
La guida definitiva agli attacchi di iniezione dei processi in Linux


Introduzione
Le tecniche di iniezione dei processi svolgono un ruolo importante nel set di strumenti utilizzati dai criminali con cui possono eseguire codice dannoso all'interno di un processo legittimo per evitare il rilevamento o posizionare delle "esche" nei processi remoti per modificare il loro comportamento.
L'iniezione dei processi sui computer Windows è stato un argomento ampiamente discusso ed è ora adeguatamente conosciuto. Per i sistemi Linux, non si può dire lo stesso. Anche se sono state scritte eccellenti risorse su questo argomento ,la consapevolezza delle varie tecniche di iniezione in Linux sembra essere relativamente scarsa rispetto a quella di Windows.
Abbiamo tratto ispirazione da una panoramica sugli attacchi di iniezione dei processi in Windows scritta da Amit Klein e Itzik Kotler di SafeBreach, che mira a fornire una documentazione completa su questo argomento in Linux. Esamineremo le tecniche utilizzate negli attacchi di iniezione dei processi che prendono di mira i processi in esecuzione, quindi escluderemo i metodi che richiedono la modifica dei file binario sul disco, l'esecuzione dei processi con specifiche variabili di ambienteo l'abuso del caricamento dei processi.
Descriveremo le funzioni del sistema operativo che facilitano gli attacchi di iniezione dei processi in Linux e le varie primitive di iniezione consentite, oltre alle tecniche descritte in precedenza e alcune varianti degli attacchi di iniezione mai documentate in precedenza. Concluderemo con la descrizione delle strategie di rilevamento e mitigazione per le tecniche in questione.
Oltre a questo blog, stiamo pubblicando un archivio GitHub contenente una serie completa di codici PoC (Proof-of-Concept) per le diverse primitive di iniezione descritte nel post. Queste PoC sono utili per comprendere le caratteristiche di un'implementazione dannosa delle tecniche, che possono aiutarvi a realizzare e a testare le funzionalità di rilevamento. Per ulteriori informazioni, potete consultare il documento LEGGIMI del progetto.
Iniezione: confronto tra Linux e Windows
Il numero di tecniche di iniezione note sui computer Windows è enorme e continua a crescere, dalle code APC e dalle transazioni NTFS alle tabelle Atom e ai pool di thread. Windows espone molte interfacce che consentono ai criminali di interagire con i processi remoti (e iniettarvi codice).
La situazione è molto diversa nel regno di Linux. L'interazione con i processi remoti è limitata ad una serie ridotta di chiamate di sistema e molte funzioni che facilitano l'iniezione sui computer Windows non si trovano da nessun'altra parte. Non esistono API per l'allocazione della memoria in un processo remoto o la modifica della protezione della memoria remota e, sicuramente, per la creazione di thread remoti.
Questa differenza influisce sulla struttura dell'attacco di iniezione. In Windows, l'attacco di iniezione dei processi, solitamente, è costituito da tre fasi: allocazione → scrittura → esecuzione. Innanzitutto, la memoria viene allocata nel processo remoto da utilizzare per archiviare il codice, quindi il codice viene scritto nella memoria e, infine, viene eseguito.
In Linux, non esiste la possibilità di eseguire la prima fase: l'allocazione, quindi non c'è un modo diretto per allocare la memoria in un processo remoto. Pertanto, il flusso dell'operazione di iniezione è leggermente diverso poiché è costituito dalle seguenti fasi: sovrascrittura → esecuzione→ ripristino. La memoria esistente viene sovrascritta nel processo remoto con il nostro payload, viene eseguita e, infine, viene ripristinato lo stato precedente del processo per consentirne la normale esecuzione.
Metodi di interazione con il processo remoto
In Linux, l'interazione con la memoria dei processi remoti è limitata a tre metodi principali: ptrace, procfse process_vm_writev. Le sezioni riportate di seguito forniscono brevi descrizioni di ciascuno di essi.
ptrace
ptrace è una chiamata di sistema utilizzata per eseguire il debug dei processi remoti. Il processo iniziale è in grado di esaminare e modificare la memoria e i registri dei processi sottoposti a debug. Vengono implementati debugger come GDB tramite ptrace per controllare il processo sottoposto a debug.
ptrace supporta varie operazioni, che sono specificate da un codice di richiesta ptrace, di cui alcuni degli esempi più noti sono: PTRACE_ATTACH (che viene allegato ad un processo), PTRACE_PEEKTEXT (che esegue la lettura dalla memoria del processo) e PTRACE_GETREGS (che recupera i registri del processo). Il frammento 1 mostra un esempio dell'utilizzo di ptrace.
// Attach to the remote process
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// Get registers state
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
Frammento 1. Esempio dell'utilizzo di ptrace per recuperare i registri di un processo remoto
procfs
procfs è uno pseudo-filesystem speciale che funge da interfaccia per i processi in esecuzione sul sistema ed è accessibile tramite la directory /proc (Figura 1).
 Fig. 1: A directory listing of the /proc directory on a Linux machine
Fig. 1: A directory listing of the /proc directory on a Linux machine
Ogni processo viene rappresentato da una directory denominata in base al suo PID. In questa directory, potete trovare i file che forniscono informazioni sul processo. Ad esempio, nel file cmdline si trova la riga di comando del processo, il file environ contiene le variabili dell'ambiente del processo e così via.
Il file procfs consente anche di interagire con la memoria del processo remoto. All'interno della directory di ogni processo, si trova il file mem , un file speciale che rappresenta l'intero spazio degli indirizzi del processo. L'accesso al file mem di un processo in un particolare offset equivale ad accedere alla memoria del processo allo stesso indirizzo.
Nell'esempio in Figura 2, abbiamo usato l'utilità xxd per leggere 100 byte dal file mem del processo, a partire da un offset specificato.
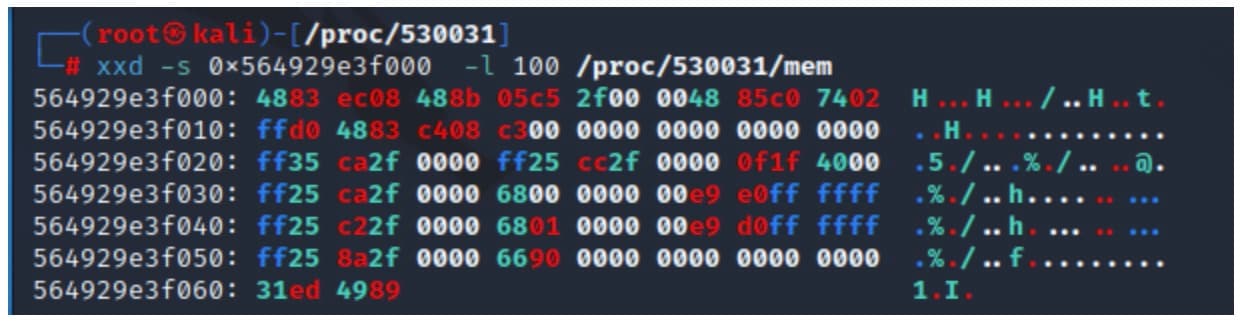 Fig. 2: Using xxd to read the procfs mem file
Fig. 2: Using xxd to read the procfs mem file
Se esaminiamo lo stesso indirizzo nella memoria tramite GDB, notiamo che i contenuti sono identici (Figura 3).
 Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
Il file maps è un altro file interessante che si trova nella directory del processo (Figura 4). Questo file contiene informazioni sulle diverse aree della memoria nello spazio degli indirizzi del processo, inclusi i relativi intervalli degli indirizzi e le autorizzazioni della memoria.
