wie der NOD‑Datensatz tatsächlich aussieht, zeigt Abbildung 1 eine zufällige Stichprobe vom 3. März 2022.
aa65ef[.]ch
i3oq6565ybln1l14[.]com
1z4e1feu8flth[.]com
fkyjtgqnodzv0n0[.]com
xmyc[.]ren
bx76-lzlirxpp6[.]com
vcd7alw-x34ujurr7aeciih9l8[.]com
yporqueyo[.]com
avdl2-li2tmw86[.]com
vnfwjetwwqqddnundjgk[.]jp
lynnesilkmandesig[.]com
aa73ve[.]ch
Abb. 1: Eine zufällige Stichprobe des NOD-Datensatzes
Nachdem Sie Abbildung 1 gesehen haben, wird es Sie nicht überraschen, dass NODs mit einer ziemlich hohen Wahrscheinlichkeit schädlich sind.
An einem typischen Tag beobachtet unser Team insgesamt rund 12 Millionen neue NODs, von denen etwas mehr als zwei Millionen erfolgreich aufgelöst werden. In den ersten sechs Monaten des Jahres 2022 wurden dank der NOD‑basierten Bedrohungserkennung fast 79 Millionen Domainnamen als schädlich markiert. Das macht den NOD‑Datensatz zu einem zentralen Bestandteil unserer Erkennungsmechanismen.
Viele Namen im NOD‑Datensatz sehen aus wie Namen, die Sie niemals in ein Browserfenster eingeben würden. Sie sind von Menschen nicht lesbar und sehen computergeneriert aus. Warum sehen wir so viele davon?
Cyberkriminelle registrieren häufig Tausende von Domainnamen gleichzeitig. Wenn eine oder mehrere ihrer Domains gekennzeichnet und blockiert werden (z. B. von unserem Team), können sie einfach zu einer der anderen Domains wechseln, die sie besitzen. In der Regel werden diese Domainnamen mithilfe eines Domain Generation Algorithm (DGA) programmbasiert erstellt. Dieser automatisierte Prozess ist einer der Gründe dafür, dass NODs so gefährlich sind. Sie stellen eine beharrliche Art von Angriffen auf Unternehmen dar.
Oftmals ist es so, dass Ziffern in die Namen eingefügt werden, sodass die Wahrscheinlichkeit gering ist, dass die generierten Domains bereits registriert wurden.
Zu den häufigsten Bedrohungen, die die oben genannte Technik verwenden, gehören Malware, Ransomware, Cryptominer, Typosquatting (häufig für Phishing verwendet), Botnets und APTs. Je besser und schneller wir solche Muster und computergenerierten Namen erkennen, desto mehr Bedrohungen können wir neutralisieren, bevor sie Schaden anrichten.
Erkennung schädlicher Aktivitäten in NOD‑Daten
Hier eine kleine Auswahl der NOD‑basierten Erkennungsmethoden unseres Teams.
Bekannte DGA‑Datenbank
Schauen wir uns zwei Domainnamen aus den früheren Beispielen genauer an: aa65ef[.]ch und aa73ve[.]ch. Beide haben die gleiche Länge, die gleiche Top-Level-Domain (TLD) und die gleiche Position alphabetischer und numerischer Zeichen. Das deutet darauf hin, dass sie sehr wahrscheinlich vom selben DGA erstellt wurden.
Sobald wir die inneren Abläufe eines DGA durch Reverse Engineering kennen, ist es einfach, Namen zu generieren, die wir in Zukunft erwarten können. Genau das ist bei einem unserer internen Projekte geschehen: Wir haben eine Datenbank mit vorhergesagten Namen für alle bekannten DGA‑Familien erstellt – und zwar bis zu 30 Jahre in die Zukunft. Möglich war das nur durch den öffentlichen Wissensaustausch in der Cybersicherheitscommunity. Vielen Dank, liebe Kolleginnen und Kollegen, dass ihr euer Wissen mit uns geteilt habt!
Jedes Mal, wenn wir eine neue NOD erkennen, suchen wir in dieser Datenbank nach einer Übereinstimmung. Und wenn eine solche Übereinstimmung besteht, stufen wir die NOD als schädlich ein. Etwa 0,1 % der erfolgreich aufgelösten NODs werden derzeit durch diese Methode als schädlich gekennzeichnet.
