
Guide définitif de l'injection de processus Linux


Introduction
Les techniques d'injection de processus constituent un élément important de l'ensemble d'outils d'un attaquant. Elles peuvent permettre aux acteurs de la menace d'exécuter un code malveillant à l'intérieur d'un processus légitime pour éviter d'être détectés, ou de placer des hooks dans des processus distants pour modifier leur comportement.
L'injection de processus sur les machines Windows a fait l'objet de recherches approfondies et est relativement bien connue. Ce n'est pas exactement le cas pour les machines Linux. Bien que d'excellentes ressources aient été rédigées sur le sujet, la sensibilisation aux différentes techniques d'injection sous Linux semble être relativement limitée, surtout si on la compare à celle de Windows.
Nous nous sommes inspirés d'une présentation de l'injection de processus Windows écrite par Amit Klein et Itzik Kotler de SafeBreach, et avons pour objectif de fournir une documentation complète sur l'injection de processus sous Linux. Nous nous concentrerons sur la « véritable injection de processus », c'est-à-dire sur les techniques qui ciblent les processus en cours d'exécution. Cela signifie que nous excluons les méthodes qui nécessitent la modification du binaire sur le disque, l'exécution du processus avec des variables d'environnement spécifiques ou l'utilisation abusive du processus de chargement de processus.
Nous décrirons les caractéristiques du système d'exploitation qui facilitent l'injection de processus dans Linux, et les différentes primitives d'injection qu'elles permettent. Nous couvrirons les techniques qui ont été décrites précédemment, et nous mettrons également en évidence les variantes d'injection qui n'ont pas été documentées jusqu'à présent. Nous conclurons en abordant les stratégies de détection et d'atténuation des techniques mises en évidence.
En plus de cet article de blog, nous publions un référentiel GitHub contenant un ensemble complet de codes de démonstration de faisabilité (PoC) pour les différentes primitives d'injection décrites dans l'article. Ces PoC bénins ont pour but d'aider à comprendre à quoi pourrait ressembler une implémentation malveillante des techniques, ce qui peut vous aider à construire et tester des capacités de détection. Pour plus d'informations, veuillez vous reporter au fichier README du projet.
Comparaison entre l'injection sous Linux et l'injection sous Windows
Le nombre de techniques d'injection connues sur les machines Windows est énorme et ne cesse de croître, des files d'attente APC et des transactions NTFS aux tables atomiques et aux pools de threads. Windows expose de nombreuses interfaces qui permettent aux attaquants d'interagir avec (et de faire des injections dans) des processus distants.
La situation est très différente dans le domaine de Linux. L'interaction avec les processus distants est limitée à un petit ensemble d'appels système, et de nombreuses fonctionnalités qui facilitent l'injection sur les machines Windows sont introuvables. Il n'existe pas d'API d'allocation de mémoire dans un processus distant ou de modification de la protection de la mémoire distante et certainement pas de création de threads distants.
Cette différence a une incidence sur la structure de l'attaque par injection. Sous Windows, l'injection de processus se compose généralement de trois étapes : allouer → écrire → exécuter. Tout d'abord, nous allouons de la mémoire au processus distant qui sera utilisée pour stocker notre code, puis nous écrivons notre code dans cette mémoire et, enfin, nous l'exécutons.
Avec Linux, nous n'avons pas la possibilité d'effectuer la première étape, l'allocation. Il n'existe aucun moyen direct d'allouer de la mémoire dans un processus distant. Pour cette raison, le flux d'injection sera légèrement différent : écrasement → exécution → récupération. Nous écrasons la mémoire existante dans le processus distant avec notre charge utile, nous l'exécutons, puis nous récupérons l'état précédent du processus pour lui permettre de continuer à s'exécuter normalement.
Méthodes d'interaction avec les processus distants
Sous Linux, l'interaction avec la mémoire des processus distants se limite à trois méthodes principales : ptrace, procfset process_vm_writev. Les sections suivantes fournissent une brève description de chacun d'entre eux.
ptrace
ptrace est un appel système utilisé pour déboguer les processus distants. Le processus initiateur est en mesure d'inspecter et de modifier la mémoire et les registres du processus débogué. Les débogueurs tels que GDB sont implémentés en utilisant ptrace pour contrôler le processus débogué.
ptrace prend en charge différentes opérations, qui sont spécifiées par un code de requête ptrace . Quelques exemples notables incluent PTRACE_ATTACH (qui s'attache à un processus), PTRACE_PEEKTEXT (qui lit la mémoire du processus) et PTRACE_GETREGS (qui récupère les registres du processus). L'extrait 1 montre un exemple d'utilisation de ptrace.
// Attach to the remote process
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// Get registers state
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
Extrait 1 : Exemple utilisation de ptrace pour récupérer les registres d'un processus distant
procfs
procfs est un pseudo-système de fichiers spécial qui sert d'interface aux processus en cours d'exécution sur le système. Il est accessible via le répertoire /proc (Figure 1).
 Fig. 1: A directory listing of the /proc directory on a Linux machine
Fig. 1: A directory listing of the /proc directory on a Linux machine
Chaque processus est représenté par un répertoire, nommé en fonction de son PID. Sous ce répertoire se trouvent des fichiers qui fournissent des informations sur le processus. Par exemple, le cmdline contient la ligne de commande du processus, le fichier environ contient les variables d'environnement de processus, etc.
procfs nous permet également d'interagir avec la mémoire des processus distants. Dans chaque répertoire de processus, nous trouverons le fichier mem , un fichier spécial qui représente l'ensemble de l'espace d'adressage du processus. L'accès au fichier mem d'un processus à un décalage donné équivaut à l'accès à la mémoire du processus à la même adresse.
Dans l'exemple de la Figure 2, nous avons utilisé l'utilitaire xxd pour lire 100 octets du fichier mem de processus, en commençant à un décalage spécifié.
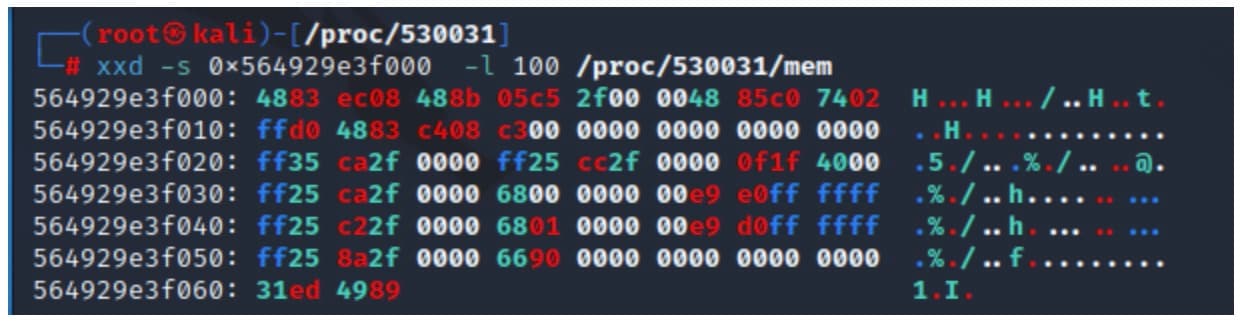 Fig. 2: Using xxd to read the procfs mem file
Fig. 2: Using xxd to read the procfs mem file
Si nous inspectons la même adresse en mémoire à l'aide de GDB, nous constaterons que le contenu est identique (Figure 3).
 Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
Le fichier maps est un autre fichier intéressant que l'on peut trouver dans le répertoire du processus (Figure 4). Ce fichier contient des informations sur les différentes régions de la mémoire dans l'espace d'adressage du processus, y compris leurs plages d'adresses et leurs autorisations de mémoire.