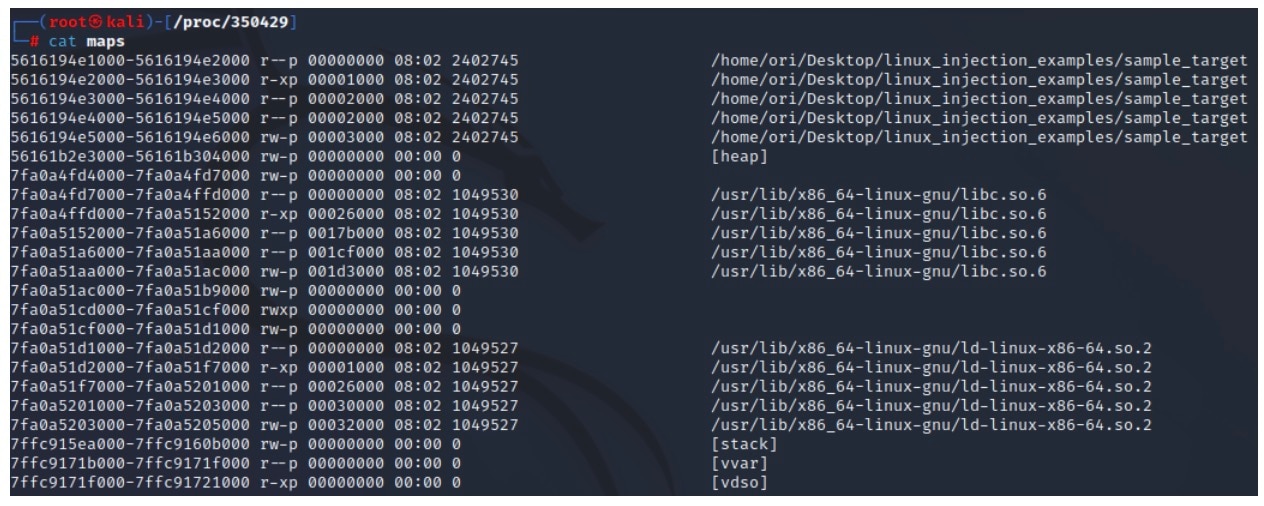 Fig. 4: Example contents of a process maps file
Fig. 4: Example contents of a process maps file
Nelle sezioni successive, vedremo come possa risultare estremamente utile identificare le aree della memoria con specifiche autorizzazioni.
process_vm_writev
Il terzo metodo di interazione con la memoria del processo remoto è la chiamata di sistema process_vm_writev, che consente di scrivere i dati nello spazio degli indirizzi di un processo remoto.
La chiamata process_vm_writev riceve un puntatore su un buffer locale e ne copia il contenuto in un indirizzo specificato all'interno del processo remoto. Un esempio della chiamata process_vm_writev in uso viene mostrato nel frammento 2.
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our data in the local iovec
local[0].iov_base = data;
local[0].iov_len = data_len;
// Point the remote iovec to the address in the remote process
remote[0].iov_base = (void *)remote_address;
remote[0].iov_len = data_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
Frammento 2. Utilizzo della chiamata process_vm_writev per scrivere i dati in un processo remoto
Scrittura del codice in un processo remoto
Una volta compresi i diversi metodi di interazione con gli altri processi, vediamo ora come vengono usati per eseguire l'iniezione di codice. La prima fase di un attacco di iniezione consiste nello scrivere lo shellcode nella memoria del processo remoto. Come detto in precedenza, in Linux non c'è un modo diretto per allocare nuova memoria in un processo remoto, Quindi non è possibile creare una nuova sezione di memoria, ma è necessario utilizzare la memoria esistente del processo in questione.
Per eseguire il codice, è necessario scriverlo in un'area di memoria con autorizzazioni di esecuzione, che si trova analizzando il file siquestprocfs citato in precedenza e identificando un'area della memoria con (x) autorizzazione di esecuzione (Figura 5).
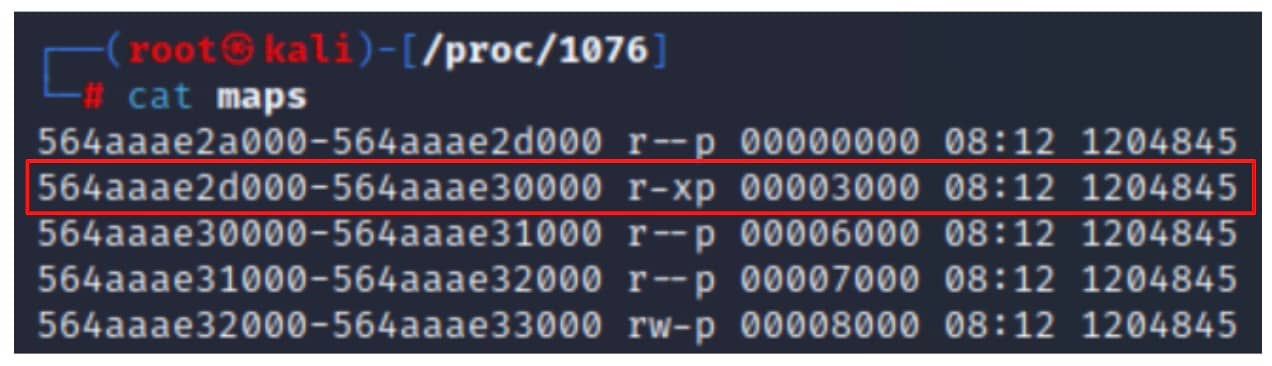 Fig. 5: Identifying an executable memory region in the process maps file
Fig. 5: Identifying an executable memory region in the process maps file
Esistono due tipi di aree eseguibili che si possono incontrare: scrivibili e non scrivibili. Le sezioni riportate di seguito mostrano quando e come poter utilizzare ciascuno di esse.
Scrittura del codice nella memoria RX
Applicabile a: ptrace, procfs mem
Idealmente, dobbiamo identificare un'area della memoria con autorizzazioni di scrittura ed esecuzione, che ci consente di scrivere il codice e di eseguirlo. In realtà, la maggior parte dei processi non dispone di un'area con autorizzazioni di questo tipo perché l'allocazione della memoria WX è considerata una cattiva abitudine. Al contrario, di solito, le autorizzazioni sono limitate alla lettura e all'esecuzione.
L'aspetto interessante consiste nel fatto che questa limitazione può essere aggirata tramite i due metodi appena descritti: ptrace e procfs mem. Entrambi questi meccanismi vengono implementati in modo che possano bypassare le autorizzazioni della memoria e scrivere su qualsiasi indirizzo, anche senza autorizzazioni di scrittura. Ulteriori dettagli su questo comportamento che riguarda il file procfs sono disponibili in questo blog.
Pertanto, indipendentemente dalle autorizzazioni di scrittura, possiamo sempre utilizzare il file ptrace o procfs mem per scrivere il codice in un'area della memoria eseguibile da remoto.
ptrace
Per scrivere il payload in un processo remoto, possiamo utilizzare le richieste POKETEXT o POKEDATA: queste richieste identiche consentono di scrivere una parola di dati nella memoria del processo remoto. Richiamando ripetutamente queste richieste, possiamo copiare l'intero payload nella memoria del processo in questione. Un esempio di questa operazione viene mostrato nel frammento 3.
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// write payload to remote address
for (size_t i = 0; i < payload_size; i += 8, payload++)
{
ptrace(PTRACE_POKETEXT, pid, address + i, *payload);
}
Frammento 3. Utilizzo della chiamata ptrace POKETEXT per scrivere il payload nella memoria del processo remoto
procfs mem
Per scrivere il payload in un processo remoto tramite procfs, dobbiamo semplicemente scriverlo nel file mem all'offset corretto. Eventuali modifiche apportate al file mem vengono applicate alla memoria del processo. Per eseguire queste operazioni, possiamo usare le API del file normale (frammento 4).
// Open the process mem file
FILE *file = fopen("/proc/<pid>/mem", "w");
// Set the file index to our required offset, representing the memory address
fseek(file, address, SEEK_SET);
// Write our payload to the mem file
fwrite(payload, sizeof(char), payload_size, file);
Frammento 4. Utilizzo del file procfs mem per scrivere i dati nella memoria di un processo remoto
Scrittura del codice nella memoria WX
Applicabile a: ptrace, procfs mem, process_vm_writev
Come abbiamo detto in precedenza, entrambi i file ptrace e procfs mem bypassano le autorizzazioni della memoria e ci consentono di scrivere il codice nelle aree delle memoria non scrivibili. La situazione, invece, è diversa con il file process_vm_writev, che dispone delle autorizzazioni della memoria e, quindi, ci consente solo di scrivere i dati nelle aree della memoria scrivibili.
Pertanto, possiamo soltanto individuare le aree scrivibili. Non tutti i processi contengono aree di questo tipo, tuttavia, possiamo sicuramente cercare processi in cui siano incluse.
