
Linux 进程注入权威指南


前言
对攻击者而言,进程注入技术是一个非常重要的武器。它们使攻击者能够在合法进程内运行恶意代码而避免被检测到,或者在远程进程中放置钩子以修改其行为。
Windows 机器上的进程注入这一主题已经得到了广泛的研究,公众对此也有了相对较为清晰的了解。而在 Linux 机器上,情况则不尽如此。尽管已有一些不错的 资源 被 撰写 出来,也对这一 主题作了一些探究,但业界对不同 Linux 注入技术的了解似乎相对较少,尤其是与 Windows 比较之下,情况更显如此。
SafeBreach 的 Amit Klein 和 Itzik Kotler 撰写了 《Windows 进程注入概述》 一文。在此启发之下,我们希望能够提供一份关于 Linux 进程注入的全面文档。我们将重点介绍以运行中的实际进程为目标的“真正的进程注入”技术。这意味着在我们的介绍中,将不包括需要 修改磁盘上的二进制文件、 利用特定环境变量执行进程或 滥用进程加载过程的方法。
我们将描述在 Linux 中为进程注入提供便利的操作系统功能,以及它们允许使用的不同注入基元。我们将重温之前提到过的技术,同时还会 重点介绍以前未曾记录过的注入变体。在总结部分中,将涵盖针对这些重点介绍技术的检测和抵御策略。
除了本博文外,我们还发布了一个 GitHub 存储库 ,其中包含用于博文中所述不同注入基元的一组全面的概念验证 (PoC) 代码。这些良性 PoC 的用途在于帮助了解这些技术的恶意实施有何表现形式,从而帮助您培养和测试自己检测此类威胁的能力。有关其他信息,请参考以下项目的 README文件。
Linux 注入对比 Windows 注入
针对 Windows 机器的已知注入技术数量非常庞大,并且一直在增加: 从 APC 队列 和 NTFS 事务 到 原子表 和 线程池。Windows 暴露了许多接口,使攻击者能够与远程进程交互(并注入)。
而在 Linux 中,情况大相径庭。与远程进程的交互仅仅局限于一小部分系统调用操作,而在 Windows 机器上有助于注入的许多功能都难觅踪迹。没有任何 API 能够 在远程进程中分配内存 或 修改远程内存保护,也绝对无法 创建远程线程。
这种差异影响了注入攻击的结构。在 Windows 中,进程注入通常由三个步骤组成:分配 → 写入 → 执行。首先,我们在用于存储代码的远程进程中分配内存,然后将代码写入该内存,最后再执行该代码。
而在 Linux 中,我们没有能力执行第一步,即分配。没有什么方法能够在远程进程中直接分配内存。正因为如此,注入流程将略有不同,变为:重写 → 执行 → 恢复。我们将远程进程中的 现有内存 重写为我们的攻击负载,并执行该负载,然后恢复进程的之前状态以使其能够继续正常执行。
远程进程交互方法
在 Linux 中,与远程进程内存的交互主要限于三种方法: ptrace、 procfs和 process_vm_writev。以下部分简要介绍了其中每种方法。
ptrace
ptrace 是一个用于对远程进程进行调试的系统调用命令。初始进程可以检查并修改已经过调试的进程内存和寄存器。像 GDB 这样的调试器将使用 ptrace 来实施,以控制经过调试的进程。
ptrace 支持不同的操作,而这些操作则通过一个 ptrace 请求代码来指定,值得注意的一些操作示例包括:PTRACE_ATTACH(连接到进程)、PTRACE_PEEKTEXT(从进程内存中读取)和 PTRACE_GETREGS(检索进程寄存器)。代码段 1 显示了 ptrace 的一个用例。
// Attach to the remote process
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// Get registers state
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
代码段 1:用于检索远程进程寄存器的 ptrace 用例
procfs
procfs 是一个特殊的伪文件系统,可用作在系统上运行进程的接口。可以通过 /proc 目录来访问此命令(图 1)。
 Fig. 1: A directory listing of the /proc directory on a Linux machine
Fig. 1: A directory listing of the /proc directory on a Linux machine
每个进程都表示为一个目录,按其 PID 命名。在此目录下面,我们可以找到提供了该进程相关信息的文件。例如, cmdline 文件包含进程命令行, environ 文件包含进程环境变量,如此等等。
procfs 还使我们能够与远程进程内存进行交互。在每个进程目录内,我们都能找到 mem 文件,这个特殊文件代表了该进程的整个地址空间。按指定偏移量访问进程的 mem 文件时,相当于访问同一地址的进程内存。
在图 2 的示例中,我们从指定的偏移量开始,使用 xxd 实用程序从进程 mem 文件中读取 100 字节数据。
 Fig. 2: Using xxd to read the procfs mem file
Fig. 2: Using xxd to read the procfs mem file
如果我们使用 GDB 检查内存中的同一地址,就会发现内容完全相同(图 3)。
 Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
在进程目录中,还可以找到另一个与我们目的相关的文件,即 maps 文件(图 4)。此文件包含关于进程地址空间中不同内存区域的信息,包括它们的地址范围和内存许可。
 Fig. 4: Example contents of a process maps file
Fig. 4: Example contents of a process maps file
在后续几个部分中,我们将发现如果能够识别具有不同许可的内存区域,对我们将会有多大的作用。
process_vm_writev
与远程进程内存进行交互的第三种方法是 process_vm_writev 系统调用。这种系统调用命令允许在远程进程的地址空间中写入数据。
process_vm_writev 会收到一个指向本地缓冲区的指针,并将其内容复制到远程进程内的一个指定地址。代码段 2 中显示了 process_vm_writev 的一个用例。
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our data in the local iovec
local[0].iov_base = data;
local[0].iov_len = data_len;
// Point the remote iovec to the address in the remote process
remote[0].iov_base = (void *)remote_address;
remote[0].iov_len = data_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
代码段 2:使用 process_vm_writev 在远程进程中写入数据
将代码写入到远程进程
现在,我们已经知道了与其他进程进行交互的不同方法,再来看看如何利用它们来执行代码注入。注入攻击的第一步是将我们的 shellcode 写入远程进程内存。前面说过,在 Linux 中,没有什么方法能够在远程进程中直接分配新内存。这意味着我们无法创建新的内存区段,只能利用目标进程的现有内存。
要使我们的代码能够运行,就必须将其写入某个具有执行许可的内存区域。要想找到这样一个区域,我们可以解析前面提及的 procfs maps 文件,然后识别具有执行 (x) 许可的内存区域(图 5)。
 Fig. 5: Identifying an executable memory region in the process maps file
