
O Guia definitivo sobre injeção de processos do Linux


Introdução
Técnicas de injeção de processo são uma parte importante do conjunto de ferramentas de um invasor. Elas podem permitir que os agentes da ameaça executem código mal-intencionado em um processo legítimo para evitar a detecção ou colocar ganchos em processos remotos para modificar seu comportamento.
O tema da injeção de processo em máquinas Windows tem sido extensivamente pesquisado, e há um conhecimento relativamente bom sobre o assunto. Quanto às máquinas Linux, esse não é exatamente o caso. Embora alguns ótimos recursos tenho sido escritos sobre o assunto, o conhecimento sobre as diferentes técnicas de injeção no Linux parece ser relativamente baixo, em especial quando comparado com o Windows.
Nós nos inspiramos em uma visão geral da injeção do processo do Windows escrita por Amit Klein e Itzik Kotler, da SafeBreach, e visamos fornecer uma documentação abrangente sobre a injeção de processos do Linux. Vamos focar na "injeção de processo verdadeiro", técnicas que visam processos em tempo executados em tempo real. Isso significa que excluiremos métodos que exigem modificação do binário no disco, execução do processo com variáveis de ambiente específicasou abuso do processo de carregamento.
Vamos descrever os recursos do sistema operacional que facilitam a injeção de processos no Linux e as diferentes primitivas de injeção que eles permitem. Abordaremos técnicas descritas anteriormente, e também destacaremos as variantes de injeção que não foram documentadas antes. Para finalizar, falaremos sobre as estratégias de detecção e mitigação para as técnicas destacadas.
Além desta publicação, estamos lançando um repositório GitHub contendo um conjunto abrangente de códigos PoC (prova de conceito) para as diferentes primitivas de injeção descritas na publicação. Essas PoCs benignas visam ajudar a entender como é uma implementação mal-intencionada das técnicas, o que pode ajudar você a criar e testar recursos de detecção. Para obter mais informações, consulte o projeto README.
Injeção no Linux vs. injeção no Windows
O número de técnicas de injeção conhecidas em máquinas Windows é enorme e continua crescendo, desde filas de APC e transações NTFS até tabelas atom e pools de threads. O Windows expõe muitas interfaces que permitem que os invasores interajam com processos remotos e injetem processos neles.
A situação é muito diferente no domínio do Linux. A interação com processos remotos é limitada a um pequeno conjunto de chamadas de sistema, e muitos recursos que facilitam a injeção em máquinas Windows não existem. Não existem APIs para alocar memória em um processo remoto ou modificar a proteção remota da memória, e definitivamente não para criar threads remotos.
Essa diferença impacta a estrutura do ataque de injeção. No Windows, a injeção de processo consiste geralmente em três etapas: alocar →gravar → executar. Primeiro, alocamos memória no processo remoto que será usado para armazenar o código, então gravamos o código nesta memória e, finalmente, o executamos.
Com o Linux, não temos a capacidade de executar a primeira etapa: a alocação. Não há maneira direta de alocar memória em um processo remoto. Por causa disso, o fluxo de injeção será um pouco diferente: substituir → executar → recuperar. Substituímos a memória existente no processo remoto com nossa carga útil, fazemos a execução dele e, em seguida, recuperamos o estado anterior do processo para permitir que ele continue sendo executado normalmente.
Métodos de interação de processo remoto
No Linux, a interação com a memória de processos remotos é limitada a três métodos principais: ptrace, procfse process_vm_writev. As seções a seguir fornecem descrições breves para cada uma delas.
ptrace
ptrace é uma chamada de sistema usada para depurar processos remotos. O processo de inicialização inspeciona e modifica a memória do processo depurado e os registros. Depuradores como o GDB são implementados usando ptrace para controlar o processo depurado.
O ptrace oferece suporte para operações diferentes, que são especificadas por um código de solicitação ptrace Alguns exemplos notáveis incluem PTRACE_ATTACH (que se conecta a um processo), PTRACE_PEEKTEXT (que lê a partir da memória do processo) e PTRACE_GETREGS (que recupera os registros do processo). O Snippet 1 mostra um exemplo de uso do ptrace.
// Attach to the remote process
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// Get registers state
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
Snippet 1: exemplo de uso do ptrace para recuperar os registros de um processo remoto
procfs
procfs é um pseudo-sistema de arquivos especial que atua como uma interface para executar processos no sistema. Ele pode ser acessado por meio do diretório /proc (Figura 1).
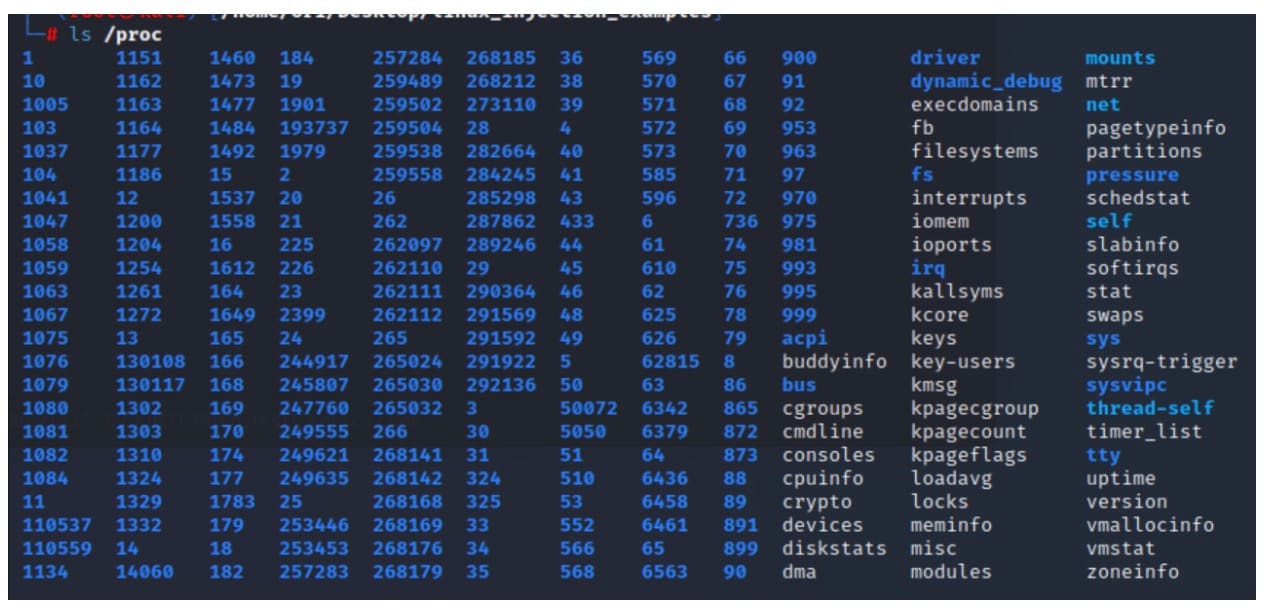 Fig. 1: A directory listing of the /proc directory on a Linux machine
Fig. 1: A directory listing of the /proc directory on a Linux machine
Cada processo é representado como um diretório, nomeado de acordo com seu PID. Nesse diretório podemos encontrar arquivos que fornecem informações sobre o processo. Por exemplo, o arquivo cmdline mantém a linha de comando de processo, o arquivo environ contém as variáveis de ambiente de processo, e assim por diante.