Il comando riportato nel frammento 5 esamina il file maps di tutti i processi esistenti nel sistema e identifica le aree con autorizzazioni di scrittura ed esecuzione (Figura 6).
find /proc -type f -wholename "*/maps" -exec grep -l "wx" {} +
Frammento 5. Utilizzo del comando "find" per identificare i processi con aree di memoria con autorizzazioni di scrittura ed esecuzione
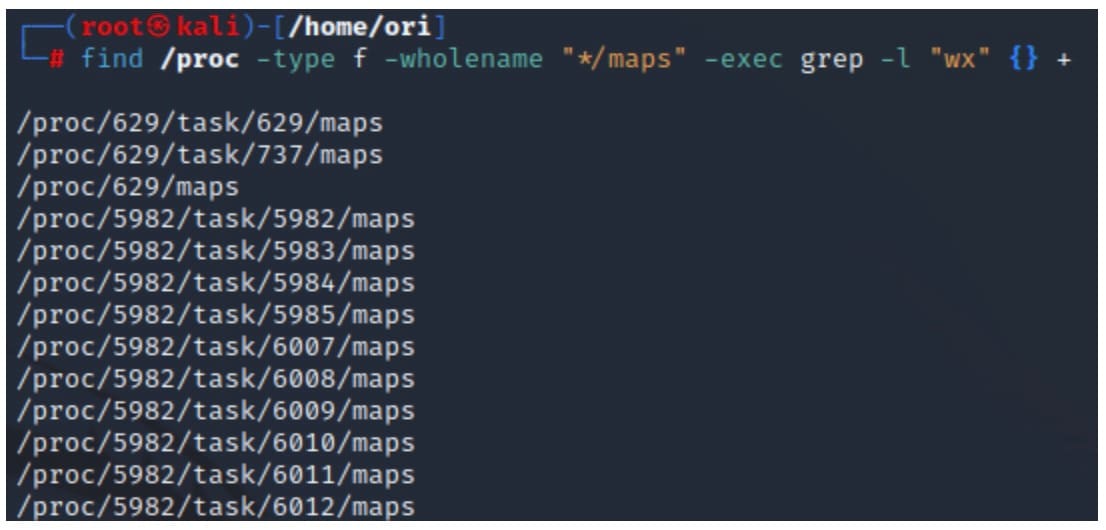 Fig. 6: Example output of finding processes with WX memory regions
Fig. 6: Example output of finding processes with WX memory regions
Dopo aver identificato un'area di questo tipo, possiamo scrivere il codice nel file process_vm_writev (frammento 6).
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our payload in the local iovec
local[0].iov_base = payload;
local[0].iov_len = payload_len;
// Point the remote iovec to the address of our wx memory region
remote[0].iov_base = (void *)wx_address;
remote[0].iov_len = payload_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
Frammento 6. Utilizzo del file process_vm_writev per scrivere i dati in un'area WX remota
Dirottamento del flusso di esecuzione remota
Dopo aver scritto il codice nella memoria del processo remoto, dobbiamo eseguirlo. Nelle sezioni riportate di seguito, descriveremo le varie tecniche che possiamo utilizzare per eseguire questa operazione.
Nella nostra ricerca, ci siamo concentrati sui computer amd64. Altre architetture potrebbero presentare alcune piccole differenze, ma i concetti generali rimangono invariati.
Modifica del puntatore delle istruzioni del processo
Applicabile a: ptrace
Quando ci colleghiamo ad un processo tramite ptrace, la sua esecuzione viene messa in pausa, pertanto possiamo esaminare e modificare i registri del processo, incluso il puntatore delle istruzioni, tramite le richieste SETREGS e GETREGS ptrace. Per modificare il flusso di esecuzione del processo, possiamo usare il file ptrace per modificare il puntatore delle istruzioni nell'indirizzo dello shellcode.
Nell'esempio riportato nel frammento 7, abbiamo eseguito i tre passaggi seguenti:
Recupero dei valori attuali del registro tramite la richiesta GETREGS ptrace
Modifica del puntatore delle istruzioni per farlo puntare all'indirizzo del nostro payload (con incrementi di 2, di cui parleremo più avanti)
Applicazione della modifica apportata al processo tramite la richiesta SETREGS
// Get old register state.
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
// Modify the instruction pointer to point to our payload
regs.rip = payload_address + 2;
// Modify the registers
ptrace(PTRACE_SETREGS, pid, NULL, ®s);
Frammento 7. Utilizzo della richiesta ptrace SETREGS per modificare il puntatore delle istruzioni sul nostro payload
La richiesta SETREGS è il modo "tradizionale" e più documentato per modificare i registri del processo, tuttavia, per eseguire questa operazione, è possibile usare anche un'altra richiesta ptrace: POKEUSER.
La richiesta POKEUSER consente di scrivere i dati nell'area USER del processo , una struttura (definita in sys/user.h) che contiene informazioni sul processo, inclusi i registri. Richiamando la richiesta POKEUSER con l'offset corretto, possiamo sovrascrivere il puntatore delle istruzioni con l'indirizzo del nostro codice e ottenere lo stesso risultato dell'operazione precedente (frammento 8).
// calculate the offset of the RIP register, based on the USER struct definition
rip_offset = 16 * sizeof(unsigned long);
ptrace(PTRACE_POKEUSER, pid, rip_offset, payload_address + 2);
Frammento 8. Utilizzo della richiesta ptrace POKEUSER per modificare il puntatore delle istruzioni sul nostro payload
L'implementazione che prevede l'utilizzo della richiesta POKEUSER per modificare il RIP si trova nel nostro archivio.
RIP += 2: quando e perché?
Come mostrato nei frammenti 7 e 8, quando si modifica il RIP con l'indirizzo del nostro payload, si registra un incremento di 2 unità per consentire il verificarsi di un interessante comportamento ptrace , anche se, a volte, dopo aver effettuato la disconnessione da un processo con ptrace, il valore del RIP diminuisce di 2 unità. Cerchiamo di capire come mai si verifica questa situazione.
Quando ci colleghiamo ad un processo tramite ptrace, possiamo interrompere una chiamata di sistema che viene attualmente eseguita nel kernel. Per assicurarsi di eseguire correttamente la chiamata di sistema, il kernel la riesegue quando viene effettuata la disconnessione dal processo.
Durante l'esecuzione della chiamata di sistema, il RIP punta già alla successiva istruzione da effettuare. Per rieseguire la chiamata di sistema, il kernel diminuisce il valore del RIP di 2 unità, ossia le dimensioni dell'istruzione della chiamata di sistema nei computer amd64. Dopo questa modifica, il RIP punterà nuovamente all'istruzione della chiamata di sistema, forzando nuovamente l'esecuzione un'altra volta (Figura 7).