Fig. 5: Identifying an executable memory region in the process maps file
我们可能会发现两种类型的可执行区域:可写入和不可写入。以下部分将介绍何时及如何使用这两种区域。
将代码写入 RX 内存
适用于:ptrace、procfs mem
理想情况下,我们将需要识别具有写入和执行许可的内存区域,从而使我们能够写入并执行代码。但事实上,大多数进程都不存在具有此类许可的区域,所以分配 WX 内存并不是一种好的做法。相反,我们通常只能找到具有读取和执行许可的区域。
有趣的是,事实证明,使用我们刚才所述的两种方法(ptrace 和 procfs mem)可以突破这一限制。在实施这两种机制时,都能绕过内存许可并写入任何地址,哪怕是没有写入许可。有关 procfs 的这一行为的更多详情,请继续阅读 本博文。
这意味着无论是否有写入许可,我们始终都能使用 ptrace 或 procfs mem 将代码写入远程可执行内存区域。
ptrace
在将攻击负载写入远程进程时,我们可以使用 POKETEXT 或 POKEDATA ptrace 请求。这两种请求作用相同,都允许将一条数据写入远程进程内存。只需反复调用这些请求,我们就能成功地将整个攻击负载写入目标进程内存。代码段 3 中显示了此方法的一个示例。
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// write payload to remote address
for (size_t i = 0; i < payload_size; i += 8, payload++)
{
ptrace(PTRACE_POKETEXT, pid, address + i, *payload);
}
代码段 3:使用 ptrace POKETEXT 将攻击负载写入远程进程内存
procfs mem
要使用 procfs 将攻击负载写入远程进程,我们只需要按正确的偏移量将其写入 mem 文件。对 mem 文件所做的任何更改都会应用于进程内存。在执行这些操作时,可以使用标准文件 API(代码段 4)。
// Open the process mem file
FILE *file = fopen("/proc/<pid>/mem", "w");
// Set the file index to our required offset, representing the memory address
fseek(file, address, SEEK_SET);
// Write our payload to the mem file
fwrite(payload, sizeof(char), payload_size, file);
代码段 4:使用 procfs mem 文件将数据写入远程进程内存
将代码写入 WX 内存
适用于:ptrace、procfs mem、process_vm_writev
如前所述,ptrace 和 procfs mem 都能绕过内存许可,并且允许我们在不可写入内存区域中写入代码。但如果使用的是 process_vm_writev,则情况并非如此。process_vm_writev 需要遵循内存许可,因此仅允许我们在可写入内存区域中写入数据。
出于此原因,我们只能查找可写入区域。并非所有进程都将包含此类区域,但我们一定能找到这样的进程。
“代码段 5”中的命令将搜索系统上所有进程的 maps 文件,并识别具有写入和执行许可的区域(图 6)。
find /proc -type f -wholename "*/maps" -exec grep -l "wx" {} +
代码段 5:使用“find”命令识别具有写入和执行内存区域的进程
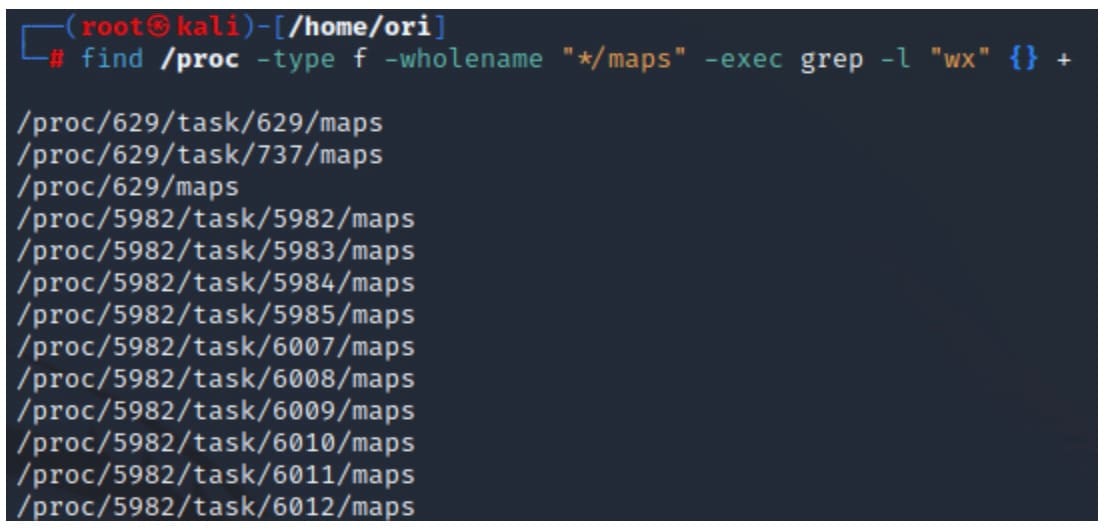 Fig. 6: Example output of finding processes with WX memory regions
Fig. 6: Example output of finding processes with WX memory regions
发现这样的一个区域后,可以使用 process_vm_writev 在其中写入我们的代码(代码段 6)。
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our payload in the local iovec
local[0].iov_base = payload;
local[0].iov_len = payload_len;
// Point the remote iovec to the address of our wx memory region
remote[0].iov_base = (void *)wx_address;
remote[0].iov_len = payload_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
代码段 6:使用 process_vm_writev 在远程 WX 区域中写入攻击负载
劫持远程执行流程
将代码写入远程进程内存后,就需要执行这些代码。在后面的部分中,我们将介绍可以利用哪些技术来达到此目的。
我们重点针对 amd64 机器进行了研究。其他架构可能存在一些细微差异,但总体概念应该没有区别。
修改进程指令指针
适用于:ptrace
当我们使用 ptrace 连接到进程时,其执行将会暂停,并且我们可以检查和修改进程寄存器,包括指令指针。此过程可以使用 SETREGS 和 GETREGS ptrace 请求来完成。在修改进程的执行流程时,可以使用 ptrace 来修改指向 shellcode 地址的指令指针。
在“代码段 7”的示例中,我们执行了以下三个步骤:
使用 GETREGS ptrace 请求检索当前寄存器值
修改指令指针,使其指向我们的攻击负载地址(以 2 为增量,我们稍后将会讨论)
使用 SETREGS 请求,将更改应用于进程
// Get old register state.
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
// Modify the instruction pointer to point to our payload
regs.rip = payload_address + 2;
// Modify the registers
ptrace(PTRACE_SETREGS, pid, NULL, ®s);
代码段 7:使用 ptrace SETREGS 将指令指针指向攻击负载
SETREGS 是记录最为广泛的一种修改进程寄存器的“传统”方法,但另一种 ptrace 请求也可用于执行此修改,那就是 POKEUSER。
POKEUSER 请求允许将数据写入进程 USER 区域 ,这一结构在 sys/user.h中定义,其中包含关于进程的信息,包括寄存器信息。通过按正确的偏移量调用 POKEUSER,我们可以使用攻击代码的地址来重写指令指针,从而达到之前所述的相同结果(代码段 8)。
// calculate the offset of the RIP register, based on the USER struct definition
rip_offset = 16 * sizeof(unsigned long);
ptrace(PTRACE_POKEUSER, pid, rip_offset, payload_address + 2);
代码段 8:使用 ptrace POKEUSER 将指令指针指向攻击负载
如需了解我们使用 POKEUSER 来修改 RIP 的实施过程,可以 在我们的存储库中找到。
RIP += 2:何时发生?为何发生?