O procfs também possibilita interagir com a memória de processo remoto. Dentro de cada diretório de processo, encontraremos o arquivo mem, um arquivo especial que representa todo o espaço de endereço do processo. Acessar o arquivo mem de um processo em um determinado deslocamento é equivalente a acessar a memória do processo no mesmo endereço.
No exemplo na Figura 2, usamos o utilitário xxd para ler 100 bytes do arquivo mem de processo, começando em um deslocamento especificado.
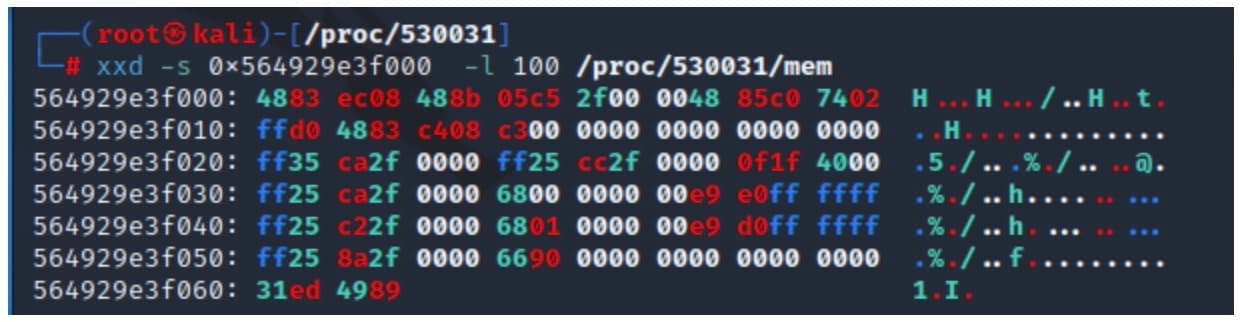 Fig. 2: Using xxd to read the procfs mem file
Fig. 2: Using xxd to read the procfs mem file
Se inspecionarmos o mesmo endereço na memória usando GDB, notaremos que o conteúdo é idêntico (Figura 3).
 Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
Fig. 3: Using GDB to inspect the process memory at the same offset we read from the procfs mem file
O arquivo maps é outro arquivo interessante que pode ser encontrado no diretório de processo (Figura 4). Esse arquivo contém informações sobre as diferentes regiões de memória no espaço de endereço do processo, incluindo seus intervalos de endereços e permissões de memória.
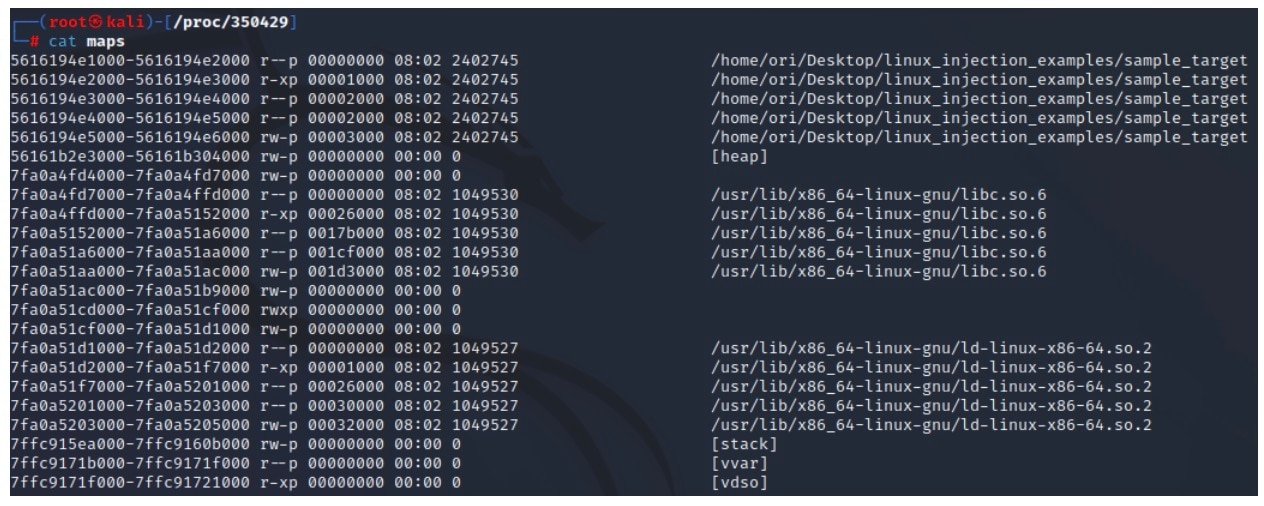 Fig. 4: Example contents of a process maps file
Fig. 4: Example contents of a process maps file
Nas próximas seções, veremos como a capacidade de identificar regiões de memória com permissões específicas pode ser muito útil.
process_vm_writev
O terceiro método para interagir com a memória de processo remoto é a chamada do sistema process_vm_writev. Esta chamada de sistema permite gravar dados para o espaço de endereço de um processo remoto.
process_vm_writev recebe um ponteiro para um buffer local e copia seu conteúdo para um endereço especificado no processo remoto. Um exemplo de process_vm_writev em uso é mostrado no Snippet 2.
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our data in the local iovec
local[0].iov_base = data;
local[0].iov_len = data_len;
// Point the remote iovec to the address in the remote process
remote[0].iov_base = (void *)remote_address;
remote[0].iov_len = data_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
Snippet 2: usar process_vm_writev para gravar dados em um processo remoto
Gravar código em um processo remoto
Agora que entendemos os diferentes métodos para interagir com outros processos, veremos como eles podem ser usados para executar a injeção de código. O primeiro passo do ataque por injeção será gravar nosso código shellcode na memória do processo remoto. Como mencionamos, no Linux não há maneira direta de alocar nova memória em um processo remoto. Isso significa que não podemos criar uma nova seção de memória, teremos que utilizar a memória existente do processo de destino.