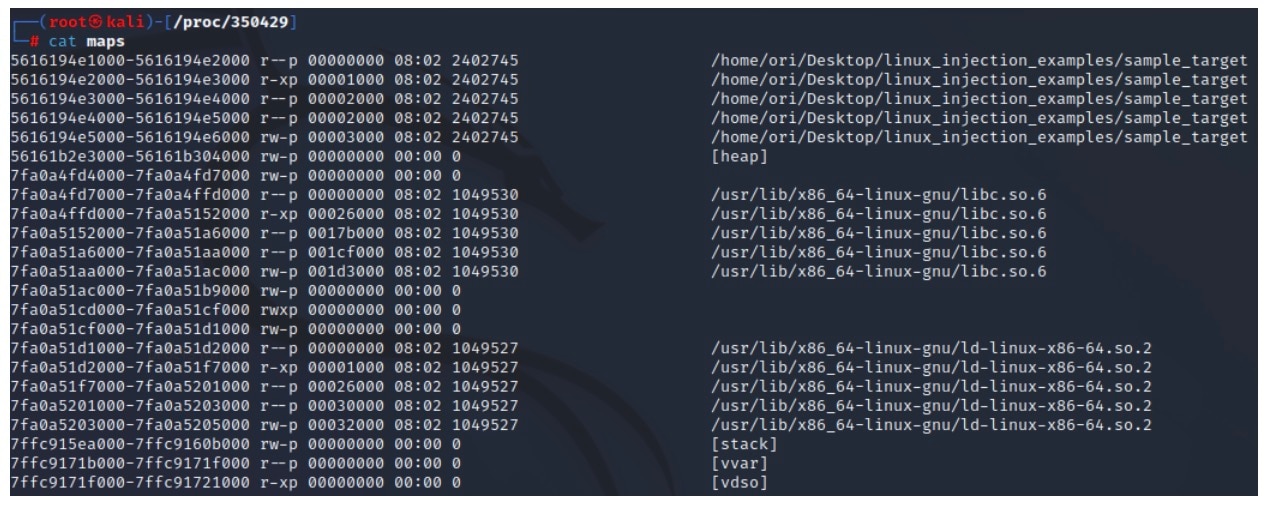 Fig. 4: Example contents of a process maps file
Fig. 4: Example contents of a process maps file
Dans les sections suivantes, nous verrons comment la possibilité d'identifier des régions de mémoire avec des autorisations spécifiques peut s'avérer très utile.
process_vm_writev
La troisième méthode d'interaction avec la mémoire d'un processus distant est l'appel système process_vm_writev. Ce syscall permet d'écrire des données dans l'espace d'adressage d'un processus distant.
process_vm_writev reçoit un pointeur sur un tampon local et copie son contenu à une adresse spécifiée dans le processus distant. Un exemple d'utilisation de process_vm_writev est présenté dans l'extrait 2.
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our data in the local iovec
local[0].iov_base = data;
local[0].iov_len = data_len;
// Point the remote iovec to the address in the remote process
remote[0].iov_base = (void *)remote_address;
remote[0].iov_len = data_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
Extrait 2 : Utilisation de process_vm_writev pour écrire des données sur un processus distant
Écriture de code sur un processus distant
Maintenant que nous comprenons les différentes méthodes pour interagir avec d'autres processus, voyons comment les utiliser pour réaliser une injection de code. La première étape de l'attaque par injection consiste à écrire notre shellcode dans la mémoire du processus distant. Comme nous l'avons mentionné, sous Linux, il n'existe aucun moyen direct d'allouer de la nouvelle mémoire dans un processus distant. Cela signifie que nous ne pouvons pas créer une nouvelle section de mémoire ; nous devrons utiliser la mémoire existante du processus cible.
Pour pouvoir exécuter notre code, nous devons l'écrire dans une région de la mémoire avec les autorisations d'exécution. Pour trouver une telle région, il suffit d'analyser le fichier maps procfs mentionné précédemment et d'identifier une région de mémoire avec des autorisations d'exécution (x) (Figure 5).
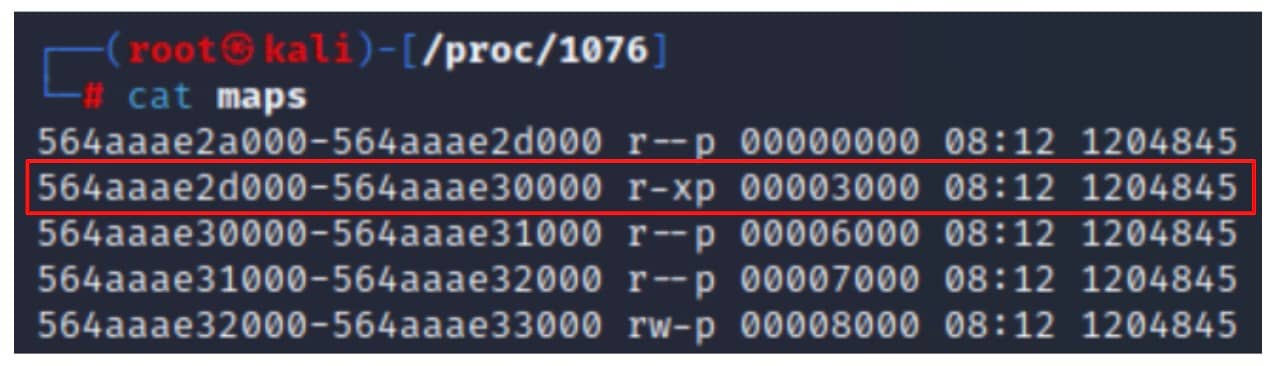 Fig. 5: Identifying an executable memory region in the process maps file
Fig. 5: Identifying an executable memory region in the process maps file
Nous pouvons rencontrer deux types de régions exécutables : les régions accessibles en écriture et les régions non accessibles en écriture. Les sections suivantes indiquent quand et comment chacune d'entre elles peut être utilisée.
Écriture de code dans la mémoire RX
Applicable à : ptrace, procfs mem
Idéalement, nous souhaitons identifier une région de mémoire avec des autorisations d'accès en écriture et d'exécution, ce qui nous permettrait d'écrire notre code et de l'exécuter. En réalité, la plupart des processus n'ont pas de région avec de telles autorisations, car l'allocation de mémoire WX est considérée comme une mauvaise pratique. Au lieu de cela, nous sommes généralement limités à des autorisations d'accès en lecture et d'exécution.
Chose intéressante, il est possible de contourner cette limitation en utilisant deux des méthodes que nous venons de décrire : ptrace et procfs mem. Ces deux mécanismes sont implémentés d'une manière qui leur permet de contourner les autorisations de mémoire et d'écrire à n'importe quelle adresse, même sans autorisations d'accès en écriture. Vous trouverez des détails supplémentaires sur ce comportement de procfs dans cet article de blog.
Cela signifie que, quelles que soient les autorisations d'accès en écriture, nous pouvons toujours utiliser ptrace ou procfs mem pour écrire notre code dans une région de mémoire exécutable distante.
ptrace
Pour écrire notre charge utile dans un processus distant, nous pouvons utiliser les requêtes ptrace POKETEXT ou POKEDATA. Ces requêtes identiques permettent d'écrire un mot de données dans la mémoire du processus distant. En les appelant à plusieurs reprises, nous pouvons copier l'intégralité de notre charge utile dans la mémoire du processus cible. L'Extrait 3 en donne un exemple.
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// write payload to remote address
for (size_t i = 0; i < payload_size; i += 8, payload++)
{
ptrace(PTRACE_POKETEXT, pid, address + i, *payload);
}
Extrait 3 : Utilisation de ptrace POKETEXT pour écrire notre charge utile dans la mémoire du processus distant
procfs mem
Pour écrire notre charge utile dans un processus distant à l'aide de procfs, nous devons simplement l'écrire dans le fichier mem avec le bon décalage. Toute modification apportée au fichier mem est appliquée à la mémoire du processus. Pour effectuer ces opérations, nous pouvons utiliser les API de fichier normales (Extrait 4).
// Open the process mem file
FILE *file = fopen("/proc/<pid>/mem", "w");
// Set the file index to our required offset, representing the memory address
fseek(file, address, SEEK_SET);
// Write our payload to the mem file
fwrite(payload, sizeof(char), payload_size, file);
Extrait 4 : Utilisation du fichier procfs mem pour écrire des données dans la mémoire d'un processus distant
Écriture de code dans la mémoire WX
Applicable à : ptrace, procfs mem, process_vm_writev
Comme nous l'avons vu, ptrace et procfs mem contournent les autorisations de mémoire et nous permettent d'écrire notre code dans des régions de mémoire non accessibles en écriture. Ce n'est pas le cas de process_vm_writev, qui respecte les autorisations de mémoire et nous permet donc d'écrire des données uniquement dans des régions de mémoire accessibles en écriture.