Das bedeutet, dass das aus der Cybersicherheitscommunity gesammelte Wissen hier aktiv Einfluss nimmt und Endnutzer schützt. Aber es heißt auch, dass diese Methode nur einen kleinen Teil der schädlichen Aktivität erkennt und dass wir zusätzliche Erkennungsmechanismen benötigen.
Heuristische Analyse
Unsere Forscher arbeiten seit vielen Jahren mit NOD‑Daten. Durch manuelle Analysen und die Forschung der letzten zwölf Jahre haben wir mehr als 190 NOD‑spezifische Erkennungsregeln erstellt.
Diese heuristischen Regeln sind derzeit für die große Mehrheit aller Erkennungen verantwortlich und basieren auf Eingaben wie dem Domainnamen selbst, seiner TLD, der aufgelösten IP, Autonomous System Numbers (ASNs) usw.
Ein Beispiel für eine solche Regel könnte wie folgt aussehen:
Markiere alle NODs mit:
Einer ASN‑Risikobewertung von über 0,50
Einer TLD-Risikobewertung von über 0,75
Aufgelösten IP‑Adressen im Bereich 127.0.0.0/8
Einem registrierten Domainnamen, der mit einer Ziffer beginnt
Woher wissen wir, dass eine Regel keine False-Positive-Ergebnisse liefert? Hierbei spielt die Erfahrung des Teams eine große Rolle. Im Laufe der Jahre haben die Regeln sicherlich eine ganze Reihe von False Positives verursacht. Wir bieten unseren Kunden einen Meldemechanismus, damit Fehler schnell analysiert und behoben werden können.
Im ersten Halbjahr 2022 fanden wir unter den 79 Millionen gekennzeichneten Domains, die aus der heuristischen Analyse hervorgingen, später 329 False Positives. Das entspricht einer Fehlererkennungsrate von 0,00042 %.
Unser Team aus Data Scientists arbeitet derzeit an einem ML‑basierten Ansatz, um die Heuristik zu erweitern und die Abdeckung weiter zu steigern. Über diesen Ansatz werden wir in einem zukünftigen Blogbeitrag berichten.
Phishing-Erkennung
Bei jeder neu erkannten NOD überprüfen wir die Ähnlichkeit mit einer Liste bekannter Markennamen und beliebter Websites. Wenn wir eine neue NOD mit sehr hoher Ähnlichkeit finden, kann das Grund genug sein, sie als schädlich zu kennzeichnen.
In Fällen leicht geringerer (aber immer noch hoher) Ähnlichkeit bringen wir andere Daten ein, um die Entscheidung zu treffen. Zum Beispiel: Wenn der Domainname auf einen ASN mit einer hohen Risikobewertungverweist, steigt die Wahrscheinlichkeit, dass es sich hierbei um einen Phishing-Angriff handelt.
Schnelle Erkennung von Bedrohungen
Der große Vorteil der NOD‑Erkennung ist die äußerst kurze MTTD.
NOD‑Daten ermöglichen es uns, neue Domains sehr früh im Lebenszyklus einer Bedrohung zu klassifizieren. Um unsere Erkennungsmechanismen auszulösen, benötigen wir lediglich eine einzige DNS‑Abfrage an eine neu erstellte schädliche Domain.
Dazu ein Beispiel:
Wir betrachten einen Phishing-Versuch, der von „Kriminelles Hackerland“ gestartet und gesteuert wird. Die Cyberkriminellen zielen auf safebank[.]abc ab und richten eine gefälschte Website unter savebank[.]abc ein.
Es werden E-Mails versendet, um Besucher dazu zu bringen, die gefälschte Website zu besuchen. Eine dieser E-Mails erreicht John, der in Großbritannien lebt und Kunde bei einem Internetanbieter ist, der CacheServe verwendet. Der Anbieter teilt außerdem CacheServe-Metadaten mit unserem Akamai-Team und John hat sich wie alle anderen Kunden des Anbieters für das erweiterte Sicherheitspaket von Akamai angemeldet.
John klickt auf den Link zur Phishing-Website. Da die Website komplett neu ist und von niemandem als schädlich markiert wurde, kann John sie leider besuchen.
Hinter den Kulissen erhält unser Team jedoch nun einen neuen Eintrag im NOD‑Datensatz für savebank[.]abc. Unsere Phishing-Erkennung identifiziert den Namen sofort als Rechtschreibfehler von safebank[.]abc.
Die Domäne wird als schädlich gekennzeichnet. Diese Information wird an den Internetanbieter weitergegeben. Ab diesem Zeitpunkt sind alle Kunden des Anbieters vor diesem Phishing-Betrug geschützt. Selbst wenn sie auf den Phishing-Link klicken, können sie die gefälschte Website nicht besuchen.