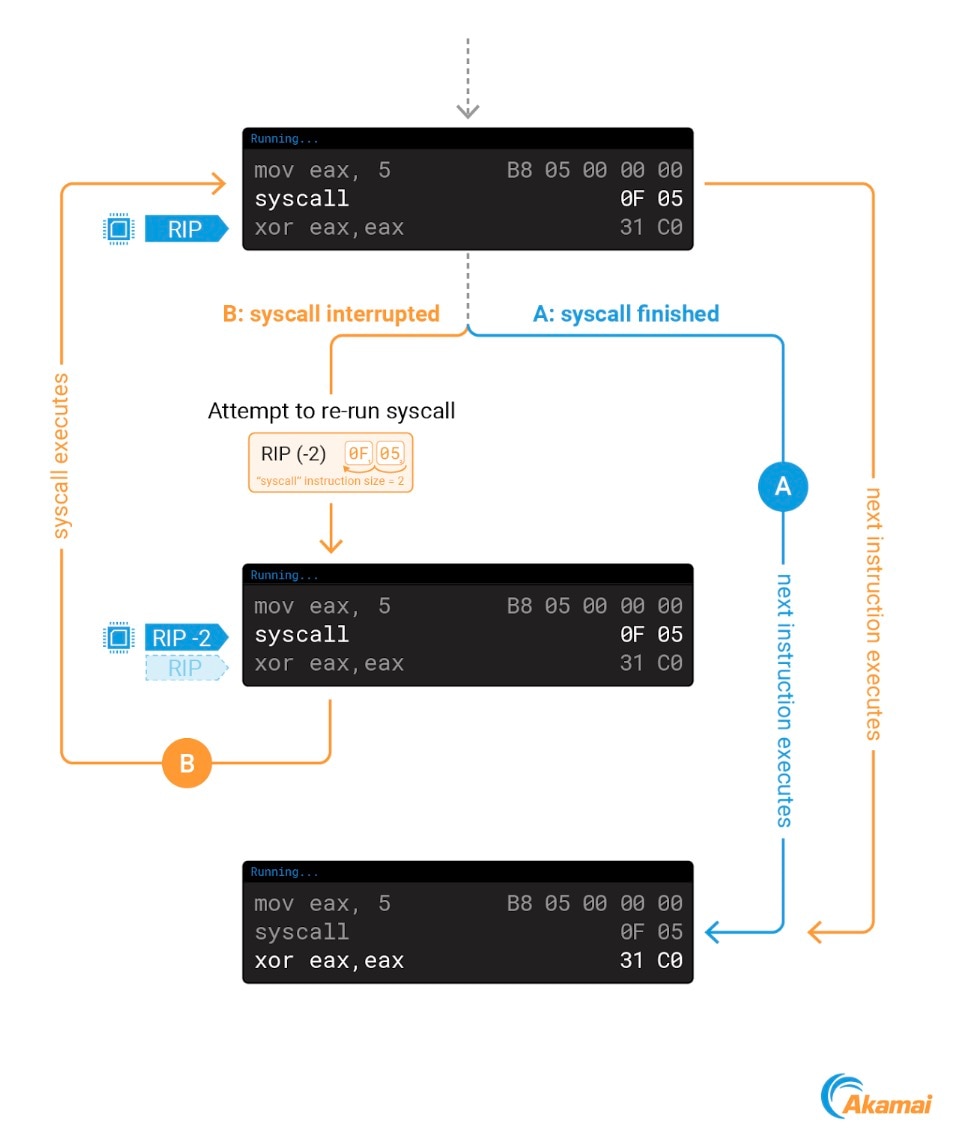 Fig. 7: The effect of using ptrace on a process during syscall execution
Fig. 7: The effect of using ptrace on a process during syscall execution
Se si interrompe un processo durante una chiamata di sistema quando viene eseguita un'iniezione di codice, si possono verificare problemi. Dopo aver modificato il RIP in modo da puntare al nostro codice, il kernel diminuisce comunque il nuovo valore di 2 unità in modo da lasciare un margine di 2 byte prima del nostro shellcode, il che ne potrebbe impedire il corretto funzionamento (Figura 8).
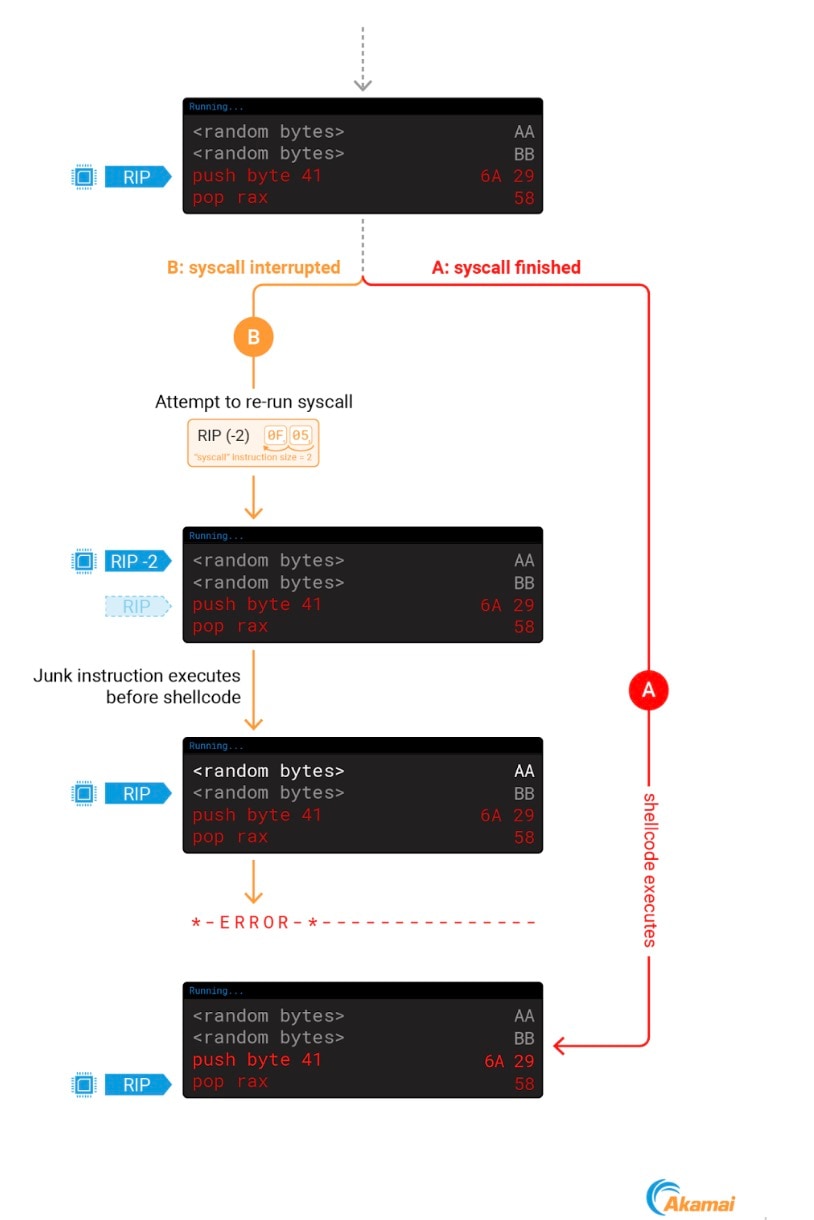 Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Per consentire il verificarsi di questo comportamento, è necessario eseguire due operazioni: inserire un prefisso al nostro shellcode con due istruzioni NOP (No Operation) e puntare il RIP all'indirizzo del nostro shellcode + 2. Queste due operazioni assicurano il corretto funzionamento del nostro codice.
Se si interrompe il processo durante una chiamata di sistema, il kernel diminuisce il nuovo valore RIP, facendolo puntare all'indirizzo iniziale dello shellcode che contiene due operazioni NOP nel nostro codice effettivo.
Se non si interrompe il processo durante una chiamata di sistema, il nuovo RIP non verrà diminuito, pertanto le due operazioni NOP verranno ignorate e il nostro codice verrà eseguito. Questi 2 casi sono illustrati in Figura 9.
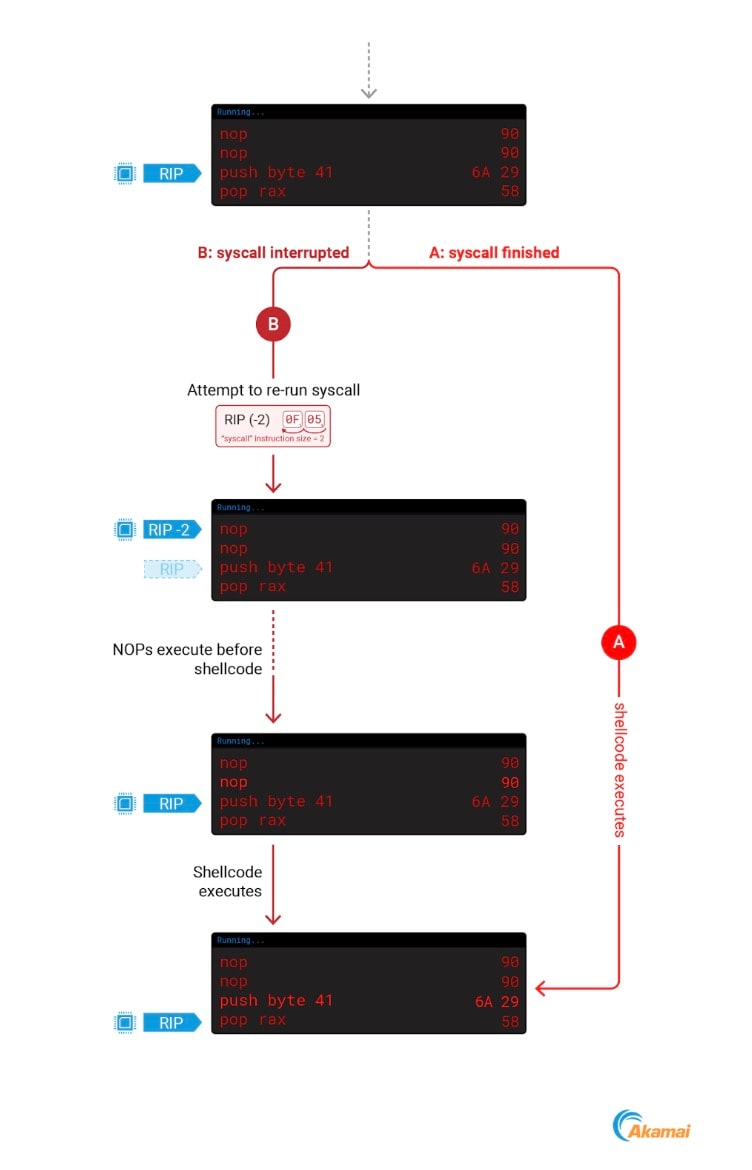 Fig. 9: Overcoming the ptrace RIP interaction
Fig. 9: Overcoming the ptrace RIP interaction
Modifica dell'istruzione corrente
Applicabile a: ptrace, procfs mem
Un altro file interessante in procfs è il file syscall, che contiene le seguenti informazioni sulla chiamata di sistema attualmente eseguita dal processo: numero della chiamata di sistema, argomenti passati alla chiamata di sistema, puntatore dello stack e, soprattutto per il nostro scopo, il puntatore dell'istruzione del processo (Figura 10). Anche se il processo non esegue attualmente una chiamata di sistema, i puntatori dello stack e dell'istruzione del processo sono comunque presenti nel file syscall.