Pour cette raison, notre seule option est de rechercher des régions accessibles en écriture. Tous les processus ne contiennent pas de telles régions, mais nous pouvons certainement en trouver.
La commande de l'Extrait 5 analysera le fichier maps de tous les processus du système et identifiera les régions avec des autorisations d'accès en écriture et d'exécution (Figure 6).
find /proc -type f -wholename "*/maps" -exec grep -l "wx" {} +
Extrait 5 : Utilisation de la commande « find » pour identifier les processus possédant des régions de mémoire d'écriture et d'exécution
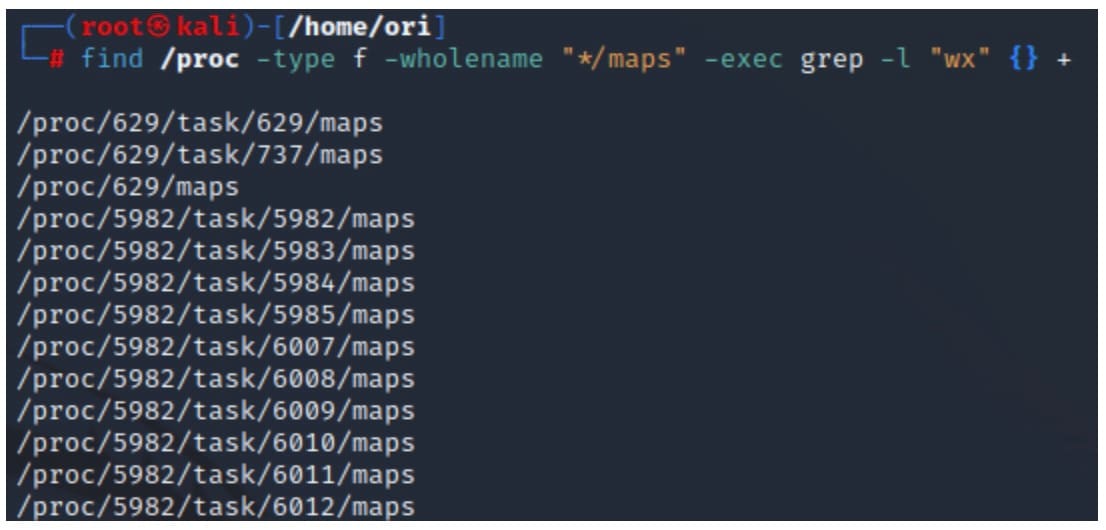 Fig. 6: Example output of finding processes with WX memory regions
Fig. 6: Example output of finding processes with WX memory regions
Après avoir identifié une telle région, nous pouvons utiliser process_vm_writev pour y écrire notre code (Extrait 6).
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our payload in the local iovec
local[0].iov_base = payload;
local[0].iov_len = payload_len;
// Point the remote iovec to the address of our wx memory region
remote[0].iov_base = (void *)wx_address;
remote[0].iov_len = payload_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
Extrait 6 : Utilisation de process_vm_writev pour écrire une charge utile dans une région WX distante
Détournement du flux d'exécution à distance
Après avoir écrit notre code dans la mémoire du processus distant, nous devrons l'exécuter. Dans les sections suivantes, nous décrirons les différentes techniques que nous pouvons utiliser pour y parvenir.
Nos recherches se sont concentrées sur les machines amd64. Certaines petites différences peuvent être observées sur d'autres architectures, mais les concepts généraux devraient rester les mêmes.
Modification du pointeur d'instruction de processus
Applicable à : ptrace
Lorsque nous nous attachons à un processus à l'aide de ptrace, son exécution est interrompue et nous sommes en mesure d'inspecter et de modifier les registres du processus, y compris le pointeur d'instruction. Ces opérations sont possibles grâce aux requêtes ptrace SETREGS et GETREGS. Pour modifier le flux d'exécution du processus, nous pouvons utiliser ptrace pour faire en sorte que le pointeur d'instruction renvoie vers l'adresse de notre shellcode.
Dans l'exemple de l'Extrait 7, nous avons effectué les trois étapes suivantes :
Récupération des valeurs actuelles des registres à l'aide de la requête ptrace GETREGS
Modification du pointeur d'instruction pour qu'il renvoie vers l'adresse de notre charge utile (incrémentée de 2, ce dont nous parlerons plus tard)
Application de la modification au processus à l'aide de la requête SETREGS
// Get old register state.
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
// Modify the instruction pointer to point to our payload
regs.rip = payload_address + 2;
// Modify the registers
ptrace(PTRACE_SETREGS, pid, NULL, ®s);
Extrait 7 : Utilisation de ptrace SETREGS pour rediriger le pointeur d'instruction vers notre charge utile
SETREGS est la méthode « traditionnelle » et la plus documentée pour modifier les registres du processus, mais une autre requête ptrace peut également être utilisée pour accomplir cette tâche : POKEUSER.
La requête POKEUSER permet d'écrire des données dans la zone du processus USER — une structure (définie dans sys/user.h) qui contient des informations sur le processus, y compris les registres. En appelant POKEUSER avec le décalage correct, nous pouvons écraser le pointeur d'instruction avec l'adresse de notre code et obtenir le même résultat que précédemment (Extrait 8).
// calculate the offset of the RIP register, based on the USER struct definition
rip_offset = 16 * sizeof(unsigned long);
ptrace(PTRACE_POKEUSER, pid, rip_offset, payload_address + 2);
Extrait 8 : Utilisation de ptrace POKEUSER pour rediriger le pointeur d'instruction vers notre charge utile
Notre implémentation de l'utilisation de POKEUSER pour modifier RIP est disponible dans notre référentiel.
RIP += 2 : Quand et pourquoi ?
Comme le montrent les Extraits 7 et 8, lorsque nous modifions RIP à l'adresse de notre charge utile, nous l'incrémentons également de 2. Cette opération a pour but de prendre en compte un comportement intéressant de ptrace — parfois, après la déconnexion d'un processus avec ptrace, la valeur de RIP sera décrémentée de 2. Examinons pourquoi cela se produit.
Lorsque nous nous attachons à un processus à l'aide de ptrace, nous pouvons interrompre un syscall en cours d'exécution dans le noyau. Pour assurer l'exécution correcte du syscall, le noyau le réexécute lorsque nous nous déconnectons du processus.
Pendant l'exécution du syscall, RIP pointe déjà vers la prochaine instruction à exécuter. Pour réexécuter le syscall, le noyau décrémente la valeur de RIP de 2, la taille de l'instruction syscall dans amd64. Après cette modification, RIP pointe à nouveau vers l'instruction syscall, ce qui permet de l'exécuter une nouvelle fois (Figure 7).