Para que o código possa ser executado, precisaremos gravá-lo em uma região de memória com permissões de execução. Podemos encontrar essa região analisando o arquivo procfs que mencionamos e identificando uma região de memória com permissões de execução (x) (Figura 5).
 Fig. 5: Identifying an executable memory region in the process maps file
Fig. 5: Identifying an executable memory region in the process maps file
Existem dois tipos de regiões executáveis que podemos encontrar: gravável e não gravável. As seções a seguir mostrarão quando e como cada uma delas pode ser usada.
Gravar código para a memória RX
Aplicável a:ptrace, procfs mem
O ideal seria identificar uma região de memória com permissões de gravação e execução, o que nos permitiria gravar o código e executá-lo. Na realidade, a maioria dos processos não terá uma região com tais permissões, pois não é considerada uma prática recomendada alocar memória WX. Em vez disso, geralmente estamos limitados à leitura e execução de permissões.
Mas acontece que essa limitação pode ser subvertida usando dois dos métodos que acabamos de descrever: ptrace e procfs mem. Ambos os mecanismos são implementados de modo que podem ignorar as permissões de memória e gravar em qualquer endereço,mesmo sem permissões de gravação. Outros detalhes sobre esse comportamento para procfs podem ser encontrados nesta publicação do blog.
Isso significa que, independentemente das permissões de gravação, podemos sempre usar ptrace ou procfs mem para gravar o código em uma região de memória executável remota.
ptrace
Para gravar a carga útil em um processo remoto, podemos usar as solicitações ptrace POKETEXT ou POKEDATA. Essas solicitações idênticas permitem gravar uma palavra de dados na memória do processo remoto. Ao chamá-las repetidamente, é possível copiar toda a nossa carga útil para a memória do processo de destino. Um exemplo disso é mostrado na figura 3.
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
wait(NULL);
// write payload to remote address
for (size_t i = 0; i < payload_size; i += 8, payload++)
{
ptrace(PTRACE_POKETEXT, pid, address + i, *payload);
}
Snippet 3: usar ptrace POKETEXT para gravar a carga útil para a memória de processo remoto
procfs mem
Para gravar a carga útil para um processo remoto usando procfs, basta gravá-la no arquivo mem no deslocamento correto. Qualquer alteração feita no arquivo mem é aplicada à memória do processo. Para executar essas operações, podemos usar as APIs de arquivo normais (Snippet 4).
// Open the process mem file
FILE *file = fopen("/proc/<pid>/mem", "w");
// Set the file index to our required offset, representing the memory address
fseek(file, address, SEEK_SET);
// Write our payload to the mem file
fwrite(payload, sizeof(char), payload_size, file);
Snippet 4: usar o arquivo procfs mem para gravar dados em uma memória de processo remota
Gravar código na memória WX
Aplicável a:ptrace, procfs mem, process_vm_writev
Conforme abordamos, tanto ptrace quanto procfs mem ignoram permissões de memória e permitem gravar o código nas regiões de memória não graváveis. Com process_vm_writev, no entanto, esse não é o caso. process_vm_writev adere às permissões de memória e, portanto, só nos permite gravar dados em regiões de memória graváveis.
Por isso, nossa única opção é procurar regiões graváveis. Nem todos os processos vão incluir tais regiões, mas certamente podemos encontrar aquelas que incluem.
O comando no Snippet 5 digitará o arquivo maps de todos os processos no sistema e identificará regiões com permissões de gravação e execução (Figura 6).
find /proc -type f -wholename "*/maps" -exec grep -l "wx" {} +
Snippet 5: usar o comando "find" para identificar processos com regiões de memória de gravação e execução
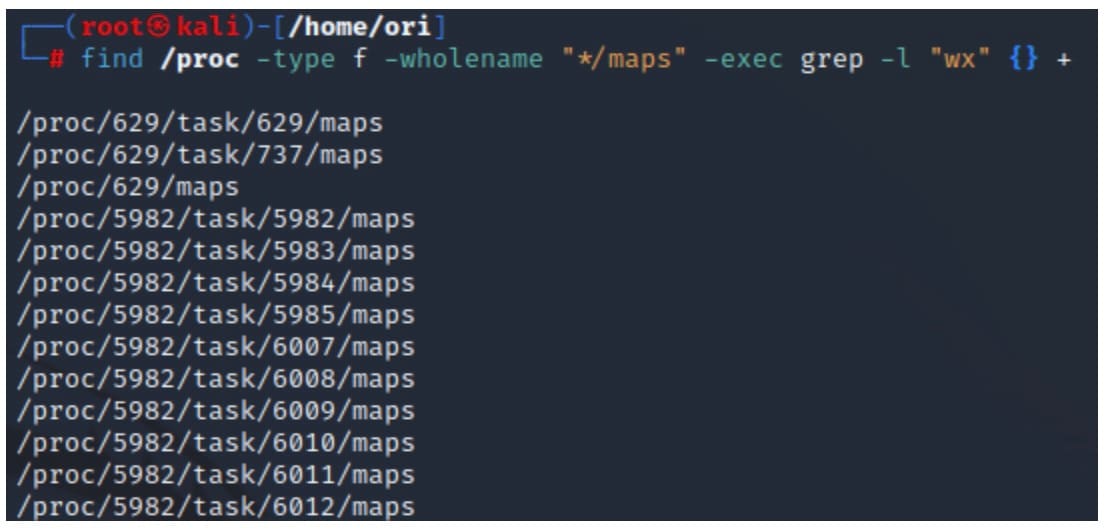 Fig. 6: Example output of finding processes with WX memory regions
Fig. 6: Example output of finding processes with WX memory regions
Após identificar essa região, podemos usar process_vm_writev para gravar o código nela (Snippet 6).
// Initialize local and remote iovec structs used to perform the syscall
struct iovec local[1];
struct iovec remote[1];
// Place our payload in the local iovec
local[0].iov_base = payload;
local[0].iov_len = payload_len;
// Point the remote iovec to the address of our wx memory region
remote[0].iov_base = (void *)wx_address;
remote[0].iov_len = payload_len;
// Write the local data to the remote address
process_vm_writev(pid, local, 1, remote, 1, 0);
Snippet 6: usar process_vm_writev para gravar uma carga útil em uma região WX remota
Sequestro de fluxo de execução remota
Depois de gravar o código para a memória do processo remoto, precisaremos executá-lo. Nas próximas seções, descreveremos diferentes técnicas que podemos usar para fazer isso.