John war möglicherweise das erste Opfer der Phishing-Website. Doch unter den Personen, die von unserem Team geschützten werden, wird er wahrscheinlich auch der letzte gewesen sein.
All unsere NOD‑basierten Erkennungssysteme und -regeln sind voll automatisiert. Das bedeutet, dass wir nach der Identifizierung einer neuen NOD nur Minuten brauchen, um sie als schädlich zu klassifizieren – keine Stunden oder Tage. Und es ist kein menschliches Eingreifen nötig.
All das verschafft unserer NOD‑basierten Bedrohungserkennung einen Geschwindigkeitsvorteil gegenüber vielen anderen Erkennungsmechanismen. Es ermöglicht unserem Team, neue DNS‑basierte Bedrohungen schnell abzuwehren.
Noch einmal zusammengefasst:
Das Ereignis, das die Bedrohungserkennung auslöst, findet in einem sehr frühen Stadium des Bedrohungslebenszyklus statt.
Die Erkennungssysteme selbst sind sehr schnell, da sie voll automatisiert sind.
Wie effektiv sind wir?
Um einen Vergleich durchführen zu können, sehen wir uns die erfolgreich aufgelösten NODs genauer an, da wir in externen Datensätzen keine ungelösten Domainnamen finden werden. Deshalb gelten die unten aufgeführten Zahlen nur für rcode 0. Wir beschränken uns außerdem auf einen Zeitraum vom 1. Januar 2022 bis Ende Juni 2022.
In diesem Zeitrahmen haben die Erkennungssysteme unseres Teams 20,1 % aller NODs als schädlich markiert. Das entspricht fast 79 Millionen eindeutigen schädlichen Domainnamen in diesem 6‑Monats-Zeitraum, basierend auf rcode 0 allein.
Wir haben uns dazu entschieden, eine Evaluierung mit einem großen und bekannten Threat-Intelligence-Aggregator als Referenz durchzuführen. Wir werden diese Referenz als „der Aggregator“ bezeichnen.
Auf der einen Seite hatten wir alle NODs, die durch das heuristische Analyseprojekt, das wir bereits beschrieben haben, als schädlich markiert wurden.
Und auf der anderen Seite hatten wir alle Domainnamen, die mindestens einmal in der oben erwähnten Datenbank durchsucht worden waren.
Wir fanden heraus, dass 91,4 % der als schädlich markierten NODs dort nicht vorhanden waren.
Wir fanden auch heraus, dass von den Namen, die wir finden konnten, mehr als 99,9 % eine Reputation von 0 hatten, was bedeutet, dass diese noch nicht als gutartig oder schädlich gekennzeichnet waren (sie wurden nur von jemandem durchsucht).
Zusammenfassend lässt sich sagen, dass wir für alle erfolgreich aufgelösten Domainnamen, die unsere Forscher anhand der heuristischen Regeln identifiziert haben, nur für etwa einen von 11.000 Namen ein Urteil des bekannten Aggregators erhalten konnten.
Haben wir besser oder schlechter abgeschnitten als der Aggregator? Diese Frage können wir hier nicht beantworten.
Aus den oben genannten Zahlen lässt sich schließen, dass der NOD‑Datensatz eine starke Ergänzung darstellt, da es nur eine sehr geringe Überschneidung zwischen seiner Ausgabe und den Aufgaben anderer wichtiger Threat-Intelligence-Feeds gibt.
Wie schnell sind wir?
Lassen Sie uns nun die Zeit analysieren, die wir für die Erkennung benötigen.
Hierfür nehmen wir die gleiche Datenkonfiguration her wie oben und sehen uns die kleine Überschneidung näher an, die wir gefunden haben. Hierbei handelt es sich um Fälle, in denen sowohl der Aggregator als auch unser Team einen Domainnamen als schädlich markiert haben. Beachten Sie, dass wir uns hier immer noch nur eines unserer Erkennungsprojekte ansehen: die heuristische Analyse.
Abbildung 2 behandelt die Frage: Wenn beide Systeme einen Domainnamen als schädlich kennzeichnen, welches der beiden Systeme ist dann schneller und wie hoch ist der Zeitunterschied?