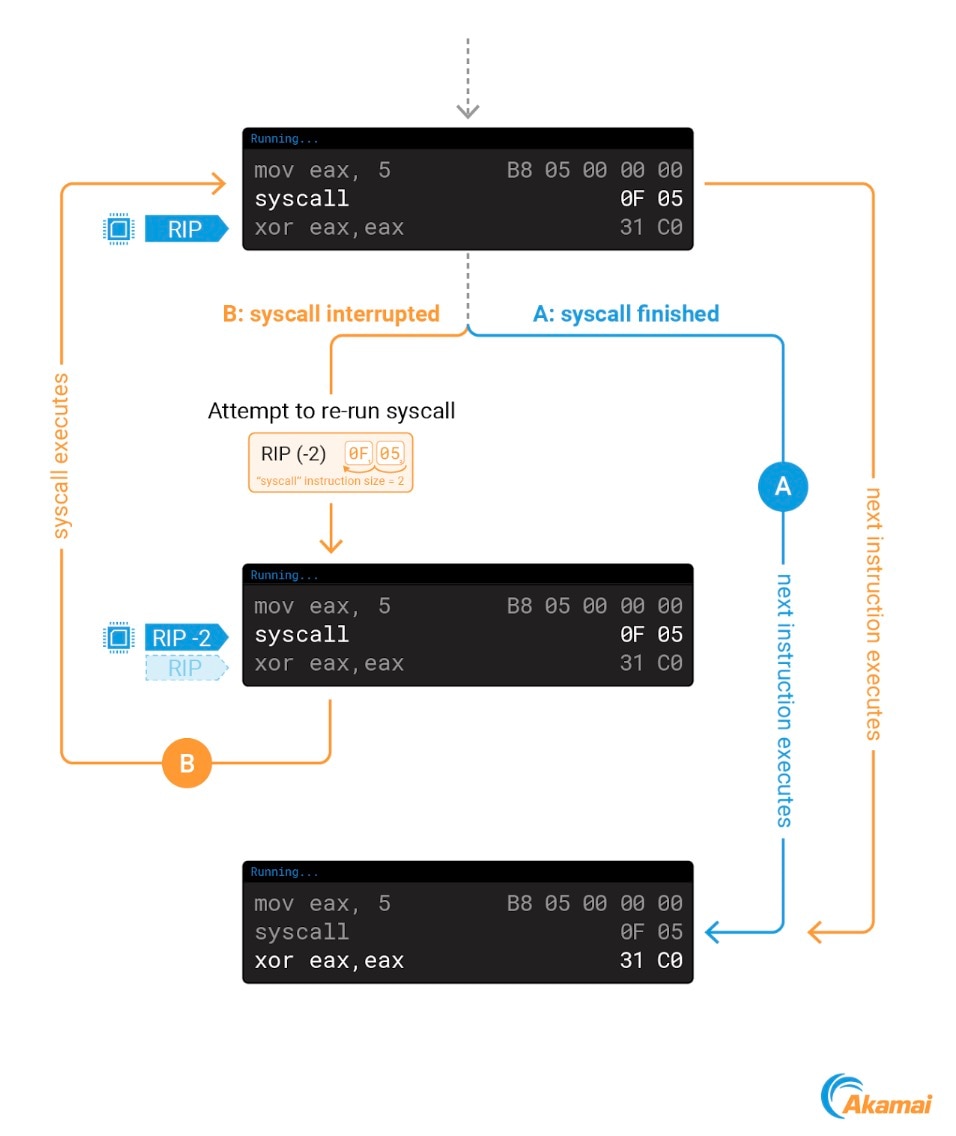 Fig. 7: The effect of using ptrace on a process during syscall execution
Fig. 7: The effect of using ptrace on a process during syscall execution
L'interruption d'un processus au cours d'un syscall lors d'une injection de code peut entraîner des problèmes. Après avoir modifié RIP pour qu'il pointe vers notre code, le noyau décrémentera toujours la nouvelle valeur de 2, ce qui entraînera un écart de 2 octets avant notre shellcode, ce qui le fera probablement échouer (Figure 8).
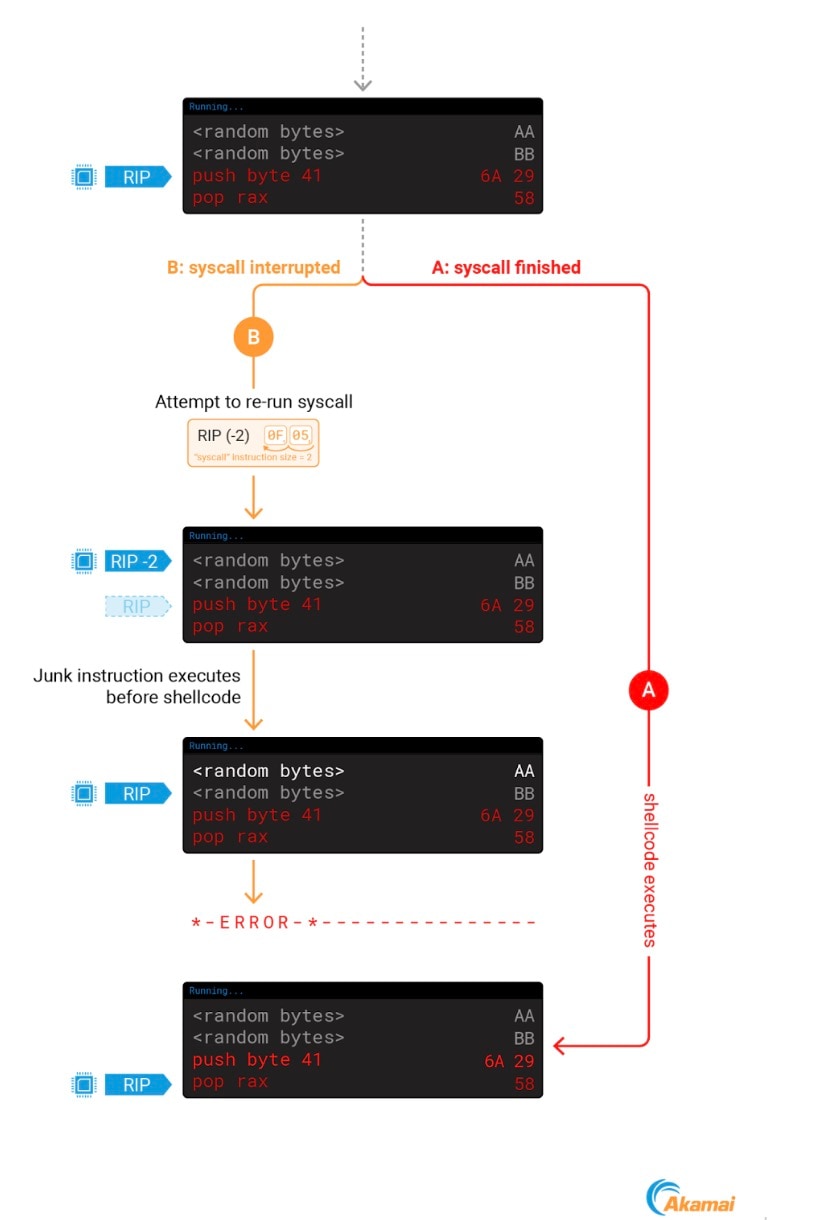 Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Pour tenir compte de ce comportement, nous allons prendre deux mesures : préfixer notre shellcode avec deux instructions NOP (no operation), et faire pointer RIP vers l'adresse de notre shellcode + 2. Ces deux étapes permettront de s'assurer que notre code s'exécute correctement.
Si nous avons interrompu le processus pendant un syscall, le noyau décrémente la nouvelle valeur de RIP, qui pointe vers l'adresse de départ du shellcode qui contient deux NOP que nous glissons dans notre code réel.
Si nous n'avons pas interrompu le processus pendant un syscall, le nouveau RIP ne sera pas décrémenté, ce qui aura pour conséquence de sauter les deux NOP et d'exécuter notre code. Ces deux scénarios sont illustrés dans la Figure 9.
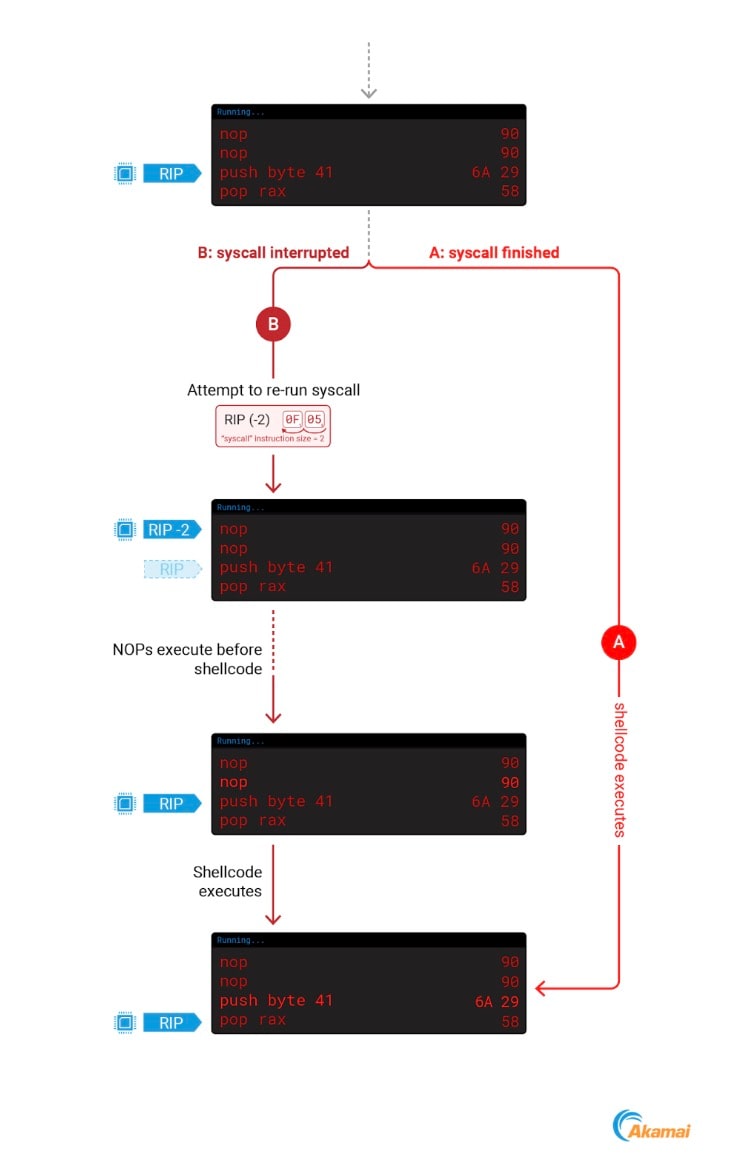 Fig. 9: Overcoming the ptrace RIP interaction
Fig. 9: Overcoming the ptrace RIP interaction
Modification de l'instruction en cours
Applicable à : ptrace, procfs mem
Le fichier syscall est un autre fichier intéressant de procfs. Il contient des informations sur le syscall actuellement exécuté par le processus : le numéro du syscall, les arguments qui lui ont été transmis, le pointeur de pile et (ce qui est le plus intéressant pour notre problématique) le pointeur d'instruction du processus (Figure 10). Même si le processus n'est pas en train d'exécuter un syscall, les pointeurs de pile et d'instruction du processus seront toujours présents dans le fichier syscall.