 Fig. 10: The structure of the procfs syscall file
Fig. 10: The structure of the procfs syscall file
Queste informazioni possono consentire di assumere il controllo sul flusso di esecuzione del processo; sapere l'indirizzo della successiva istruzione da eseguire consente di sovrascriverlo con le nostre istruzioni.
Per effettuare questa implementazione, un criminale può eseguire le quattro operazioni seguenti:
Fermare l'esecuzione del processo inviando un segnale SIGSTOP
Identificare l'indirizzo della successiva istruzione da eseguire leggendo il file syscall del processo
Scrivere lo shellcode nell'indirizzo identificato
Riprendere l'esecuzione del processo inviando un segnale SIGCONT
Il frammento 9 fornisce uno pseudo-codice per questo processo.
// Suspend the process by sending a SIGSTOP signal
kill(pid, SIGSTOP);
// Open the syscall file
FILE *syscall_file = fopen("/proc/<pid>/syscall", "r");
// Extract the instruction pointer from the syscall file
long instruction_pointer = ...
// Write our payload to the address of the current instruction pointer using
procfs mem
FILE *mem_file = fopen("/proc/<pid>/mem", "w");
fseek(mem_file, instruction_pointer, SEEK_SET);
fwrite(payload, sizeof(char), payload_size, mem_file);
// Resume execution by sending a SIGCONT signal
kill(pid, SIGCONT);
Frammento 9. Utilizzo del file procfs mem per modificare la memoria di processo all'indirizzo corrente del puntatore dell'istruzione per dirottare il flusso dell'esecuzione del processo
Nell'esempio riportato nel frammento 9, viene implementata questa tecnica tramite l'utilizzo del file procfs, tuttavia è importante notare che è possibile usare anche la richiesta ptrace POKETEXT per scrivere il payload nella memoria.
Come abbiamo già detto in precedenza, il file process_vm_writev dispone di autorizzazioni di memoria limitate, quindi è possibile modificare solo le aree di memoria scrivibili. La probabilità di individuare codice in esecuzione in un'area di memoria WX è scarsa, il che riduce l'affidabilità del file process_vm_writev per questa primitiva.
Date un'occhiata alla nostra implementazione di questa tecnica tramite il file procfs mem.
Dirottamento dello stack
Applicabile a: ptrace, file procfs mem, process_vm_writev
Un'altra area di memoria interessante è lo stack del processo, che può essere identificato anche tramite il file maps. Anche se la memoria dello stack non è eseguibile (Figura 11), è comunque possibile utilizzarla per dirottare il flusso dell'esecuzione del processo.
 Fig. 11: Identifying the process stack address using the maps file
Fig. 11: Identifying the process stack address using the maps file
Quando viene richiamata una funzione, l'indirizzo di ritorno della funzione di richiamata viene inoltrato allo stack. Una volta completata l'esecuzione della funzione, il processore ricava questo indirizzo di ritorno dallo stack e vi accede (Figura 12).
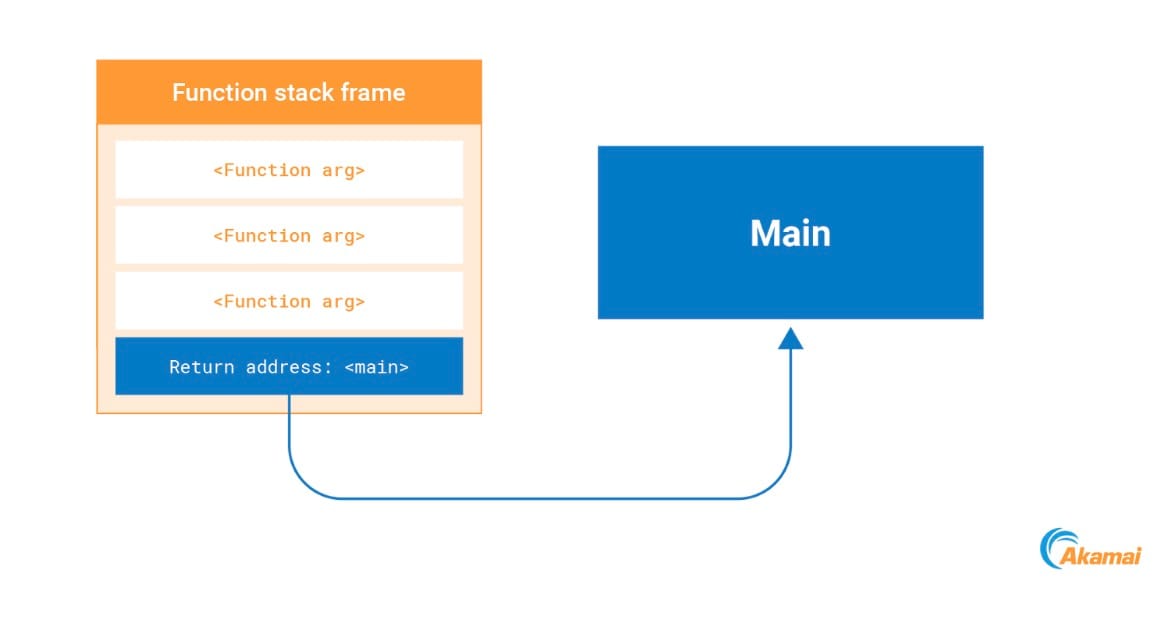 Fig. 12: Return address on the stack pointing to an address in main
Fig. 12: Return address on the stack pointing to an address in main
Per abusare di questo meccanismo, è possibile identificare un indirizzo di ritorno sullo stack e sovrascriverlo con un nuovo indirizzo che punta al nostro shellcode. Non appena viene completata l'esecuzione della funzione corrente, il nostro codice viene eseguito (Figura 13).