如“代码段 7”和“代码段 8”中所示,当我们将 RIP 修改为攻击负载的地址时,实际上也是在将其增加了 2。这是为了适应一种 有趣的 ptrace 行为 。在使用 ptrace 脱离某个进程后,RIP 的值有时会增加 2。我们来看看为何会出现此情况。
当我们使用 ptrace 连接至进程时,可能会中断当前正在内核中执行的某个系统调用。为确保系统调用正确执行,当我们脱离进程时,内核将重新运行该调用。
而在该系统调用执行期间,RIP 已经指向了下一个要执行的指令。为了重新运行系统调用,内核会将 RIP 的值减去 2,这是 amd64 中的系统调用指令大小。进行此更改后,RIP 将再次指向系统调用指令,使其另外运行一次(图 7)。
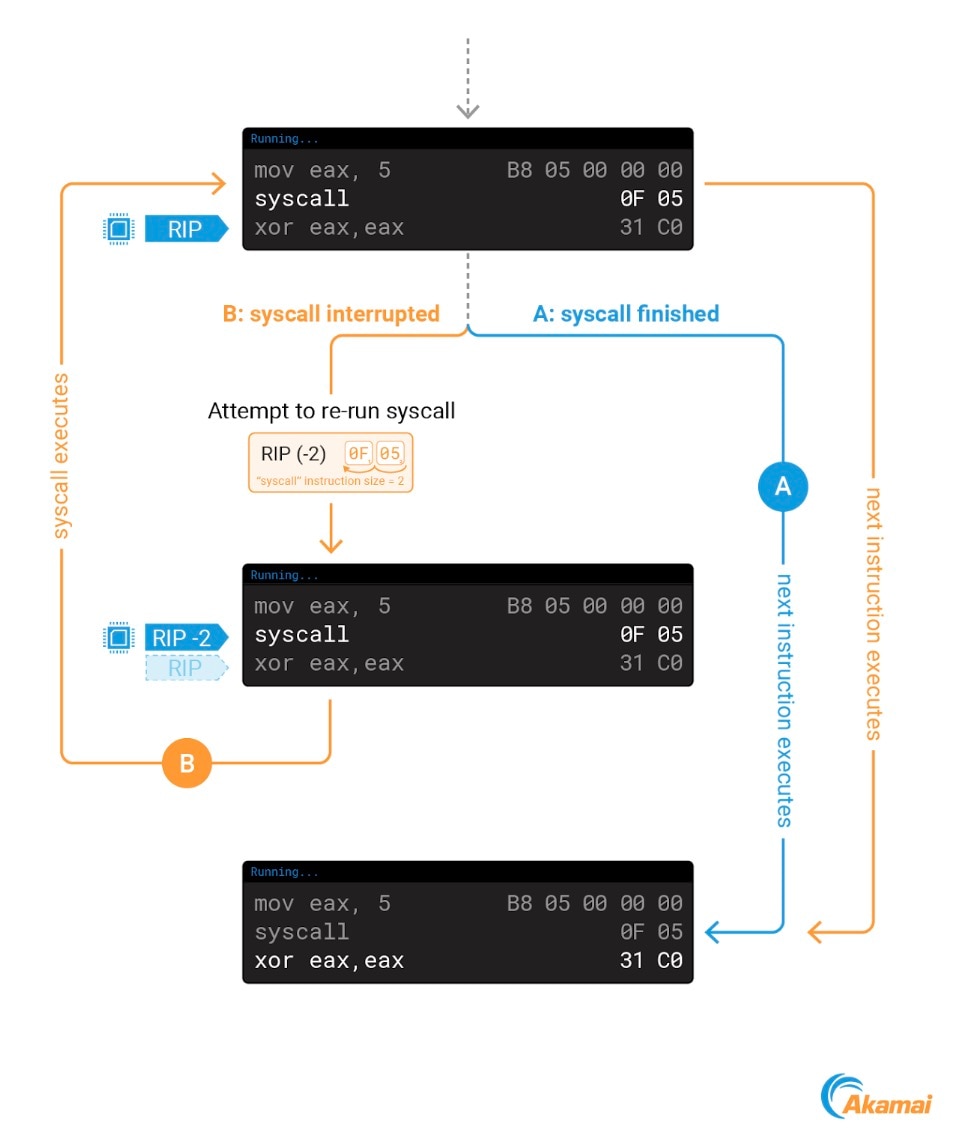 Fig. 7: The effect of using ptrace on a process during syscall execution
Fig. 7: The effect of using ptrace on a process during syscall execution
在执行代码注入时,如果我们恰好在系统调用期间中断了某个进程,就会出现问题。在修改 RIP 以指向我们的攻击代码后,内核仍然会将新值减去 2,导致我们的 shellcode 前面出现一个 2 字节的缺口,因而可能导致代码执行失败(图 8)。
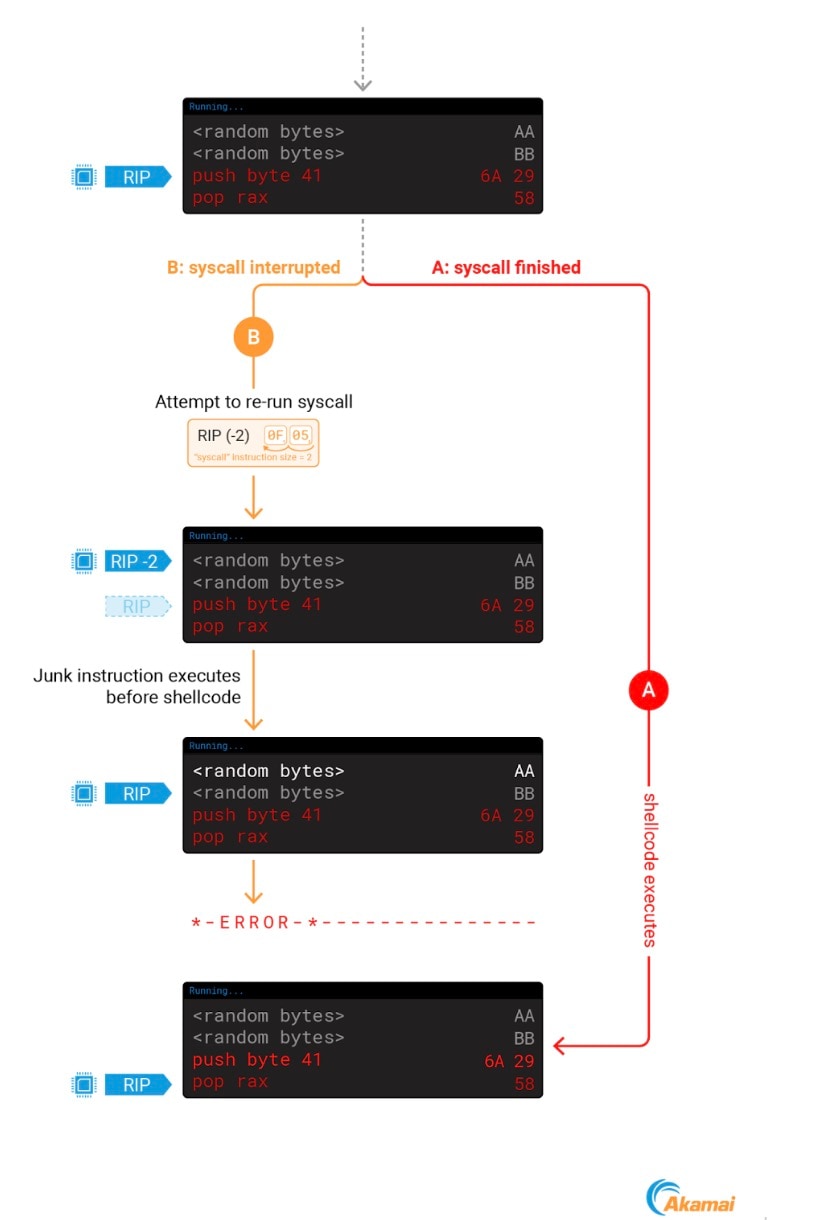 Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
为适应这一行为,我们将采取两个措施:在我们的 shellcode 前面加上两个无操作 (NOP) 指令,并使 RIP 指向 shellcode 地址 + 2。这两步可以确保我们的代码得到恰当执行。
如果我们在系统调用期间中断了进程,内核会减小新的 RIP 值,这会使其指向包含两个 NOP 的 shellcode 起始地址,从而恰好到达我们的实际攻击代码。