Nossa pesquisa focou em máquinas amd64. Algumas pequenas diferenças podem se aplicar a outras arquiteturas, mas os conceitos gerais devem permanecer os mesmos.
Modificar o ponteiro de instrução do processo
Aplicável a:ptrace
Quando nos conectamos a um processo usando o ptrace, sua execução é pausada e podemos inspecionar e modificar os registros do processo, inclusive o ponteiro de instruções. Para fazer isso, use as solicitações ptrace SETREGS e GETREGS. Para modificar o fluxo de execução do processo, podemos usar ptrace para modificar o ponteiro de instruções para o endereço do nosso shellcode.
No exemplo no Snippet 7, realizamos os seguintes três passos:
Recuperar os valores de registro atuais usando a solicitação ptrace GETREGS
Modificar o ponteiro de instruções para apontar para o nosso endereço de carga útil (incrementado por 2, que discutiremos mais tarde)
Aplicar a alteração ao processo usando a solicitação SETREGS
// Get old register state.
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
// Modify the instruction pointer to point to our payload
regs.rip = payload_address + 2;
// Modify the registers
ptrace(PTRACE_SETREGS, pid, NULL, ®s);
Snippet 7: usar o ptrace SETREGS para direcionar o ponteiro de instruções para nossa carga útil
SETREGS é a maneira "tradicional" e mais documentada de modificar os registros de processo, mas outra solicitação ptrace também pode ser usada para realizar isso: POKEUSER.
A solicitação POKEUSER permite gravar dados no processo USER area, uma estrutura (definida em sys/user.h) que contém informações sobre o processo, incluindo os registros. Ao chamar POKEUSER com o deslocamento correto, podemos substituir o ponteiro de instruções com o endereço do nosso código e alcançar o mesmo resultado que antes (Snippet 8).
// calculate the offset of the RIP register, based on the USER struct definition
rip_offset = 16 * sizeof(unsigned long);
ptrace(PTRACE_POKEUSER, pid, rip_offset, payload_address + 2);
Snippet 8: usar o ptrace POKEUSER para direcionar o ponteiro de instruções para nossa carga útil
A implementação de uso do POKEUSER para modificar o RIP pode ser encontrada em nosso repositório.
RIP += 2: Quando e por quê?
Como mostrado no Snippet 7 e no Snippet 8, quando modificamos o RIP para o endereço de nossa carga útil, também estamos incrementando-o em 2. Isso é feito para acomodar um comportamento interessante do ptrace: às vezes, após desanexar um processo com ptrace, o valor de RIP será diminuído em 2. Vamos entender por que isso acontece.
Quando nos vinculamos a um processo usando o ptrace, podemos interromper um syscall que está sendo executado no momento no kernel. Para garantir que o syscall seja executado corretamente, o kernel o executará novamente quando nos desconectarmos do processo.
Durante a execução do syscall, o RIP já aponta para a próxima instrução a ser executada. Para executar novamente o syscall, o kernel diminuirá o valor de RIP em 2, o tamanho da instrução do syscall no amd64. Após essa alteração, o RIP apontará para a instrução de syscall novamente, fazendo com que ele seja executado outra vez (Figura 7).
 Fig. 7: The effect of using ptrace on a process during syscall execution
Fig. 7: The effect of using ptrace on a process during syscall execution
Se, por acaso, interrompermos um processo durante um syscall ao realizar a injeção de código, poderão ocorrer problemas. Após modificar o RIP para apontar para o nosso código, o kernel ainda diminuirá o novo valor em 2, levando a uma lacuna de 2 bytes antes do nosso código shellcode, o que provavelmente fará com que ele falhe (Figura 8).
 Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Fig. 8: Using ptrace to point RIP to our shellcode results in a junk instruction executing
Para acomodar esse comportamento, tomaremos duas medidas: prefixar nosso shellcode com duas instruções sem operação (NOP) e apontar o RIP para o endereço do nosso shellcode + 2. Essas duas etapas vão garantir que o nosso código seja executado corretamente.
Se interrompermos o processo durante um syscall, o kernel diminuirá o novo valor do RIP, o que resultará no direcionamento para o endereço inicial do código shellcode que contém dois NOPs que vamos deslocar para o nosso código real.
Se não houver interrupção do processo durante um syscall, o novo RIP não será diminuído, fazendo com que os dois NOPs sejam ignorados e nosso código seja executado. Esses dois cenários são representados na Figura 9.
 Fig. 9: Overcoming the ptrace RIP interaction
Fig. 9: Overcoming the ptrace RIP interaction
Modificar a instrução atual
Aplicável a:ptrace, procfs mem
Outro arquivo interessante no procfs é o arquivo syscall. Esse arquivo contém informações sobre o syscall, que é executado atualmente pelo processo: o número syscall, os argumentos passados para ele, o ponteiro da pilha e o ponteiro da instrução do processo, que é o mais interessante para o nosso caso (Figura 10). Mesmo que o processo não esteja executando um syscall, os ponteiros de pilha e instrução do processo ainda estarão presentes no arquivo syscall.
 Fig. 10: The structure of the procfs syscall file
Fig. 10: The structure of the procfs syscall file
Essa informação nos permite assumir o controle sobre o fluxo de execução do processo, e saber o endereço da próxima instrução a ser executada nos permite substituí-lo com nossas próprias instruções.
Para implementar isso, um invasor pode executar as seguintes quatro etapas:
Interromper a execução do processo enviando um sinal SIGSTOP
Identificar o endereço da próxima instrução a ser executada lendo o arquivo syscall do processo
Gravar um shellcode no endereço identificado
Reiniciar a execução do processo enviando um sinal SIGCONT
O Snippet 9 mostra um pseudocódigo para este processo.
// Suspend the process by sending a SIGSTOP signal
kill(pid, SIGSTOP);
// Open the syscall file
FILE *syscall_file = fopen("/proc/<pid>/syscall", "r");
// Extract the instruction pointer from the syscall file
long instruction_pointer = ...
// Write our payload to the address of the current instruction pointer using
procfs mem
FILE *mem_file = fopen("/proc/<pid>/mem", "w");
fseek(mem_file, instruction_pointer, SEEK_SET);
fwrite(payload, sizeof(char), payload_size, mem_file);
// Resume execution by sending a SIGCONT signal
kill(pid, SIGCONT);
Snippet 9: usar o procfs mem para modificar a memória do processo no endereço atual do ponteiro de instruções para sequestrar o fluxo de execução do processo
O exemplo no Snippet 9 implementa essa técnica usando o arquivo procfs mem, mas é importante notar que ptrace POKETEXT também pode ser usado para gravar a carga útil na memória.