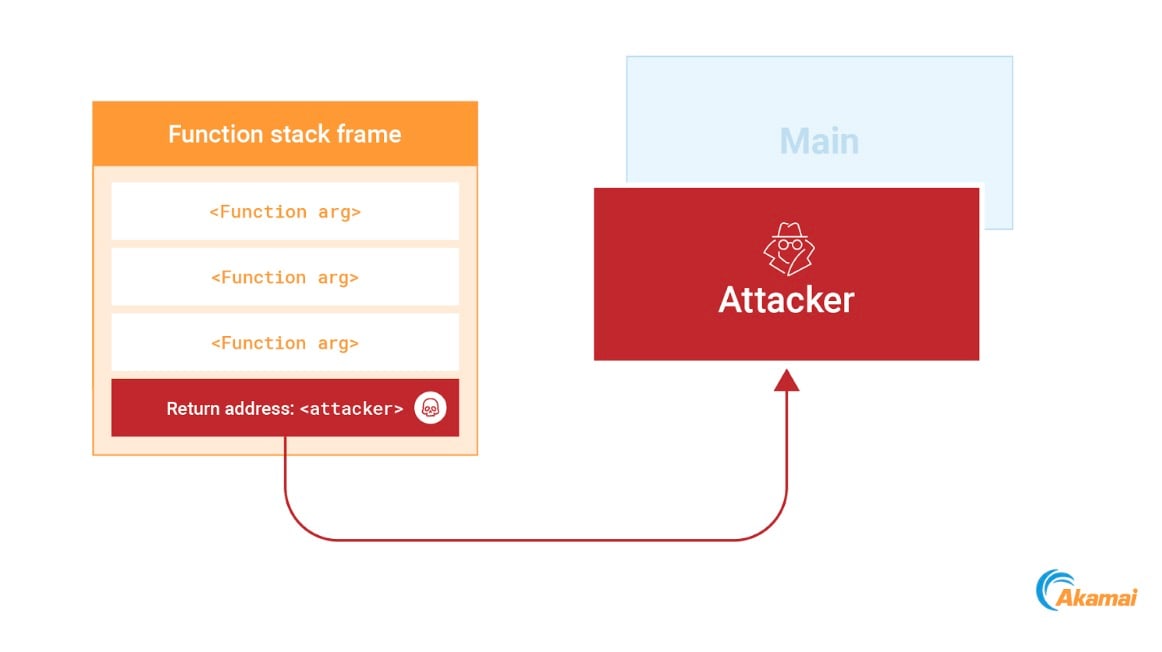 Fig. 13: Overwriting a return address on the stack to point to the attackers code
Fig. 13: Overwriting a return address on the stack to point to the attackers code
Per identificare l'inizio dello stack, è possibile analizzare il file syscall in procfs di cui abbiamo parlato in precedenza, che contiene anche il valore del registro del puntatore dello stack.
Per eseguire questa tecnica, è possibile effettuare le sei operazioni seguenti:
Fermare l'esecuzione del processo inviando un segnale SIGSTOP
Identificare il puntatore dello stack del processo analizzando il file syscall in procfs
Esaminare lo stack del processo e identificare un indirizzo di ritorno
Utilizzare le primitive di scrittura citate in precedenza per iniettare il nostro payload nella memoria del processo
Sovrascrivere l'indirizzo di ritorno con l'indirizzo del nostro payload
Riprendere l'esecuzione del processo inviando un segnale SIGCONT
Una volta completata l'esecuzione della funzione corrente, viene eseguito il nostro payload.
Poiché tutti i metodi di interazione del processo consentono di modificare lo stack, possono essere usati per implementare questa tecnica. L'implementazione di questa tecnica tramite il file process_vm_writev syscall si trova nel nostro archivio.
Dirottamento dello stack ROP
Applicabile a: ptrace, file procfs mem, process_vm_writev
La tecnica di dirottamento dello stack è interessante perché consente di dirottare il flusso di esecuzione del processo senza modificare alcuna memoria o registro eseguibile. Nonostante ciò, per poterlo utilizzare, è necessario passare allo shellcode che risiede in un'area di memoria eseguibile. Possiamo tentare di individuare un'area WX (come abbiamo già descritto in precedenza) o utilizzare il file ptrace/procfs mem per scrivere il codice in un'area di memoria non scrivibile.
Ma cosa possiamo fare per evitare di eseguire queste operazioni? Abbiamo un asso nella manica: la programmazione orientata al ritorno o ROP. Utilizzando la nostra capacità di scrivere codice nello stack del processo, possiamo sovrascriverlo con una catena ROP (Figura 14). Affidandoci agli elementi eseguibili che già risiedono nella memoria di processo, possiamo costruire un payload senza scrivere alcun nuovo codice eseguibile.
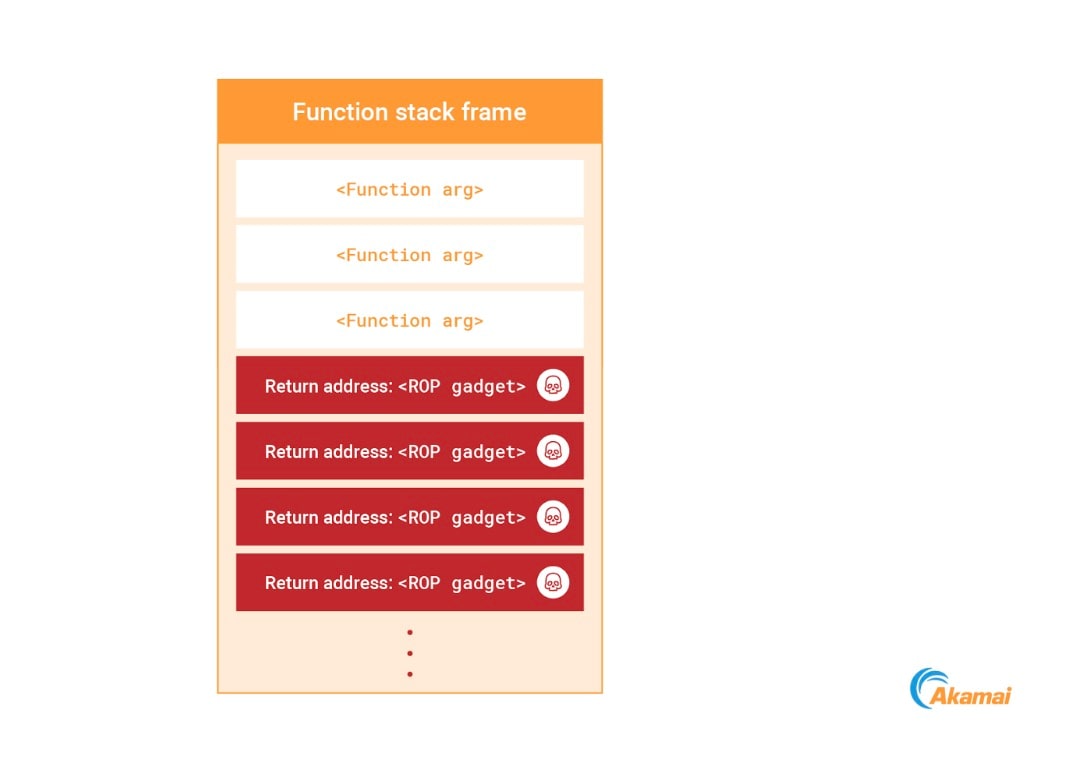 Fig. 14: Injecting a ROP chain to the process stack
Fig. 14: Injecting a ROP chain to the process stack
Questa tecnica è costituita dalle sette operazioni seguenti:
Fermare l'esecuzione del processo inviando un segnale SIGSTOP
Identificare il puntatore dello stack del processo analizzando il file syscall in procfs
Esaminare lo stack del processo e identificare un indirizzo di ritorno
Utilizzare le primitive di scrittura citate in precedenza per iniettare il nostro payload in un'area di memoria scrivibile senza autorizzazioni di esecuzione
Costruire una catena ROP per richiamare il file mprotect e contrassegnare l'area di memoria del nostro shellcode eseguibile
Sovrascrivere lo stack con la catena ROP, partendo dall'indirizzo di ritorno identificato
Riprendere l'esecuzione del processo inviando un segnale SIGCONT
Quando viene completata l'esecuzione della funzione corrente, la nostra catena ROP viene eseguita, rendendo lo shellcode eseguibile e accedendovi.
Questa teoria è stata dimostrata da Rory McNamara di AON Cyber Labs nel suo blog sull'iniezione tramite procfs mem.
Questa tecnica non richiede la modifica di aree di memoria non scrivibili e, pertanto, può essere eseguita utilizzando tutte le tecniche di interazione dei processi, incluso il file process_vm_writev.
Date un'occhiata alla nostra implementazione di questa tecnica tramite il file process_vm_writev. In base alle nostre conoscenza, questa è la prima dimostrazione pubblica di una tecnica di iniezione basata solo sul file process_vm_writev syscall.
Dirottamento della GOT
Applicabile a: ptrace, file procfs mem, process_vm_writev
Un'altra sezione interessante della memoria, che è solitamente scrivibile, è la GOT. La GOT (Global Offset Table) è una sezione della memoria utilizzata come parte del processo di rilocazione dei file ELF con collegamento dinamico. Non analizzare l'argomento nei dettagli in questa sede, ma ci focalizzeremo piuttosto sulla parte che è pertinente per i nostri scopi: la sezione in cui vengono archiviati gli indirizzi delle funzioni importate dal programma. Quando il programma richiama una funzione da una libreria remota, risolve il relativo indirizzo della memoria accedendo alla GOT (Figura 15).