如果在系统调用期间没有中断进程,新的 RIP 值则不会减小,这样就会跳过两个 NOP 并执行我们的攻击代码。图 9 中描述了这两种情况。
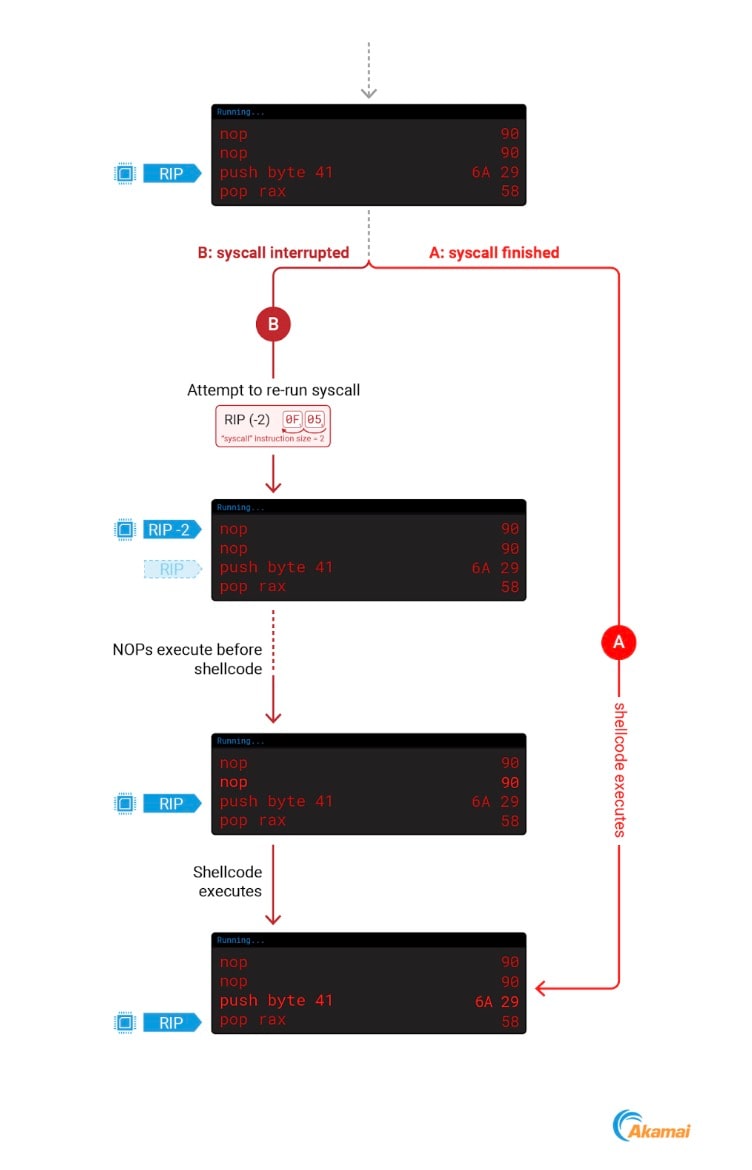 Fig. 9: Overcoming the ptrace RIP interaction
Fig. 9: Overcoming the ptrace RIP interaction
修改当前指令
适用于:ptrace、procfs mem
procfs 中还有一个文件比较有趣,就是 syscall 文件。此文件包含当前由进程执行的系统调用的相关信息,例如系统调用编号、传递到该调用的参数、堆栈指针以及我们最感兴趣的进程指令指针(图 10)。即使进程当前并未执行系统调用,进程的堆栈和指令指针仍然会存在于 syscall 文件中。
 Fig. 10: The structure of the procfs syscall file
Fig. 10: The structure of the procfs syscall file
获得此信息后,我们就能够接管进程的执行流程;而在得知下一个要执行的指令的地址之后,我们就能将其重写为自己的指令。
为达到此目的,攻击者可以招待以下四个步骤:
发送 SIGSTOP 信号,以停止进程执行
读取进程 syscall 文件,以识别要执行的下一个指令的地址
将 shellcode 发送到所识别的地址
发送 SIGCONT 信号,以恢复进程执行
“代码段 9”提供了一段用于此过程的伪代码。
// Suspend the process by sending a SIGSTOP signal
kill(pid, SIGSTOP);
// Open the syscall file
FILE *syscall_file = fopen("/proc/<pid>/syscall", "r");
// Extract the instruction pointer from the syscall file
long instruction_pointer = ...