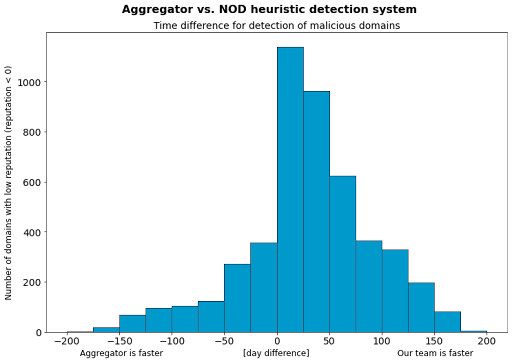
In Fällen, in denen sowohl der Aggregator als auch unser Team einen Domainnamen als schädlich kennzeichnen, haben wir dies in der Regel 29,6 Tage früher festgestellt als der Aggregator (damit ist die MTTD um fast 30 Tage kürzer).
In Abbildung 2 wird diese Zahl weiter aufschlüsselt.
Die Y‑Achse stellt die Anzahl der schädlichen Domainnamen dar.
Die X‑Achse stellt dar, wie viele Tage zwischen unserer Kennzeichnung eines Domainnamens als schädlich und der Kennzeichnung durch das andere System vergangen sind. Die Balken auf der rechten Seite stellen Fälle dar, in denen unser Erkennungssystem schneller war. Balken auf der linken Seite stellen Fälle dar, in denen der Aggregator schneller war.
Hier kann der NOD‑Ansatz wirklich seine hervorragende MTTD demonstrieren, da sich seine Erkennungsauslöser sehr früh im Lebenszyklus einer typischen Bedrohung befinden.
Es ist jedoch auch klar, dass es zahlreiche Fälle gibt, in denen der NOD‑Ansatz langsamer ist als der Aggregator. Das zeigt, wie wichtig ein vielseitiger Ansatz ist, um das Beste aus beiden Systemen herausholen zu können.
Nach unserer Analyse von Abbildung 2 kommen wir erneut zu dem Schluss, dass die beste Lösung ein kombinierter Ansatz aus NOD‑Ansatz und Aggregator ist.
Eine kürzliche NOD‑Beobachtung
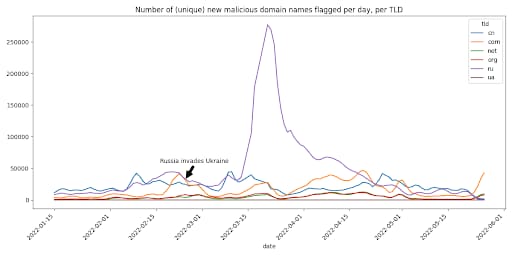
Ein weiterer wichtiger Punkt bei NOD‑Daten ist, dass uns die Analyse dieser Daten eine einzigartige makroökonomische Perspektive auf schädliche Aktivitäten bieten kann. Abbildung 3 zeigt beispielsweise die Anzahl der schädlichen Domainnamen, die wir im Laufe der Zeit pro TLD markiert haben.
Besonders interessant ist das Verhalten der russischen TLD „.ru“. Die Basis sind rund 10.000 neue schädliche Domains pro Tag. Zwei Wochen vor dem russischen Angriffskrieg auf die Ukraine begannen wir, stetig ansteigende schädliche Aktivitäten von fast 40.000 schädlichen NODs pro Tag zu beobachten. Diese Aktivität nahm dann ein wenig ab, bevor es in der zweiten Märzhälfte zu einem massiven Höhepunkt von mehr als 250.000 eindeutigen schädlichen .ru-Domainnamen pro Tag kam.
Dank der Kennzeichnung dieser Domains konnten unsere Kunden ihre Abonnenten vor diesen potenziellen Bedrohungen schützen.
Fazit
Sicherheit muss vielfältig sein, und je mehr wir wissen, desto sicherer können wir die Welt machen. Die NOD‑basierte Bedrohungserkennung ist schnell und ergänzt andere Threat-Intelligence-Feeds sehr gut.
Unser Team wird NODs auch weiterhin überwachen, weiter dazulernen und sein Wissen in zukünftigen Beiträgen mit der Sicherheitscommunity teilen.
In einem zukünftigen Blogbeitrag werden wir näher darauf eingehen, wie wir dem NOD‑Datensatz ML‑basierte Algorithmen (Machine Learning) hinzufügen.
Wenn Sie keine Forschungen unseres Security Research Teams, unseres Threat Intelligence Teams oder eines unserer anderen engagierten Teams verpassen wollen, dann folgen Sie uns auf Twitter , um Informationen über bevorstehende Forschungsarbeiten zu erhalten.