Como mencionamos, o process_vm_writev é limitado por permissões de memória, o que significa que ele só pode modificar regiões de memória graváveis. A probabilidade de encontrar código em execução a partir de uma região de memória WX é baixa, o que reduz a confiabilidade do process_vm_writev para esse primitivo.
Confira nossa implementação desta técnica usando o arquivo procfs mem.
Sequestro de pilha
Aplicável a:ptrace, procfs mem file, process_vm_writev
Outra região da memória interessante é a pilha de processos, que também pode ser identificada usando o arquivo maps. Embora a memória de pilha não seja executável (Figura 11), ainda podemos usá-la para sequestrar o fluxo de execução do processo.
 Fig. 11: Identifying the process stack address using the maps file
Fig. 11: Identifying the process stack address using the maps file
Sempre que uma função é chamada, o endereço de retorno da função de chamada é empurrado para a pilha. Quando a função termina de ser executada, o processador pega esse endereço de retorno da pilha e salta para ele (Figura 12).
 Fig. 12: Return address on the stack pointing to an address in main
Fig. 12: Return address on the stack pointing to an address in main
Para abusar desse mecanismo, podemos identificar um endereço de retorno na pilha e substituí-lo por um novo endereço que aponta para o nosso shellcode. Assim que a função atual terminar a execução, nosso código será executado (Figura 13).
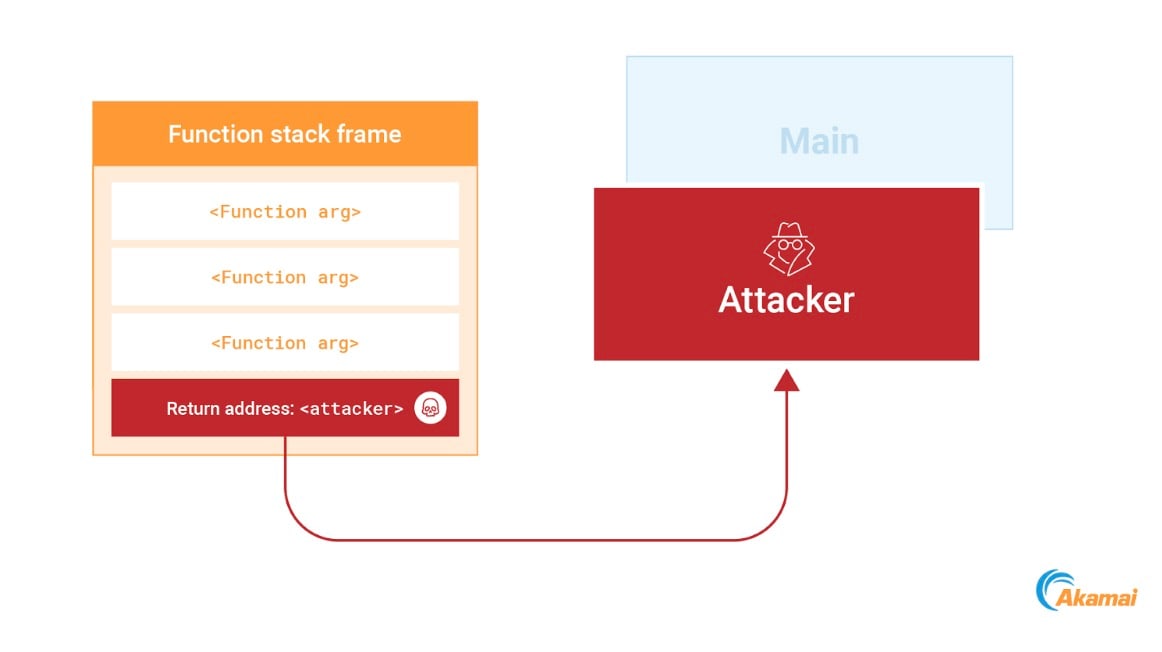 Fig. 13: Overwriting a return address on the stack to point to the attackers code
Fig. 13: Overwriting a return address on the stack to point to the attackers code
Para identificar o topo da pilha, podemos analisar o arquivo procfs syscall que mencionamos antes, que também contém o valor do registro do ponteiro da pilha.
Os seis passos a seguir podem ser usados para realizar essa técnica:
Interromper a execução do processo enviando um sinal SIGSTOP
Identificar o ponteiro da pilha do processo analisando o arquivo procfs syscalls
Verificar a pilha de processo e identificar um endereço de retorno
Usar qualquer uma das primitivas de gravação mencionadas anteriormente para injetar nossa carga útil na memória do processo
Substituir o endereço de retorno pelo endereço da nossa carga útil
Reiniciar a execução do processo enviando um sinal SIGCONT
Quando a execução da função atual termina, nossa carga útil é executada.
Como todos os métodos de interação de processo nos permitem modificar a pilha, todos eles podem ser usados para implementar essa técnica. A implementação desta técnica usando o syscall process_vm_writev pode ser encontrada em nosso repositório.
Sequestro de pilha de ROP
Aplicável a:ptrace, procfs mem file, process_vm_writev
A técnica de sequestro de pilha é interessante: ela permite sequestrar o fluxo de execução do processo sem modificar nenhuma memória executável ou registros. Apesar disso, para que ela possa ser colocada em prática, ainda é necessário acessar o shellcode que reside em uma região de memória executável. Podemos tentar encontrar uma região WX (como descrevemos) ou usar ptrace/procfs mem para gravar em uma memória não gravável.
E se quisermos evitar essas ações? Temos outro truque em nossa manga: a programação orientada por retorno (ROP). Usando nossa capacidade de gravar na pilha de processos, podemos substituí-la por uma cadeia de ROP (Figura 14). Como utilizamos gadgets executáveis que já residem na memória do processo, podemos construir uma carga útil sem gravar nenhum novo código executável.