// Write our payload to the address of the current instruction pointer using
procfs mem
FILE *mem_file = fopen("/proc/<pid>/mem", "w");
fseek(mem_file, instruction_pointer, SEEK_SET);
fwrite(payload, sizeof(char), payload_size, mem_file);
// Resume execution by sending a SIGCONT signal
kill(pid, SIGCONT);
代码段 9:在指令指针的当前地址使用 procfs mem 修改进程内存,以劫持进程的执行流程
“代码段 9”中的示例使用 procfs mem 文件实施了此技术,但请务必注意,ptrace POKETEXT 也能用于将攻击负载写入内存。
我们前面提到过,process_vm_writev 受到内存许可的限制,意味着它只能修改可写入内存区域。找到通过 WX 内存区域运行的代码可能性并不高,这就降低了 process_vm_writev 对于此基元的可靠性。
立即了解 我们如何使用 procfs mem 文件实施此技术。
堆栈劫持
适用于:ptrace、procfs mem 文件、process_vm_writev
另一个可供利用的内存区域是进程堆栈,也可以使用 maps 文件来识别。尽管堆栈内存不可执行(图 11),但我们仍然可以使用它来劫持进程的执行流程。
 Fig. 11: Identifying the process stack address using the maps file
Fig. 11: Identifying the process stack address using the maps file
无论何时调用某个函数,调用函数的返回地址都将被推送到堆栈。当函数完成执行时,处理器会从堆栈中提取此返回地址,然后跳转到该地址(图 12)。
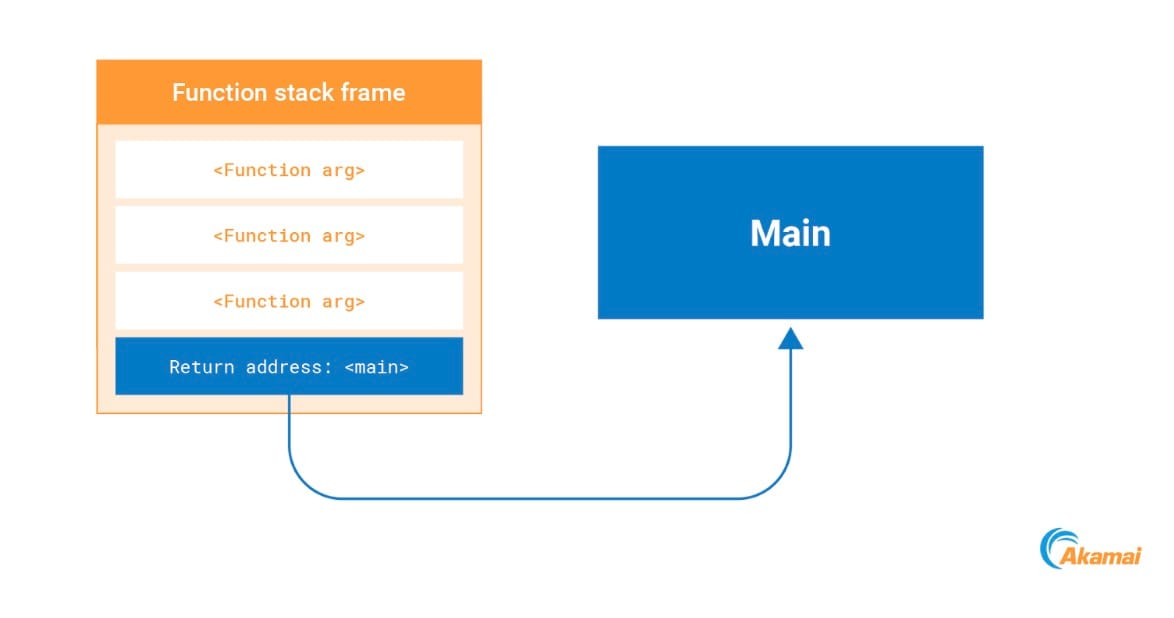 Fig. 12: Return address on the stack pointing to an address in main
Fig. 12: Return address on the stack pointing to an address in main
如需滥用此机制,我们可以识别堆栈上的一个返回地址,然后将其重写为指向我们的 shellcode 的新地址。只要当前函数完成执行,我们的代码就会立即运行(图 13)。
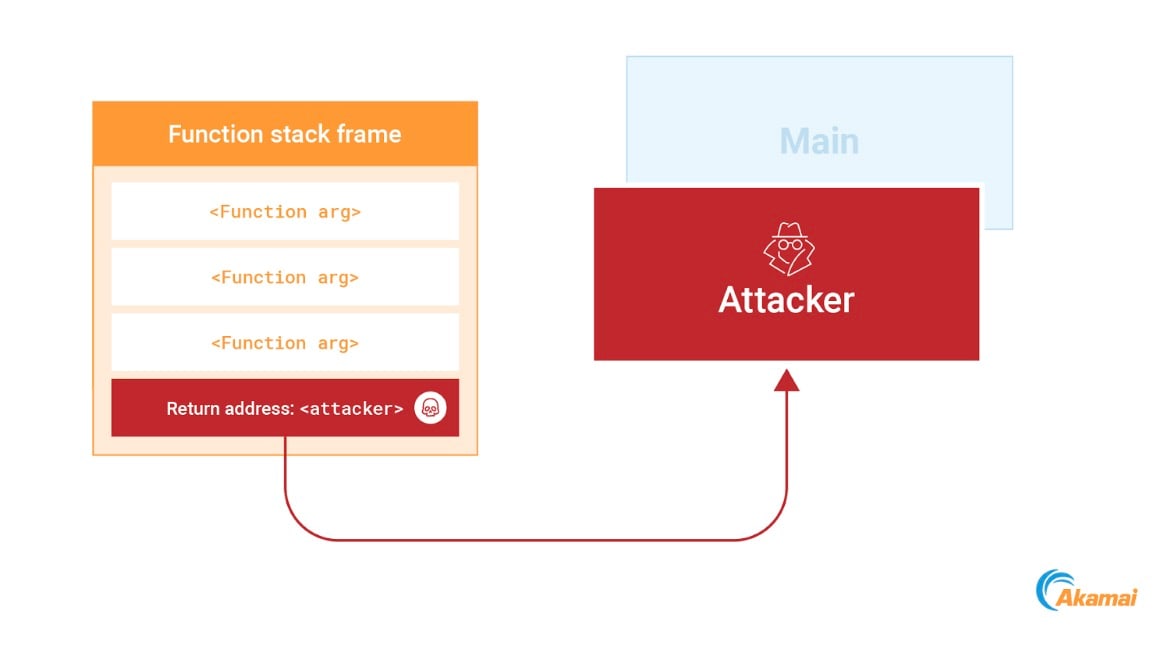 Fig. 13: Overwriting a return address on the stack to point to the attackers code
Fig. 13: Overwriting a return address on the stack to point to the attackers code
为了识别堆栈的顶部,我们可以解析前面提到的 procfs syscall 文件,其中还包含堆栈指针寄存器的值。
可以利用以下六个步骤来实施此技术:
发送 SIGSTOP 信号,以停止进程执行
解析 procfs syscall 文件,以识别进程的堆栈指针
扫描进程堆栈并识别返回地址
使用前面提到的任何写入基元,将攻击负载注入进程内存
将返回地址重写为攻击负载的地址
发送 SIGCONT 信号,以恢复进程执行
当前函数完成执行后,攻击负载就会得到执行。
所有进程交互方法都允许我们修改堆栈,因此全部可用于实施此技术。有关我们如何使用 process_vm_writev syscall 文件实施此技术的信息,可以 在我们的存储库中找到。