 Fig. 10: The structure of the procfs syscall file
Fig. 10: The structure of the procfs syscall file
Cette information peut nous permettre de prendre le contrôle du flux d'exécution du processus ; en connaissant l'adresse de la prochaine instruction à exécuter, nous pouvons l'écraser avec nos propres instructions.
Pour ce faire, un attaquant peut suivre les quatre étapes suivantes :
Arrêter l'exécution du processus en envoyant un signal SIGSTOP
Identifier l'adresse de la prochaine instruction à exécuter en lisant le fichier syscall du processus
Écrire un shellcode à l'adresse identifiée
Reprendre l'exécution du processus en envoyant un signal SIGCONT
L'Extrait 9 fournit un pseudo-code pour ce processus.
// Suspend the process by sending a SIGSTOP signal
kill(pid, SIGSTOP);
// Open the syscall file
FILE *syscall_file = fopen("/proc/<pid>/syscall", "r");
// Extract the instruction pointer from the syscall file
long instruction_pointer = ...
// Write our payload to the address of the current instruction pointer using
procfs mem
FILE *mem_file = fopen("/proc/<pid>/mem", "w");
fseek(mem_file, instruction_pointer, SEEK_SET);
fwrite(payload, sizeof(char), payload_size, mem_file);
// Resume execution by sending a SIGCONT signal
kill(pid, SIGCONT);
Extrait 9 : Utilisation de procfs mem pour modifier la mémoire du processus à l'adresse actuelle du pointeur d'instruction afin de détourner le flux d'exécution du processus
L'exemple de l'Extrait 9 met en œuvre cette technique en utilisant le fichier procfs mem, mais il est important de noter que ptrace POKETEXT peut également être utilisé pour écrire la charge utile en mémoire.
Comme nous l'avons mentionné, process_vm_writev est limité par les autorisations de mémoire, ce qui signifie qu'il ne peut modifier que les régions de la mémoire accessibles en écriture. La probabilité de trouver du code s'exécutant à partir d'une région de mémoire WX est faible, ce qui réduit la fiabilité de process_vm_writev pour cette primitive.
Découvrez notre implémentation de cette technique à l'aide du fichier procfs mem.
Détournement de pile
Applicable à : ptrace, procfs mem, process_vm_writev
Une autre région de mémoire intéressante est la pile de processus, qui est également identifiable à l'aide du fichier maps. Bien que la mémoire de pile ne soit pas exécutable (Figure 11), nous pouvons toujours l'utiliser pour détourner le flux d'exécution du processus.
 Fig. 11: Identifying the process stack address using the maps file
Fig. 11: Identifying the process stack address using the maps file
À chaque appel d'une fonction, l'adresse de retour de la fonction appelante est poussée sur la pile. Une fois la fonction exécutée, le processeur récupère cette adresse de retour sur la pile et s'y connecte (Figure 12).
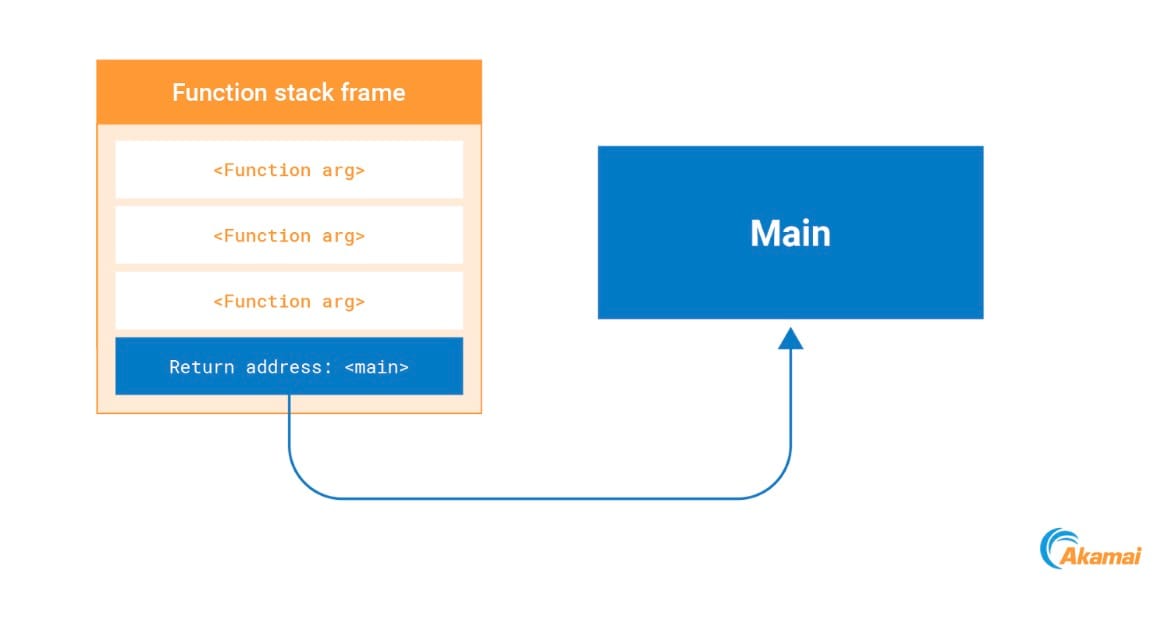 Fig. 12: Return address on the stack pointing to an address in main
Fig. 12: Return address on the stack pointing to an address in main
Pour abuser de ce mécanisme, nous pouvons identifier une adresse de retour sur la pile et l'écraser avec une nouvelle adresse qui pointe vers notre shellcode. Une fois la fonction exécutée, notre code s'exécute (Figure 13).