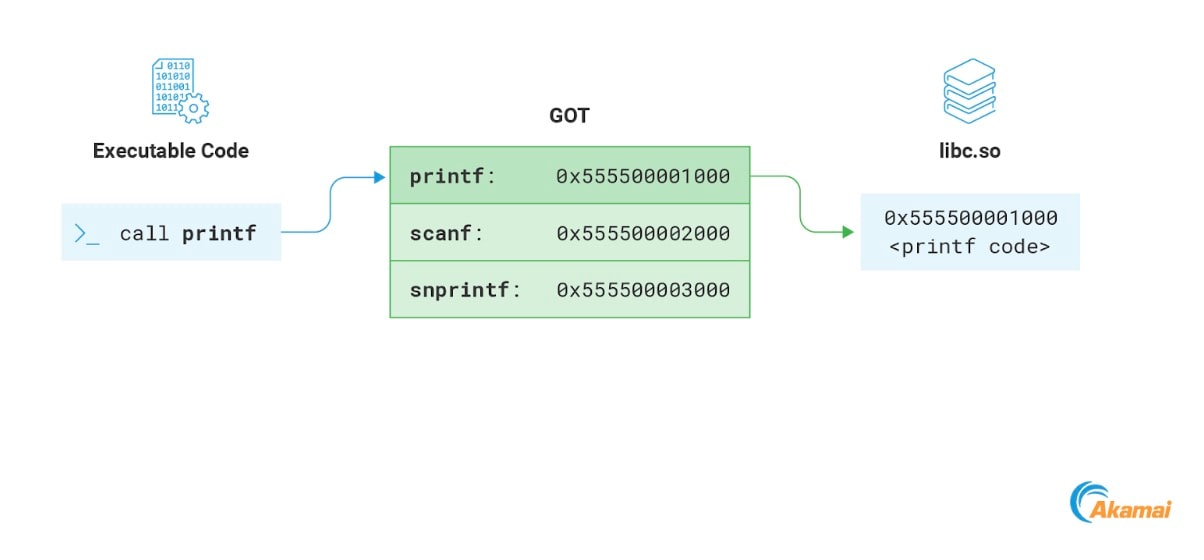 Fig. 15: Resolving a library function address using the GOT
Fig. 15: Resolving a library function address using the GOT
Questo meccanismo può essere abusato da un criminale per dirottare il flusso di esecuzione del processo. La memoria GOT è, solitamente, scrivibile, quindi un criminale può sovrascrivere qualsiasi indirizzo presente al suo interno con l'indirizzo del proprio payload. La volta successiva in cui la funzione è richiamata dal processo, viene eseguito invece il codice del criminale (Figura 16).
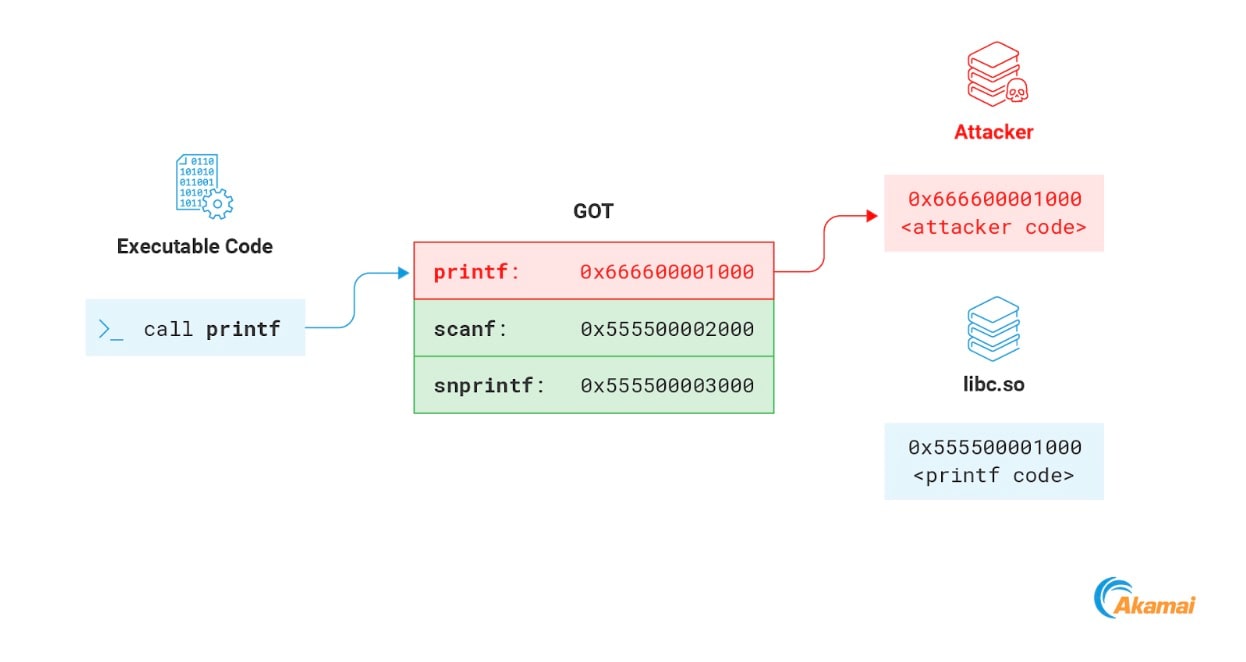 Fig. 16: Modifying a function in the GOT to point to the attacker payload
Fig. 16: Modifying a function in the GOT to point to the attacker payload
Questa tecnica è costituita dalle quattro operazioni seguenti:
Fermare l'esecuzione del processo inviando un segnale SIGSTOP
Identificare l'area della memoria GOT analizzando il file maps
Sovrascrivere gli indirizzi riportati nella sezione con l'indirizzo del nostro payload
Riprendere l'esecuzione del processo inviando un segnale SIGCONT
Quando è richiamata una delle funzioni sovrascritte, viene eseguito il nostro payload.
Una protezione delle memoria che può influire su questo attacco è il sistema RELRO completo; la compilazione di un file binario con questa impostazione consente alla memoria GOT di disporre di autorizzazioni di sola lettura e, potenzialmente, di impedire la sovrascrittura.
Nonostante ciò, il sistema RELRO non è in grado di prevenire questo attacco nella maggior parte dei casi.
I file ptrace e procfs mem bypassano le autorizzazioni della memoria, rendendo irrilevante il sistema RELRO
Il sistema RELRO influisce sul file binario del processo, ma non sulle sue librerie caricate. Se il processo carica una libreria compilata senza il sistema RELRO, la sua GOT sarà scrivibile, quindi potrà essere sovrascritta.
L'implementazione di questa tecnica tramite il file process_vm_writev syscall si trova nel nostro archivio.
Riepilogo delle primitive di esecuzione
Nella tabella, viene riportato un riepilogo di tutte le possibili primitive di esecuzione che abbiamo descritto e i metodi con cui possono essere implementate.
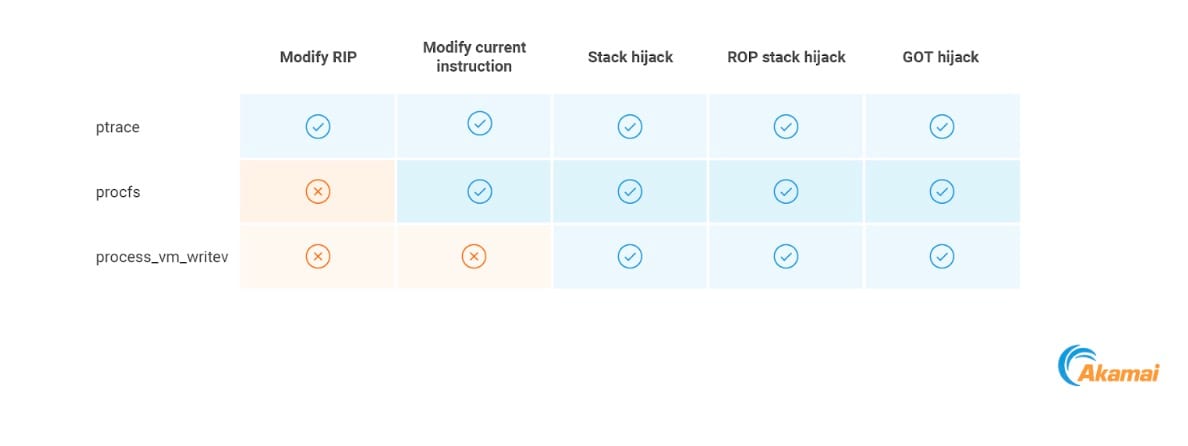 All the possible execution primitives and the methods that could be used to implement them
All the possible execution primitives and the methods that could be used to implement them
Limitazioni all'interazione con i processi remoti
Esistono varie impostazioni che determinano la nostra capacità di interagire con i processi remoti tramite i metodi appena descritti. In questa sezione, viene fornita una breve analisi dei due metodi principali.
ptrace_scope
ptrace_scope è un'impostazione che stabilisce chi può usare il file ptrace sui processi remoti e può avere i seguenti valori:
0 - Processi che si possono collegare ad altri processi nel sistema, purché abbiano lo stesso UID.