ROP 堆栈劫持
适用于:ptrace、procfs mem 文件、process_vm_writev
堆栈劫持技术让我们感兴趣的原因在于,它使我们能够劫持进程的执行流程,并且无需修改任何可执行内存或寄存器。尽管如此,为了使其能够发挥作用,我们仍然需要跳转到驻留在可执行内存区域中的 shellcode。我们可以尝试寻找 WX 区域(如前所述),也可以使用 ptrace/procfs mem 在不可写入的内存中写入数据。
但如果我们希望避开这些操作,又该怎么办呢?好吧,我们还有另一个秘密招术: 返回导向编程 (ROP)。既然我们拥有了写入进程堆栈的能力,就可以将其重写为一个 ROP 链(图 14)。由于我们依靠的是已经驻留在进程内存中的可执行小工具,因此可以在不编写任何新的可执行代码的情况下构建攻击负载。
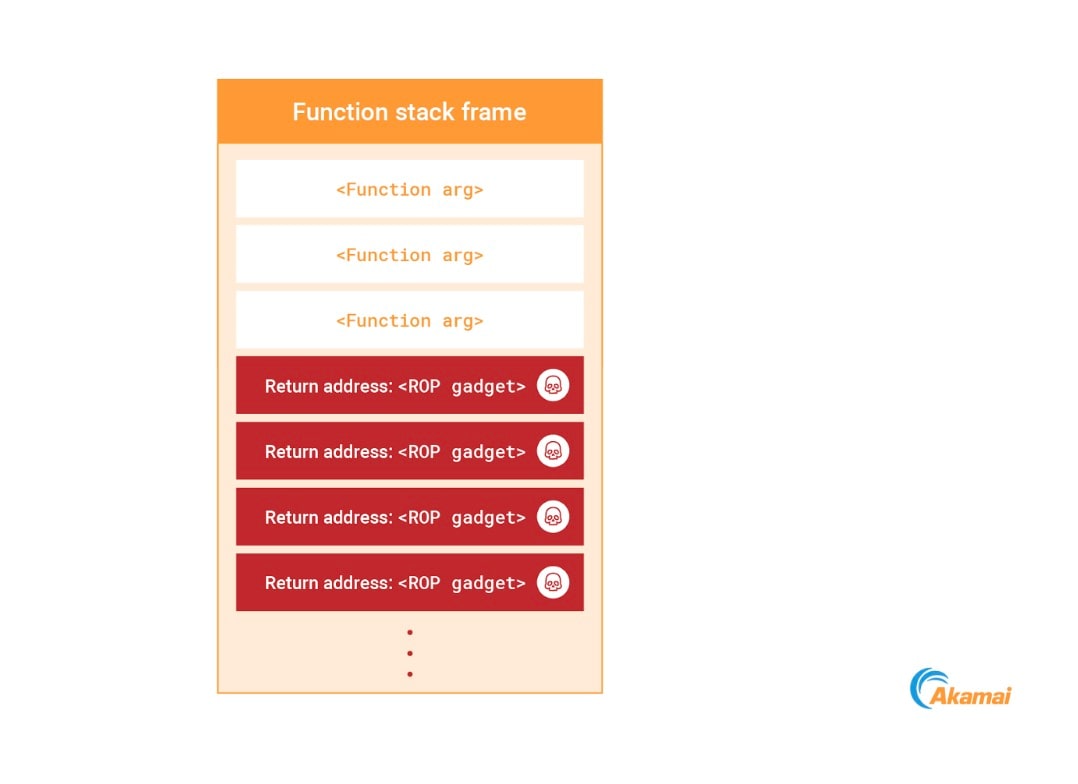 Fig. 14: Injecting a ROP chain to the process stack
Fig. 14: Injecting a ROP chain to the process stack
实施此技术的过程包含以下七个步骤:
发送 SIGSTOP 信号,以停止进程执行
解析 procfs syscall 文件,以识别进程的堆栈指针
扫描进程堆栈并识别返回地址
使用前面提到的任何写入基元,将攻击负载注入某个没有执行许可的可写入进程区域
构建一个 ROP 链以调用 mprotect ,然后将 shellcode 的内存区域标记为可执行
使用该 ROP 链重写堆栈,从已识别的返回地址开始
发送 SIGCONT 信号,以恢复进程执行
当前函数完成执行后,我们的 ROP 链就会执行,使 shellcode 变得可执行,然后跳转到该代码。
AON Cyber Labs 的 Rory McNamara 撰写了一篇介绍 procfs mem 注入的 博文 ,其中就包含了关于这一概念的描述。
这种技术不需要修改任何不可写的内存区域,因此可以使用所有进程交互技术来执行,包括 process_vm_writev。
立即了解 我们如何使用 process_vm_writev 实施此技术。据我们所知,这是首次公开展示仅依靠 process_vm_writev syscall 文件实施的注入技术。
GOT 劫持
适用于:ptrace、procfs mem 文件、process_vm_writev
还有一个通常可以写入的内存区段也让我们颇感兴趣,那就是 GOT。GOT 的全称是全局偏移表 (Global Offset Table),这是一个内存区段,用作动态链接 ELF 文件重定位过程的一部分。我们不会在这里予以详细说明,但会重点介绍与我们目的相关的部分,即用于存储程序所导入函数地址的区段。只要程序从远程库中调用函数,就会通过访问 GOT 来解析其内存地址(图 15)。
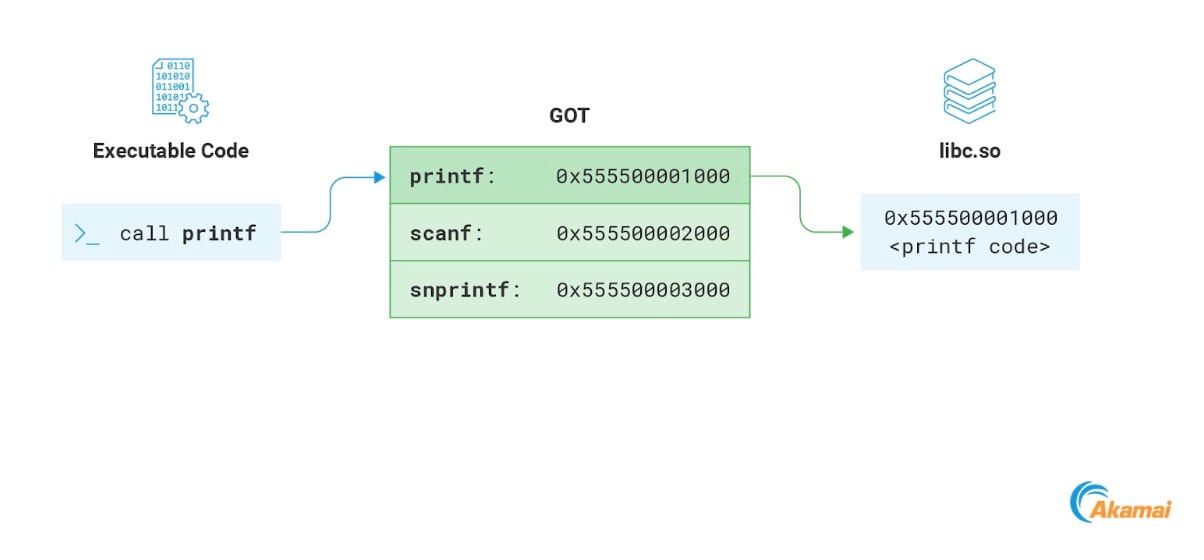 Fig. 15: Resolving a library function address using the GOT
Fig. 15: Resolving a library function address using the GOT
攻击者可以滥用此机制来劫持进程执行流程。GOT 内存通常可写入,这意味着攻击者可以将其中的任何地址重写为攻击负载的地址。当进程下一次调用该函数时,就会改为执行攻击者的代码(图 16)。
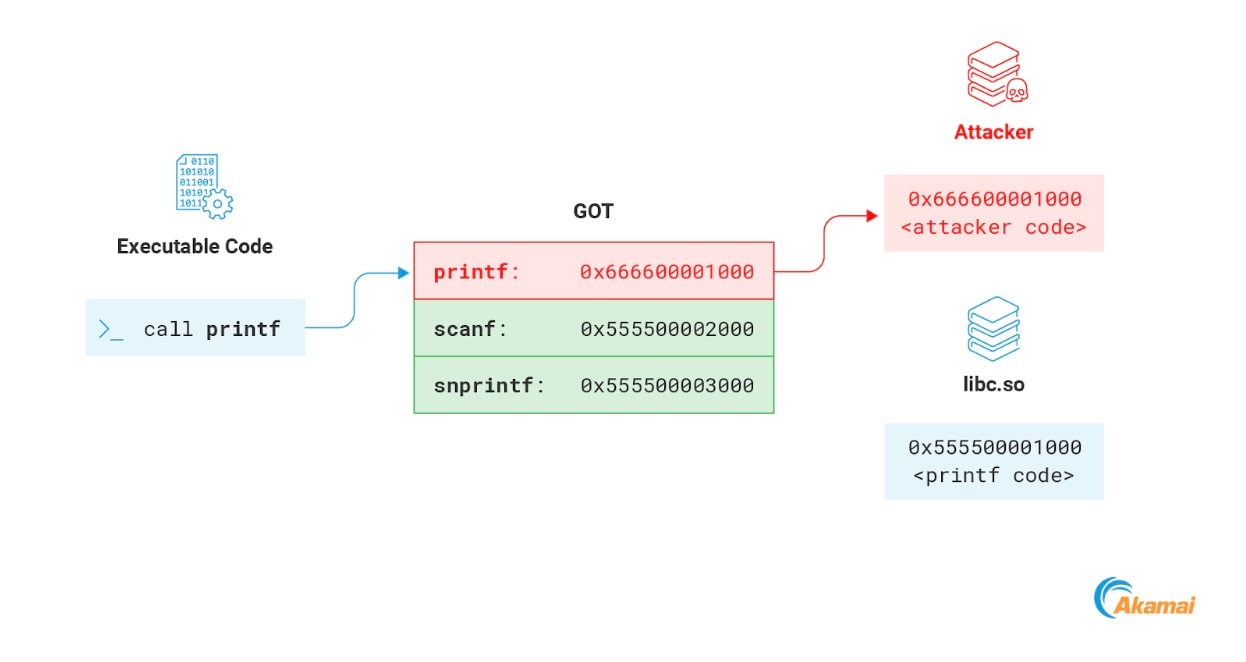 Fig. 16: Modifying a function in the GOT to point to the attacker payload