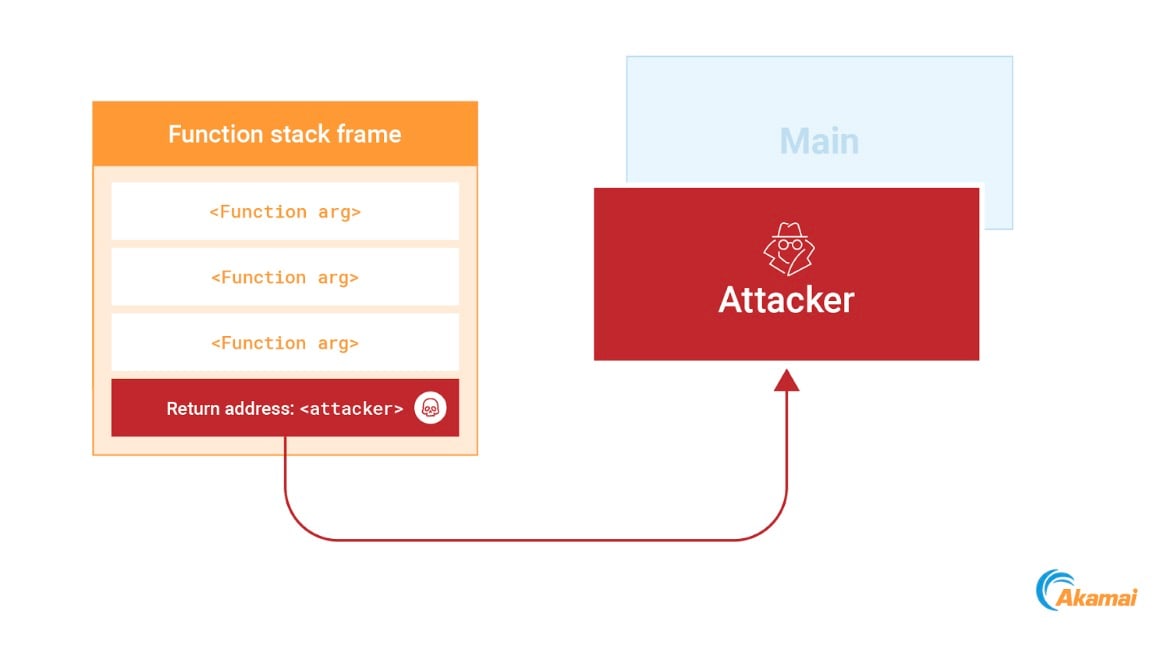 Fig. 13: Overwriting a return address on the stack to point to the attackers code
Fig. 13: Overwriting a return address on the stack to point to the attackers code
Pour identifier le sommet de la pile, nous pouvons analyser le fichier syscall procfs mentionné précédemment, qui contient également la valeur du registre du pointeur de pile.
Les six étapes suivantes permettent de mettre en œuvre cette technique :
Arrêter l'exécution du processus en envoyant un signal SIGSTOP
Identifier le pointeur de pile du processus en analysant le fichier syscall procfs
Analyser la pile du processus et identifier une adresse de retour
Utiliser l'une des primitives d'écriture mentionnées précédemment pour injecter notre charge utile dans la mémoire du processus
Écraser l'adresse de retour avec l'adresse de notre charge utile
Reprendre l'exécution du processus en envoyant un signal SIGCONT
Lorsque l'exécution de la fonction en cours se termine, notre charge utile est lancée.
Comme toutes les méthodes d'interaction avec les processus nous permettent de modifier la pile, elles peuvent toutes être utilisées pour mettre en œuvre cette technique. Notre implémentation de cette technique en utilisant le syscall process_vm_writev est disponible dans notre référentiel.
Détournement de pile ROP
Applicable à : ptrace, procfs mem, process_vm_writev
La technique de détournement de pile est intéressante dans la mesure où elle nous permet de détourner le flux d'exécution du processus sans modifier la mémoire exécutable ou les registres. Malgré tout, pour qu'elle soit utilisable, nous avons toujours besoin de faire appel au shellcode qui réside dans une région de mémoire exécutable. Nous pouvons essayer de trouver une région WX (comme nous l'avons décrit) ou utiliser ptrace/procfs mem pour écrire dans une mémoire non accessible en écriture.
Mais que faire pour éviter ces actions ? Eh bien, nous avons un autre tour dans notre sac : le return-oriented programming (ROP). En utilisant notre capacité à écrire dans la pile de processus, nous pouvons l'écraser avec une chaîne ROP (Figure 14). Comme nous nous appuyons sur des gadgets exécutables qui résident déjà dans la mémoire du processus, nous pouvons construire une charge utile sans écrire de nouveau code exécutable.
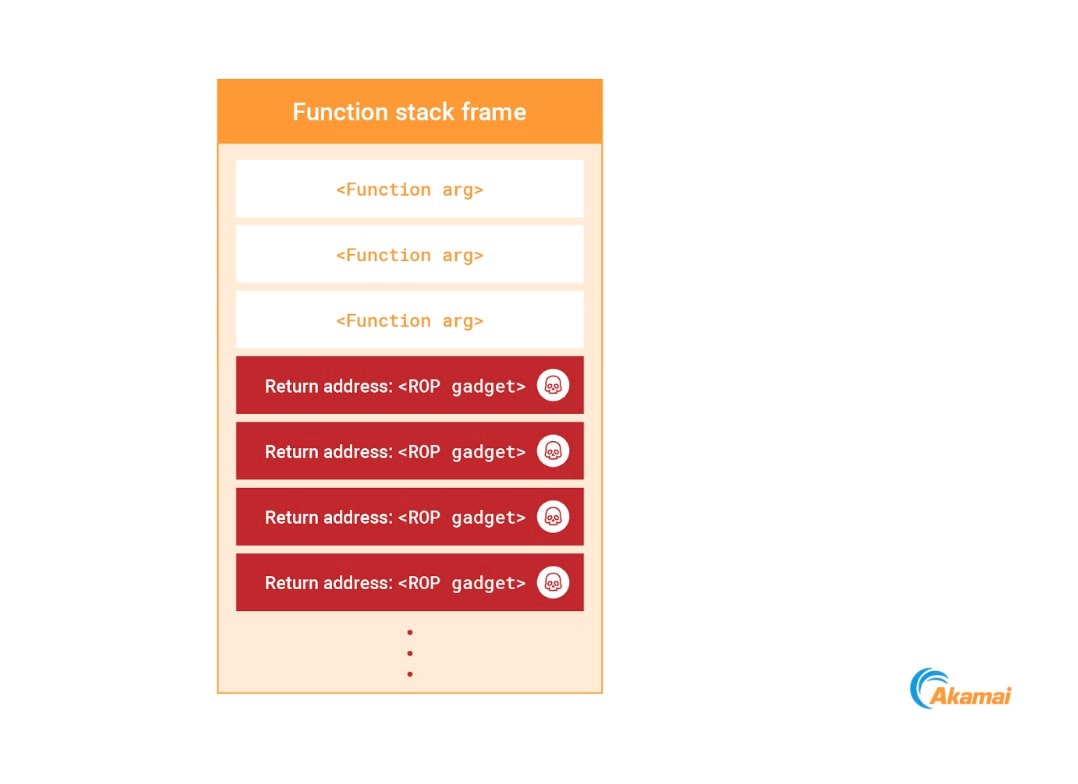 Fig. 14: Injecting a ROP chain to the process stack
Fig. 14: Injecting a ROP chain to the process stack
Cette technique comprend les sept étapes suivantes :
Arrêter l'exécution du processus en envoyant un signal SIGSTOP
Identifier le pointeur de pile du processus en analysant le fichier syscall procfs
Analyser la pile du processus et identifier une adresse de retour
Utiliser l'une des primitives d'écriture mentionnées précédemment pour injecter notre charge utile dans une région de la mémoire accessible en écriture sans autorisation d'exécution
Créer une chaîne ROP pour appeler mprotect et marquer la région mémoire de notre shellcode exécutable
Écraser la pile avec la chaîne ROP, en commençant à l'adresse de retour identifiée
Reprendre l'exécution du processus en envoyant un signal SIGCONT
Lorsque l'exécution de la fonction en cours se termine, notre chaîne ROP s'exécute, rendant le shellcode exécutable et en y accédant.
Ce concept a été démontré par Rory McNamara d'AON Cyber Labs dans son article de blog qui aborde l'injection de mémoires procfs.
Cette technique ne nécessite pas de modifier des régions de mémoire non accessibles en écriture, et peut donc être réalisée en utilisant toutes les techniques d'interaction avec les processus, y compris process_vm_writev.
Découvrez notre implémentation de cette technique à l'aide de process_vm_writev. À notre connaissance, il s'agit de la première démonstration publique d'une technique d'injection qui repose uniquement sur le syscall process_vm_writev.
Détournement de GOT
Applicable à : ptrace, procfs mem, process_vm_writev
Une autre section intéressante de la mémoire généralement accessible en écriture est la GOT. La Global Offset Table (GOT) est une section de mémoire utilisée dans le cadre du processus de relocalisation des fichiers ELF liés dynamiquement. Sans entrer dans les détails, nous nous concentrerons sur la partie qui nous intéresse, à savoir celle qui stocke les adresses des fonctions importées par le programme. Chaque fois que le programme appelle une fonction d'une bibliothèque distante, il résout son adresse mémoire en accédant à la GOT (Figure 15).