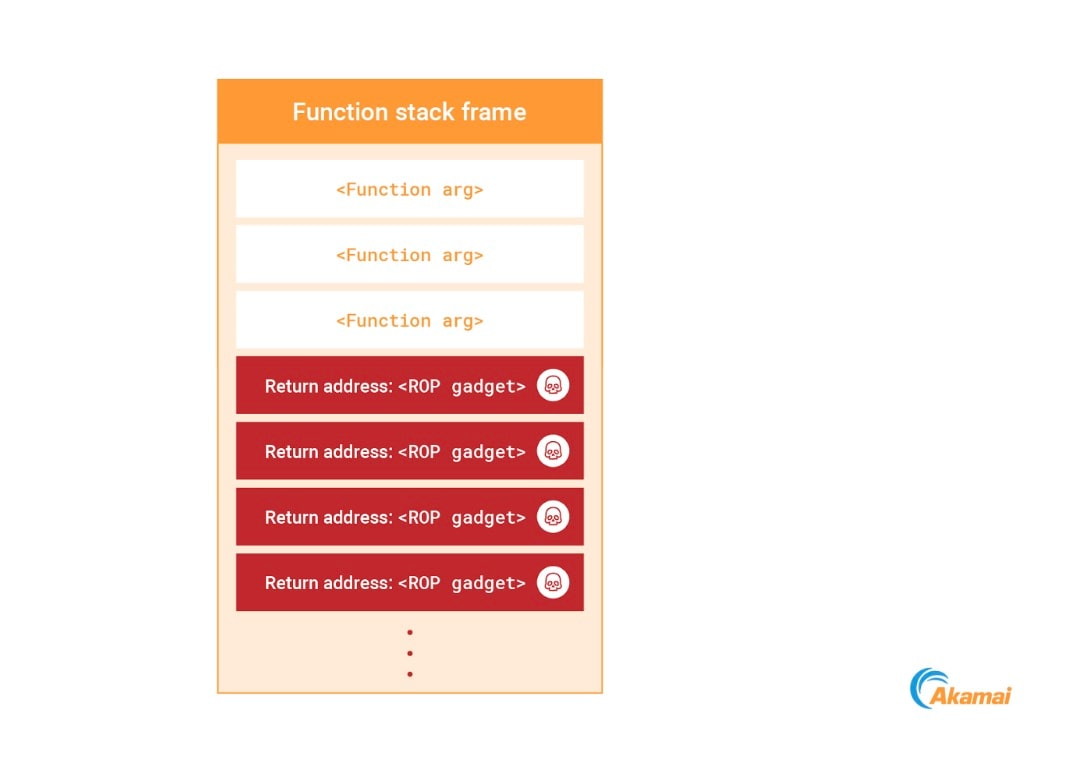 Fig. 14: Injecting a ROP chain to the process stack
Fig. 14: Injecting a ROP chain to the process stack
Esta técnica consistirá nos seguintes sete passos:
Interromper a execução do processo enviando um sinal SIGSTOP
Identificar o ponteiro da pilha do processo analisando o arquivo procfs syscalls
Verificar a pilha de processo e identificar um endereço de retorno
Usar qualquer uma das primitivas de gravação mencionadas anteriormente para injetar nossa carga útil em uma região de memória gravável sem permissões de execução
Criar uma cadeia de ROP para chamar mprotect e marcar a região de memória do nosso executável shellcode
Substituir a pilha com a cadeia ROP, começando pelo endereço do endereço de retorno identificado
Reiniciar a execução do processo enviando um sinal SIGCONT
Quando a função atual termina a execução, nossa cadeia de ROP é executada, tornando o código shellcode executável e pulando para ele.
Este conceito foi demonstrado por Rory McNamara, da AON Cyber Labs, em sua publicação do blog que fala sobre a injeção procfs mem.
Com essa técnica, não é necessário modificar nenhuma região de memória não gravável, portanto, ela pode ser realizada usando todas as técnicas de interação de processo, incluindo process_vm_writev.
Confira nossa implementação desta técnica usando process_vm_writev. Até onde sabemos, esta é a primeira demonstração pública de uma técnica de injeção que depende apenas do syscall process_vm_writev.
Sequestro de GOT
Aplicável a:ptrace, procfs mem file, process_vm_writev
Outra seção de memória interessante que geralmente é gravável é o GOT. A GOT (Tabela de deslocamento global) é uma seção de memória usada como parte do processo de realocação de arquivos ELF vinculados dinamicamente. Não vamos entrar em muitos detalhes aqui, mas sim focar na parte que é relevante para o nosso propósito: a seção que armazena endereços de funções importadas pelo programa. Sempre que o programa chama uma função de uma biblioteca remota, ele resolve o endereço de memória acessando a GOT (Figura 15).
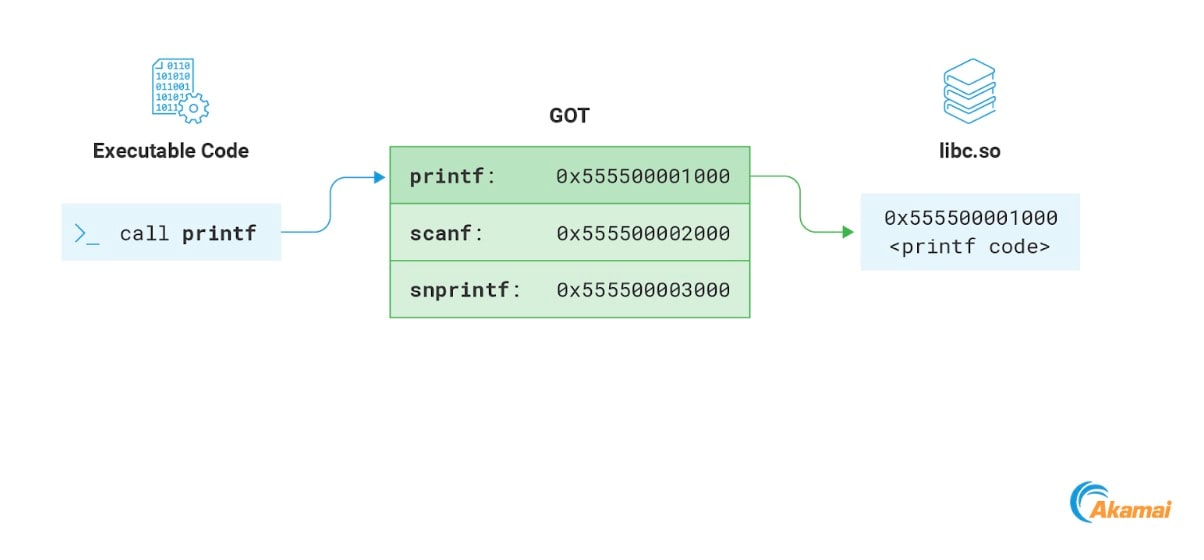 Fig. 15: Resolving a library function address using the GOT
Fig. 15: Resolving a library function address using the GOT
Esse mecanismo pode ser violado por um invasor para sequestrar o fluxo de execução do processo. A memória GOT normalmente é gravável, o que significa que um invasor pode substituir qualquer um dos endereços dentro dela com o endereço de sua carga útil. Na próxima vez que a função for chamada pelo processo, o código invasor será executado (Figura 16).