Fig. 16: Modifying a function in the GOT to point to the attacker payload
实施此技术的过程包含以下四个步骤:
发送 SIGSTOP 信号,以停止进程执行
解析 maps 文件,以识别 GOT 内存区域
将该区段中的地址重写为攻击负载的地址
发送 SIGCONT 信号,以恢复进程执行
当我们重写的任何函数被调用时,我们的攻击负载就会得到执行。
有一种内存保护技术可以影响这一攻击,那就是 full RELRO。如果使用此设置来编译二进制文件,会使 GOT 内存拥有只读许可,因而有可能阻止重写。
尽管如此,RELRO 在大多数情况下还是无法阻止这种攻击。
ptrace 和 procfs mem 可以绕过内存许可,让 RELRO 变得无计可施
RELRO 会影响进程二进制文件本身,但不会影响其已加载的库。如果进程加载任何未使用 RELRO 编译的库,其 GOT 将变得可写入,从而使我们能够对其进行重写
有关我们如何使用 process_vm_writev syscall 文件实施此技术的信息,可以 在我们的存储库中找到。
执行基元汇总
该表汇总介绍了我们描述的所有可能的执行基元,以及可以采用哪些方法来实施它们。
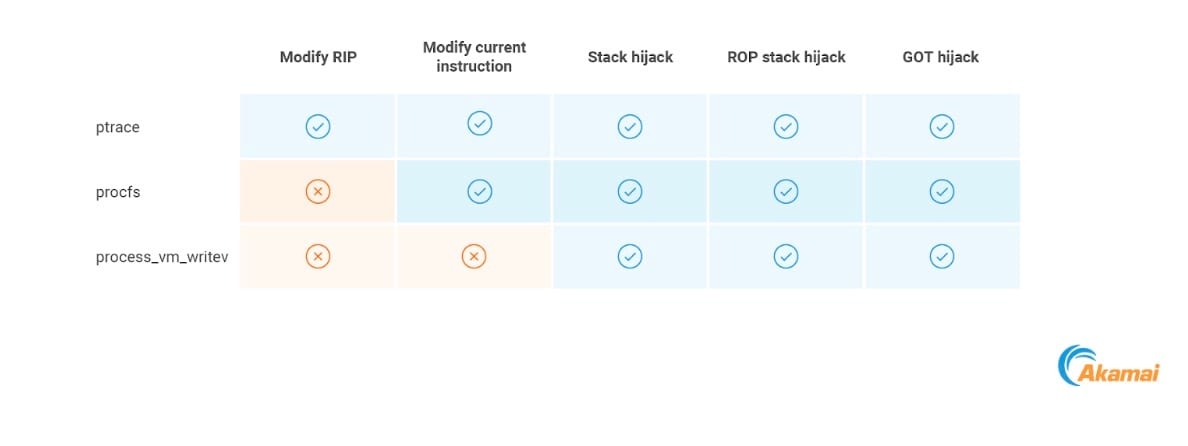 All the possible execution primitives and the methods that could be used to implement them
All the possible execution primitives and the methods that could be used to implement them
对远程进程交互的限制
有多个设置决定着我们是否能够使用刚才所述的方法与远程进程进行交互。在本部分中,我们将概要介绍其中的两个主要设置。
ptrace_scope
ptrace_scope 设置决定了允许谁在远程进程上使用 ptrace。它可以具有以下值:
0——进程可以连接至系统上的其他任何进程,只要它们具有相同的 UID。
1——正常进程只能连接至自己的子进程。特权进程(具有 CAP_SYS_PTRACE)仍然可以连接至不相关的进程。在许多系统发行版中,这是默认设置。
2——仅限于具有 CAP_SYS_PTRACE 的进程才能连接至其他进程。此能力通常仅授予给根用户。
3——禁止连接至远程进程。
尽管命名如此,但此设置也会影响访问远程进程上的 procfs mem 文件以及对其使用 process_vm_writev 的能力。
“dumpable”属性
关于进程恢复的一项说明
我们着重介绍过的所有注入方法都需要对进程状态进行某种方式的修改:修改进程寄存器,或者重写可执行内存、堆栈上的返回地址或 GOT。所有这些操作都会改变进程的正常执行流程,并在攻击负载执行完成后导致发生意外行为。
如果我们希望目标进程继续与注入的攻击负载一起运行,就会出现问题。为确保进程继续正常运行,我们需要恢复其原始状态。整个恢复流程由以下八个步骤组成:
使用一个远程读取基元,以备份我们想要重写的内存内容
备份进程寄存器的当前内容;此操作可以使用 ptrace 来执行,或者由我们的 shellcode 完成
执行我们的攻击负载,例如,加载一个在单独线程中运行代码的共享对象 (SO)
当攻击负载完成执行后,指示注入进程执行已完成;此操作可以通过发起中断来完成
暂停远程进程
恢复进程寄存器状态
恢复被重写的内存
恢复进程执行
详细实施情况将视所用的注入方法而略有不同,但整体过程应该并无区别。Adam Chester 在其撰写的 关于 Linux ptrace 注入的博文 中,提供了使用 ptrace 完成注入后的进程恢复详细示例。