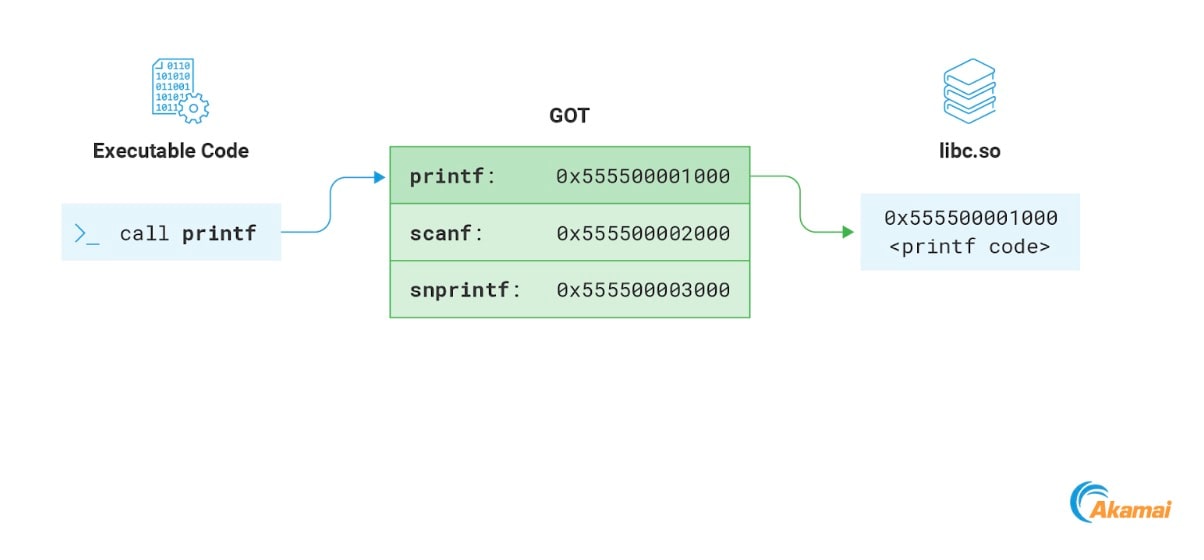 Fig. 15: Resolving a library function address using the GOT
Fig. 15: Resolving a library function address using the GOT
Ce mécanisme peut être utilisé de manière abusive par un attaquant pour détourner le flux d'exécution du processus. La mémoire GOT est normalement accessible en écriture, ce qui signifie qu'un attaquant peut écraser n'importe quelle adresse à l'intérieur avec l'adresse de sa charge utile. Au prochain appel de la fonction par le processus, le code de l'attaquant s'exécutera à sa place (Figure 16).
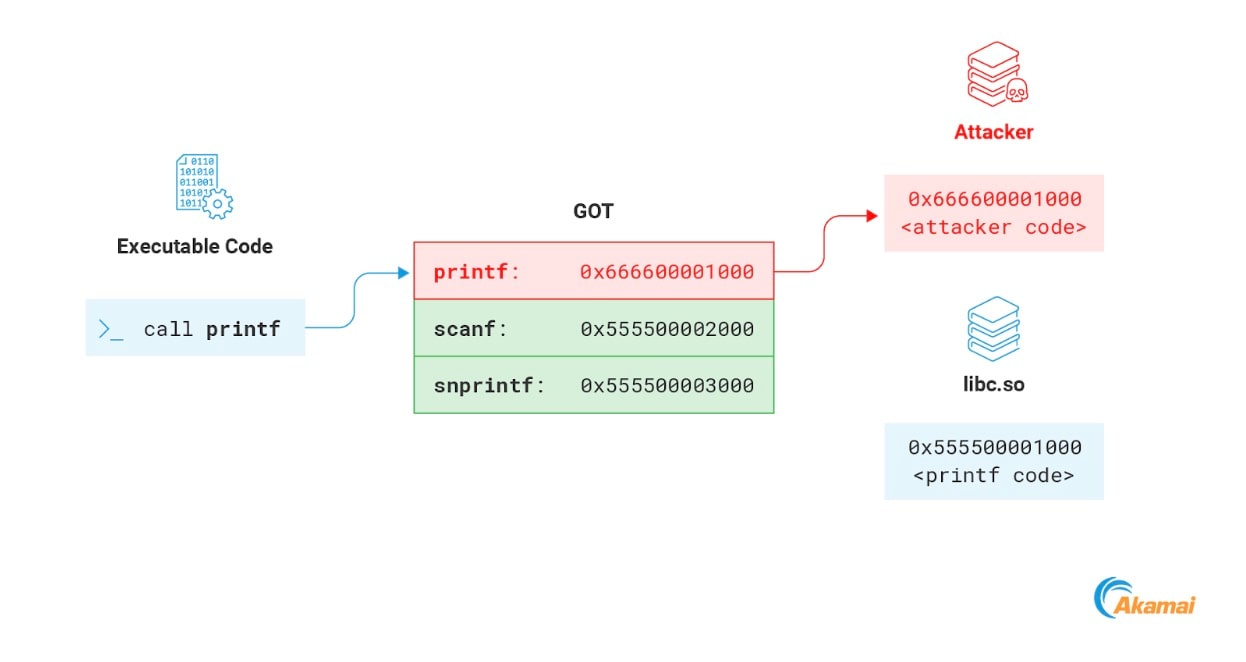 Fig. 16: Modifying a function in the GOT to point to the attacker payload
Fig. 16: Modifying a function in the GOT to point to the attacker payload
Cette technique se compose des quatre étapes suivantes :
Arrêter l'exécution du processus en envoyant un signal SIGSTOP
Identifier la région de mémoire GOT en analysant le fichier maps
Écraser les adresses de la section par l'adresse de notre charge utile
Reprendre l'exécution du processus en envoyant un signal SIGCONT
À l'appel de l'une de nos fonctions écrasées, notre charge utile s'exécute.
Une protection de la mémoire qui pourrait affecter cette attaque est la fonction RELRO complète ; la compilation d'un binaire avec ce paramètre fera en sorte que la mémoire GOT aura des autorisations d'accès en lecture seule et empêchera potentiellement les écrasements.
Malgré cela, RELRO ne sera pas en mesure d'empêcher cette attaque dans la plupart des cas.
ptrace et procfs mem contournent les autorisations de mémoire, ce qui rend RELRO non pertinent
RELRO affecte le binaire du processus lui-même, mais pas les bibliothèques qu'il a chargées. Si le processus charge une bibliothèque qui a été compilée sans RELRO, sa GOT sera accessible en écriture, ce qui nous permettra de l'écraser
Notre implémentation de cette technique en utilisant le syscall process_vm_writev est disponible dans notre référentiel.
Synthèse des primitives d'exécution
Le tableau résume toutes les primitives d'exécution possibles que nous avons décrites et les méthodes avec lesquelles elles peuvent être mises en œuvre.
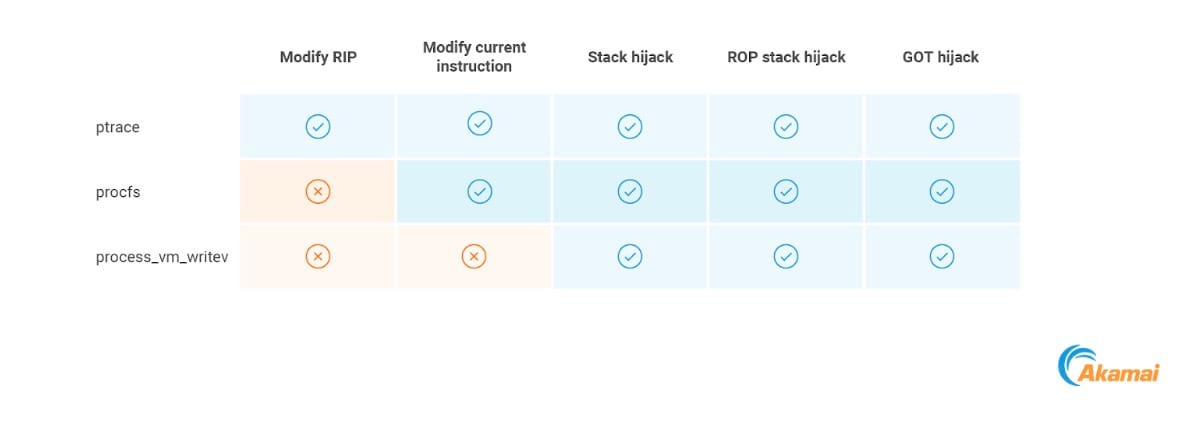 All the possible execution primitives and the methods that could be used to implement them
All the possible execution primitives and the methods that could be used to implement them
Limites de l'interaction avec les processus distants
De nombreux paramètres déterminent notre capacité à interagir avec des processus distants à l'aide des méthodes que nous venons de décrire. Dans cette section, nous aborderons brièvement les deux principaux.
ptrace_scope
ptrace_scope est un paramètre qui détermine qui est autorisé à utiliser ptrace sur les processus distants. Il peut prendre les valeurs suivantes :
0 — Les processus peuvent s'attacher à n'importe quel autre processus du système, à condition qu'il ait le même UID.