1 - Normali processi che si possono collegare solo ai loro processi secondari. I processi con privilegi (con CAP_SYS_PTRACE) si possono comunque collegare a processi non correlati. Questa è l'impostazione predefinita in molte distribuzioni.
2 - Solo i processi con CAP_SYS_PTRACE si possono collegare ai processi. Questa funzionalità viene solo concessa ai processi radice.
3 - Il collegamento ai processi remoti è disabilitato.
Nonostante il suo nome, questa impostazione influisce anche sulla capacità di accedere al file procfs mem dei processi remoti e di utilizzare il file process_vm_writev.
L'attributo "dumpable"
Ogni processo in Linux viene configurato con l'attributo "dumpable" impostato su True per defautl. Un processo diventa automaticamente "non dumpable" in alcuni casi o configurato come tale manualmente richiamando il file prctl.
Se un processo non è dumpable, non sarà possibile accedervi da remoto con uno dei metodi citati in precedenza. Questa impostazione sovrascrive le altre: un processo non dumpable non può essere modificato da remoto.
Nota sul recupero dei processi
Tutti i metodi di iniezione che abbiamo illustrato richiedono la modifica dello stato del processo in qualche modo: tramite la modifica dei registri del processo o la sovrascrittura della memoria eseguibile, un indirizzo di ritorno sullo stack o la GOT. Tutte queste operazioni modificano il normale flusso di esecuzione del processo e causano un comportamento imprevisto una volta completato il nostro payload.
Questa situazione può diventare problematica se si desidera continuare ad eseguire il processo in questione insieme al payload su cui è stata eseguita l'iniezione. Per assicurarsi di continuare ad eseguire normalmente il processo, dobbiamo ripristinarlo al suo stato originale. Il flusso di ripristino generale è costituito dalle otto operazioni seguenti:
Backup del contenuto della memoria che si desidera sovrascrivere utilizzando una primitiva di lettura remota
Backup del contenuto corrente dei registri del processo; da eseguire tramite il file ptrace o lo shellcode
Eseguire il payload (ad es., caricare il file di un oggetto condiviso o SO che esegue il codice in un thread separato)
Una volta completato il payload, istruire il processo di iniezione in modo da terminare l'esecuzione; da implementare con un interrupt
Mettere in pausa il processo remoto
Ripristinare lo stato del registro del processo
Ripristinare la memoria sovrascritta
Riprendere l'esecuzione del processo
I dettagli dell'implementazione variano leggermente a seconda del metodo di iniezione utilizzato, ma, in genere, viene seguita questa procedura. Il blog di Adam Chester sull'iniezione del file ptrace in Linux fornisce un esempio dettagliato del ripristino del processo dopo un'iniezione basata sul file ptrace.
L'obiettivo di questo post è fornire una panoramica sulle tecniche di iniezione per consentire agli addetti alla sicurezza di familiarizzare con questi metodi per poi costruire sistemi di rilevamento appropriati. Poiché ci siamo focalizzati sui sistemi di difesa, abbiamo scelto di non descrivere in dettaglio le operazioni di ripristino per le varie tecniche, di cui i criminali hanno bisogno per utilizzarle per scopi illeciti.
Rilevamento e mitigazione
Come abbiamo appena descritto, sono molte le tecniche che consentono ai criminali di eseguire un'iniezione del processo sui computer Linux. Fortunatamente per noi, tutti questi metodi richiedono l'esecuzione di azioni anomale per fornire opportunità di rilevamento. Nelle sezioni successive, verranno descritte in dettaglio le diverse strategie da poter implementare per rilevare e mitigare l'iniezione del processo su Linux.
Le chiamate di sistema per l'iniezione
In questo post, abbiamo usato tre metodi per interagire con i processi remoti: ptrace, procfs e process_vm_writev. A causa del loro potenziale per un uso dannoso, questi metodi vanno monitorati.
Iniziamo con l'installazione di una soluzione di registrazione sui computer Linux. È possibile abilitare il monitoraggio dell'esecuzione di chiamate di sistema tramite una soluzione di monitoraggio basata sull'eBPF, come Sysmon per Linux o Tracee di Aqua Security (che implementa già regole contenenti molte tecniche descritte in questo post).
Dopo aver stabilito la registrazione, si consiglia alle organizzazioni di analizzare il normale uso delle chiamate di sistema per l'iniezione nel loro ambiente e di fissare un valore di riferimento per i casi noti di utilizzo valido. Dopo aver creato un valore di riferimento, eventuali scostamenti devono essere esaminati per riconoscere un potenziale attacco. Ulteriori considerazioni sulle chiamate di sistema sono descritte nelle sezioni successive.
Utilizzare, idealmente il file ptrace_scope, ove possibile, per limitare o evitare completamente l'utilizzo delle chiamate di sistema di questo tipo.
ptrace
Nella maggior parte degli ambienti di produzione, l'utilizzo del file ptrace syscall è alquanto raro. Dopo aver stabilito un valore di riferimento per un utilizzo valido del file ptrace, si consiglia di analizzare un suo eventuale utilizzo anomalo.
Le seguenti richieste ptrace consentono di modificare i processi remoti e devono essere considerati altamente sospetti:
POKEDATA/POKETEXT
POKEUSER
SETREGS
procfs
La scrittura del file procfs mem può essere usata, talvolta, per scopi legittimi, tuttavia questo comportamento non è molto comune. Dopo aver creato un valore di riferimento per un utilizzo valido, si consiglia di analizzare eventuali operazioni di scrittura anomale.
È importante anche considerare la directory /proc/<pid>/task procfs, in cui si trovano le informazioni sui vari thread del processo. Ogni thread presenta una sua directory procfs, che contiene tutti i principali file procfs di cui abbiamo parlato, inclusi i file mem, maps e syscall.
In Figura 17, possiamo vedere che la lettura del file syscall nella directory /proc/<pid> equivale a quella della directory /proc/<pid>/task/<pid>, che rappresenta il thread principale del processo.
 Fig. 17: Example of using the /proc/<pid>/task directory
Fig. 17: Example of using the /proc/<pid>/task directory
process_vm_writev
Anche in questo caso, dopo aver creato un valore di riferimento per l'utilizzo legittimo di questa chiamata di sistema, possiamo identificare eventuali scostamenti anomali. Un processo sconosciuto che scrive nella memoria di altri processi va considerato sospetto e analizzato.
Rilevamento di anomalie del processo
Oltre a rilevare direttamente l'iniezione dei processi, possiamo anche tentare di rilevarne gli effetti collaterali. Quando un codice viene iniettato in un processo remoto, cambia il modo con cui si comporta. Oltre alle normali azioni eseguite dal processo, vengono effettuate anche le azioni del payload.
Questa modifica del comportamento può fornire un'opportunità di rilevamento. Creando un valore di riferimento per il comportamento normale del processo, possiamo identificare eventuali scostamenti sospetti che indicano se si è verificata un'iniezione del codice. Alcuni esempi di tali comportamenti possono includere la creazione di processi secondari anomali, il caricamento di file SO non visti in precedenza o la comunicazione tramite porte anomale.
I ricercatori di Akamai hanno documentato questo approccio e hanno dimostrato come identificare l'iniezione di codice analizzando le anomalie della rete.
Riepilogo
I criminali hanno moltissime opzioni a disposizione per sferrare gli attacchi di iniezione sui computer Linux. Anche se queste tecniche possono essere molto utili per i criminali, forniscono anche preziose opportunità di rilevamento per gli addetti alla sicurezza. Implementando solide funzionalità di registrazione e rilevamento sui computer Linux, le organizzazioni possono migliorare notevolmente i propri sistemi di sicurezza.