我们发布这篇博文的目的是为了概要介绍注入技术,防御者可以通过阅读来熟悉这些技术,然后建立适当的检测机制。由于我们的重点是放在防御上,因此并没有选择详细介绍采用不同注入技术后的恢复步骤,而攻击者要做的是将这些技术转化为自己的攻击武器。
检测和抵御
正如我们刚才所讨论,有很多技术能够帮助攻击者在 Linux 机器上执行进程注入。对我们来说,幸运的是所有这些方法都需要执行异常操作,这就让我们有机会检测到攻击。后续部分将详细介绍在检测和抵御 Linux 上的进程注入攻击时,可以实施的不同策略。
“注入系统调用”
在本博文中,我们使用了三种方法与远程进程进行交互,即:ptrace、procfs 和 process_vm_writev。由于这些方法都有可能被恶意使用,因此都应该受到监控。
一开始是在 Linux 机器上安装日志记录解决方案。通过使用基于 eBPF 的日志记录实用程序,可以启用系统调用执行监控。此类实用程序的示例包括 Sysmon for Linux 或 Aqua Security 的 Tracee (已 实施规则 以涵盖本博文中所述的诸多技术)。
建立日志记录之后,我们建议企业对其环境中的“注入系统调用”正常使用情况进行分析,并建立已知有效用例的基准。创建此类基准之后,任何偏离基准的情况都应该得到调查,以排除潜在的攻击。在后续部分中,还介绍了其他一些涉及系统调用的考虑因素。
理想情况下,应该尽可能使用 ptrace_scope 以限制使用这些系统调用,甚至是完全阻止使用。
ptrace
在大多数生产环境中,似乎很少会使用 ptrace 系统调用。在为有效的 ptrace 使用情况建立基准之后,我们建议对任何异常的 ptrace 使用情况进行分析。
以下 ptrace 请求允许修改远程进程,应该引起高度怀疑:
POKEDATA/POKETEXT
POKEUSER
SETREGS
procfs
有一些合法的用例需要写入 procfs mem 文件,但这种行为或许并不常见。在为有效用例建立基准之后,我们建议对任何异常的写入操作进行分析。
此外,务必还要考虑 /proc/<pid>/task procfs 目录。此目录会暴露进程的不同线程的相关信息。每个线程都将有自己的 procfs 目录,其中包含我们介绍过的所有主要 procfs 文件,例如 mem、maps 和 syscall 文件。
在图 17 中可以看到,从 /proc/<pid> 目录中读取 syscall 文件与从 /proc/<pid>/task/<pid> 目录中读取的效果相同,而后者包含进程的主线程。
 Fig. 17: Example of using the /proc/<pid>/task directory
Fig. 17: Example of using the /proc/<pid>/task directory
process_vm_writev
再说一次,通过为此系统调用的合法用例建立基准,可以识别异常的偏离基准情况。如有任何未知的进程在其他进程的内存中写入数据,则应视为可疑情况并进行相应分析。
检测进程异常情况
除了直接检测进程注入之外,我们还可以尝试检测其有何副作用。当代码被注入远程进程时,它将改变自己的行为方式。除了进程采取的正常操作之外,攻击负载的操作现在也会由相同的进程来执行。
正是由于这种行为上的变化,让我们有机会检测到攻击。通过为正常进程行为建立基准,可以识别偏离此基准的可疑情况,而这可能表示发生了代码注入攻击。此类行为的一些示例包括:衍生出异常的子进程、加载之前未曾见过的 SO 文件,或者通过异常的端口进行通信。
Akamai 研究人员 记录了这一方法 ,并且展示了如何通过分析网络异常情况来识别代码注入攻击。
总结
在针对 Linux 机器执行注入攻击时,攻击者拥有多种不同的方法可以选择。这些技术虽然对攻击者来说极为有用,但也为防御者提供了宝贵的检测机会。通过在 Linux 机器上部署牢固的日志记录和检测功能,企业可以显著改善自己的安全态势。