1 — Les processus normaux peuvent uniquement s'attacher à leurs processus enfants. Les processus privilégiés (avec CAP_SYS_PTRACE) peuvent toujours s'attacher à des processus non liés. Il s'agit du paramètre par défaut dans de nombreuses distributions.
2 — Seuls les processus avec CAP_SYS_PTRACE peuvent s'attacher à des processus. Cette prérogative n'est généralement accordée qu'à l'utilisateur root.
3 — L'attachement aux processus distants est désactivé.
Malgré son nom, ce paramètre affecte également la possibilité d'accéder au fichier procfs mem des processus distants et de leur appliquer process_vm_writev.
L'attribut « dumpable »
Chaque processus sous Linux est configuré avec l'attribut « dumpable », qui est défini sur true par défaut. Un processus devient automatiquement non dumpable dans certaines circonstances, ou est configuré comme tel manuellement en appelant la commande prctl.
Si un processus n'est pas dumpable, il ne sera pas possible d'y accéder à distance avec l'une des méthodes mentionnées précédemment. Ce paramètre est prioritaire sur les autres : un processus non dumpable ne peut pas être modifié à distance.
Remarque sur la récupération des processus
Toutes les méthodes d'injection que nous avons mises en évidence nécessitent de modifier l'état du processus d'une manière ou d'une autre : modification des registres du processus, écrasement de la mémoire exécutable, d'une adresse de retour sur la pile ou de la GOT. Toutes ces actions modifieront le flux d'exécution normal du processus et conduiront à un comportement inattendu une fois notre charge utile terminée.
Cela peut être problématique lorsque nous voulons que le processus cible continue à s'exécuter en même temps que notre charge utile injectée. Pour nous assurer que le processus continue à s'exécuter normalement, nous devrons restaurer son état d'origine. Le flux de récupération général comprend les huit étapes suivantes :
Sauvegarder le contenu de la mémoire que nous avons l'intention d'écraser en utilisant une primitive de lecture à distance
Sauvegarder le contenu actuel des registres du processus ; cette opération peut être effectuée à l'aide de ptrace ou par notre shellcode
Exécuter notre charge utile (par exemple, charger un fichier d'objets partagés (SO) qui exécute le code dans un thread distinct)
Lorsque l'exécution de notre charge utile est terminée, indiquer au processus d'injection que l'exécution est terminée ; cela peut être réalisé en déclenchant une interruption
Mettre en pause le processus distant
Restaurer l'état du registre de processus
Restaurer la mémoire écrasée
Reprendre l'exécution du processus
Les détails de la mise en œuvre varient légèrement en fonction de la méthode d'injection utilisée, mais il convient de suivre ce schéma général. L'article de blog d'Adam Chester sur l'injection de ptrace dans Linux fournit un exemple détaillé de la reprise d'un processus après une injection basée sur ptrace.
L'objectif de cet article était de fournir une vue d'ensemble des techniques d'injection, que les défenseurs peuvent utiliser pour se familiariser avec les techniques et ensuite élaborer une détection appropriée. Comme nous nous concentrons sur la défense, nous avons choisi de ne pas détailler les étapes de récupération pour les différentes techniques, dont les attaquants ont besoin pour les utiliser à bon escient.
Détection et prévention
Comme nous venons de le voir, il existe de nombreuses techniques permettant aux attaquants de réaliser des injections de processus sur les machines Linux. Heureusement pour nous, toutes ces méthodes nécessitent la réalisation d'actions anormales qui offrent des possibilités de détection. Les sections suivantes détaillent les différentes stratégies qui peuvent être mises en œuvre pour détecter et atténuer l'injection de processus sous Linux.
« Syscalls d'injection »
Tout au long de cet article, nous avons utilisé trois méthodes pour interagir avec les processus distants : ptrace, procfs et process_vm_writev. En raison de leur potentiel d'utilisation malveillante, ces méthodes doivent être surveillées.
Commencez par installer une solution de journalisation sur les machines Linux. La surveillance de l'exécution de syscall peut être activée à l'aide d'un utilitaire de journalisation basé sur eBPF tel que Sysmon pour Linux ou Aqua Security Tracee (qui implémente déjà des règles qui couvrent la plupart des techniques décrites dans cet article).
Après avoir mis en place la journalisation, nous recommandons aux organisations d'analyser l'utilisation normale des « syscalls d'injection » dans leur environnement et d'établir une référence des cas d'utilisation valides connus. Après la création d'une telle référence, il convient d'enquêter sur tout écart par rapport à celle-ci afin d'exclure une attaque potentielle. D'autres considérations relatives à chaque syscall sont décrites dans les sections suivantes.
Idéalement, utilisez ptrace_scope dans la mesure du possible, afin de limiter l'utilisation de ces syscalls ou de l'empêcher complètement.
ptrace
Dans la plupart des environnements de production, l'utilisation du syscall ptrace sera probablement assez rare. Après avoir établi une référence d'utilisation valide de ptrace, nous recommandons d'analyser toute utilisation anormale de ptrace.
Les requêtes ptrace suivantes permettent de modifier des processus distants et doivent être considérées comme très suspectes :
POKEDATA/POKETEXT
POKEUSER
SETREGS
procfs
L'écriture dans le fichier procfs mem peut être utilisée de manière légitime, mais ce comportement n'est probablement pas très courant. Après avoir établi une référence de cas d'utilisation valides, nous recommandons d'analyser toutes les opérations d'écriture anormales.
Il est important de tenir compte également du répertoire /proc/<pid>/task procfs. Ce répertoire contient des informations sur les différents threads du processus. Chaque thread aura son propre répertoire procfs, qui contiendra tous les principaux fichiers procfs que nous avons abordés, y compris les fichiers mem, maps et syscall.
Dans la Figure 17, nous pouvons constater que la lecture du fichier syscall à partir du répertoire /proc/<pid> équivaut à la lecture à partir du répertoire /proc/<pid>/task/<pid>, qui représente le thread principal du processus.
 Fig. 17: Example of using the /proc/<pid>/task directory
Fig. 17: Example of using the /proc/<pid>/task directory
process_vm_writev
Une fois de plus, en établissant une référence des utilisations légitimes de ce syscall, nous pouvons identifier les écarts anormaux. Tout processus inconnu qui écrit dans la mémoire d'autres processus doit être considéré comme suspect et analysé.
Détection des anomalies de processus
Outre la détection directe de l'injection de processus, nous pouvons également tenter de détecter ses effets secondaires. Une injection de code dans un processus distant modifie le comportement de ce dernier. En plus des actions normales effectuées par le processus, les actions de la charge utile sont désormais effectuées par le même processus.
Ce changement de comportement peut constituer une opportunité de détection. En établissant une référence du comportement normal du processus, nous pouvons identifier les écarts suspects qui peuvent indiquer l'existence d'une injection de code. Quelques exemples de ces comportements peuvent inclure l'apparition de processus enfants anormaux, le chargement de fichiers SO auparavant inconnus ou la communication sur des ports anormaux.
Les chercheurs Akamai ont documenté cette approche et ont démontré comment identifier l'injection de code en analysant les anomalies du réseau.
Synthèse
Les attaquants disposent d'un grand nombre d'options différentes pour effectuer des attaques par injection sur les machines Linux. Bien que ces techniques puissent être très utiles pour les attaquants, elles offrent également de précieuses possibilités de détection pour les défenseurs. En mettant en œuvre de solides capacités de journalisation et de détection sur les machines Linux, les entreprises peuvent considérablement améliorer leur posture de sécurité.