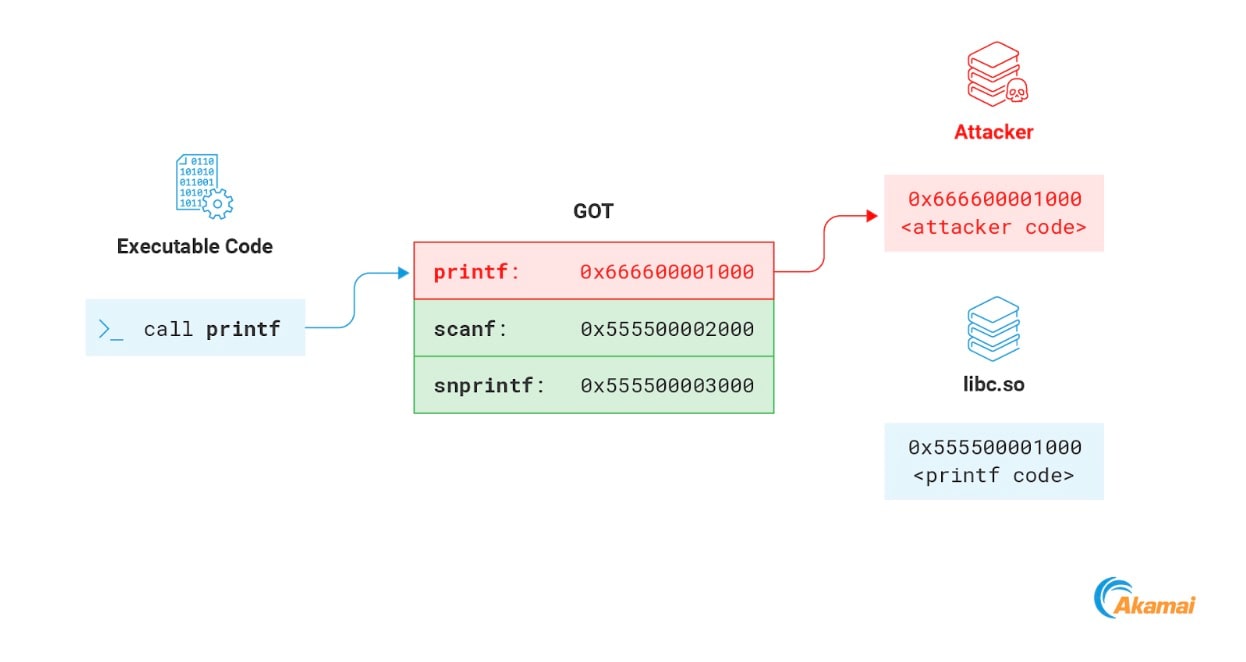 Fig. 16: Modifying a function in the GOT to point to the attacker payload
Fig. 16: Modifying a function in the GOT to point to the attacker payload
Esta técnica consistirá nos seguintes quatro passos:
Interromper a execução do processo enviando um sinal SIGSTOP
Identificar a região da memória GOT analisando o arquivo maps
Substituir endereços na seção pelo endereço da nossa carga útil
Reiniciar a execução do processo enviando um sinal SIGCONT
Quando qualquer uma de nossas funções substituídas são chamadas, nossa carga útil é executada.
Uma proteção de memória que pode afetar este ataque é full RELRO, e a compilação de um binário com esta configuração fará com que a memória GOT tenha permissões somente de leitura e potencialmente impeça substituições.
Apesar disso, o RELRO não será capaz de evitar esse ataque na maioria dos casos.
ptrace e procfs mem ignoram permissões de memória, tornando o RELRO irrelevante
o RELRO afeta o próprio binário de processo, mas não suas bibliotecas carregadas. Se o processo carregar qualquer biblioteca compilada sem o RELRO, sua GOT será gravável, possibilitando que seja substituída
A implementação desta técnica usando o syscall process_vm_writev pode ser encontrada em nosso repositório.
Resumo de primitivos de execução
A tabela resume todas as primitivas de execução possíveis que descrevemos, e com quais métodos elas poderiam ser implementados.
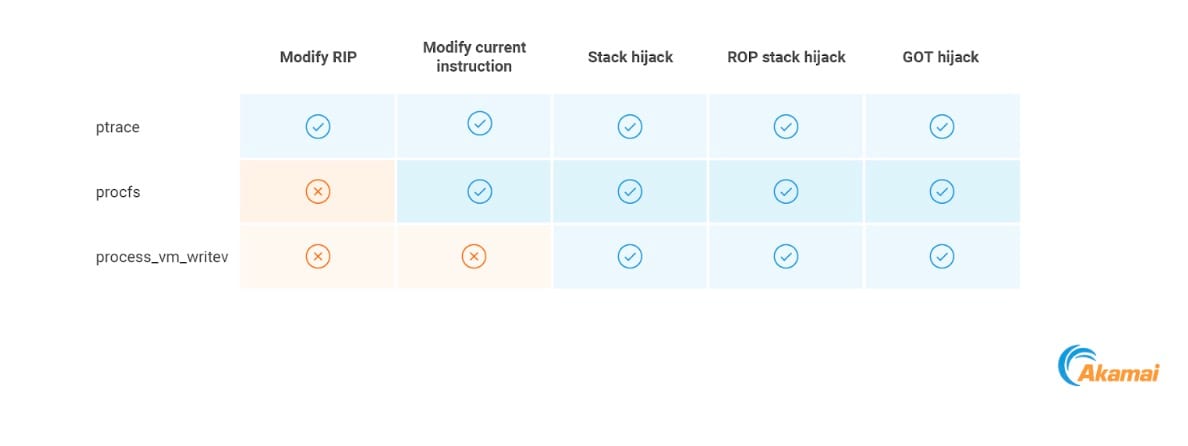 All the possible execution primitives and the methods that could be used to implement them
All the possible execution primitives and the methods that could be used to implement them
Limitações na interação de processo remoto
Existem várias configurações que determinarão nossa capacidade de interagir com processos remotos usando os métodos que acabamos de descrever. Nesta seção, vamos abordar brevemente os dois principais.
ptrace_scope
ptrace_scope é uma configuração que determina quem tem permissão para usar ptrace em processos remotos. Pode ter os seguintes valores:
0 – Os processos podem ser anexados a qualquer outro processo no sistema, caso tenha o mesmo UID.
1 – Os processos normais só podem ser anexados aos processos de seus filhos. Processos privilegiados (com CAP_SYS_PTRACE) ainda pode ser anexados a processos não relacionados. Esta é a configuração padrão em muitas distribuições.
2 – Apenas processos com CAP_SYS_PTRACE podem ser anexados a processos. Esta capacidade é geralmente concedida apenas ao root.
3 – O anexo a processos remotos está desativado.
Apesar do nome, essa configuração também afetará a capacidade de acessar o arquivo procfs mem de processos remotos e usar o process_vm_writev neles.
O atributo "dumpable"
Cada processo no Linux é configurado com o atributo "dumpable", que é definido como verdadeiro por padrão. Um processo se tornará automaticamente "undumpable" quando determinadas circunstâncias, ou configurado como tal manualmente ao chamar prctl.
Se um processo não for "dumpable", não será possível acessá-lo remotamente com nenhum dos métodos mencionados anteriormente. Essa configuração substituirá outras: um processo "dumpable" não pode ser modificado remotamente.
Uma observação sobre a recuperação do processo
Todos os métodos de injeção que destacamos exigem modificar o estado do processo de alguma maneira: modificar os registros do processo, ou então substituir a memória executável, um endereço de retorno na pilha ou a GOT. Todas essas ações alterarão o fluxo normal de execução do processo e causarão um comportamento inesperado após o término da nossa carga útil.
Isso pode ser problemático quando queremos que o processo de destino continue em execução com nossa carga útil injetada. Para garantir que o processo continue a ser executado normalmente, precisaremos restaurar seu estado original. O fluxo de recuperação geral consistirá nos seguintes oito passos:
Fazer backup do conteúdo de memória que planejamos substituir usando um primitivo de leitura remota
Fazer backup do conteúdo atual dos registros do processo. Isso pode ser feito usando ptrace ou nosso shellcode
Executar nossa carga útil (por exemplo, carregar um arquivo de SO (objeto compartilhado) que executa código em um thread separado)
Quando nossa carga útil for concluída, indique ao processo de injeção que a execução está concluída. Isso pode ser feito executando uma interrupção
Pausar o processo remoto
Restaurar o estado de registro do processo
Restaurar a memória substituída
Retomar a execução do processo
Os detalhes da implementação podem variar um pouco dependendo do método de injeção usado, mas esta descrição geral deve ser seguida. A publicação do blog de Adam Chester sobre injeção de ptrace no Linux exemplifica em detalhes a recuperação de processo após uma injeção baseada em ptrace.
Nosso objetivo com essa publicação foi mostrar uma visão geral das técnicas de injeção, que os defensores podem usar para se familiarizar com as técnicas e, em seguida, criar a detecção adequada. Como nosso foco é a defesa, optamos por não detalhar as etapas de recuperação para as diferentes técnicas, que os atacantes precisam para utilizá-las totalmente como armas.
Detecção e mitigação
Como acabamos de discutir, existem muitas técnicas que permitem que os invasores executem injeção de processos em máquinas Linux. Felizmente para nós, todos esses métodos exigem a realização de ações anômalas que fornecem oportunidades de detecção. As próximas seções mostrarão em detalhes as diferentes estratégias que podem ser implementadas para detectar e mitigar a injeção de processos no Linux.
"Syscalls de injeção"
Ao longo desta publicação, utilizamos três métodos para interagir com processos remotos: ptrace, procfs e process_vm_writev. Devido ao potencial de uso mal-intencionado, esses métodos devem ser monitorados.
Comece instalando uma solução de registro em máquinas Linux. Para ativar o monitoramento da execução de syscall, use um utilitário de registro baseado em eBPF, como Sysmon para Linux ou Aqua Security Tracee (isso já implementa regras que cobrem muitas das técnicas descritas nesta publicação).
Após estabelecer o registro, recomendamos que as organizações analisem o uso normal dos "syscalls de injeção" em seu ambiente e criem uma linha de base de casos de uso válidos conhecidos. Depois que tal linha de base é criada, qualquer desvio dela deve ser investigado para descartar um potencial ataque. Outras considerações por syscall são descritas nas próximas seções.
O ideal é usar o ptrace_scope quando possível para limitar o uso desses syscalls ou impedi-los por completo.
ptrace
Na maioria dos ambientes de produção, o uso do ptrace syscall provavelmente será bastante raro. Após estabelecer uma linha de base de uso de ptrace válido, recomendamos analisar qualquer uso anormal do ptrace.
As seguintes solicitações de ptrace permitem modificar os processos remotos e devem ser consideradas altamente suspeitas:
POKEDATA/POKETEXT
POKEUSER
SETREGS
procfs
Existem alguns casos de uso legítimos relacionados à gravação no arquivo procfs mem, mas esse comportamento provavelmente não será muito comum. Após criar uma linha de base de casos de uso válidos, recomendamos analisar quaisquer operações de gravação anormais.
É importante considerar também o diretório /proc</>pid /tarefa procfs. Esse diretório expõe informações sobre os diferentes threads do processo. Cada thread terá seu próprio diretório procfs, que conterá todos os principais arquivos procfs que abordamos, incluindo os arquivos mem, maps e syscall.
Na Figura 17, vemos que a leitura do arquivo syscall do diretório /proc/<pid> é equivalente à leitura do diretório /proc/<pid>/task/<pid>, que representa o thread principal do processo.
 Fig. 17: Example of using the /proc/<pid>/task directory
Fig. 17: Example of using the /proc/<pid>/task directory
process_vm_writev
Ao criar uma linha de base de usos legítimos deste syscall, podemos identificar desvios anômalos. Qualquer processo desconhecido que grave na memória de outros processos deve ser considerado suspeito e analisado.
Detectar anomalias do processo
Além de detectar diretamente a injeção do processo, também podemos tentar detectar seus efeitos colaterais. Quando o código é injetado em um processo remoto, ele mudará a maneira como o processo se comporta. Além das ações normais tomadas pelo processo, as ações da carga útil agora também são realizadas pelo mesmo processo.
Essa mudança de comportamento pode proporcionar uma oportunidade de detecção. Ao criar um padrão do comportamento normal do processo, é possível identificar desvios suspeitos que podem indicar a injeção de código. Alguns exemplos desses comportamentos podem incluir o surgimento de processos filhos anômalos, o carregamento de arquivos SO que antes não estavam presentes ou a comunicação por portas anormais.
Os pesquisadores da Akamai documentaram essa abordagem e demonstraram como identificar a injeção de código analisando anomalias de rede.
Resumo
Os invasores têm muitas opções diferentes para executar ataques de injeção em máquinas Linux. Embora essas técnicas possam ser muito úteis para os invasores, elas também oferecem oportunidades valiosas de detecção para os defensores. Ao implementar recursos sólidos de registro e detecção em máquinas Linux, as organizações podem melhorar significativamente a postura de segurança.