
(Micro)Segmentation from a Practical Perspective


Introduction
Network segmentation is difficult to implement. No, scratch that. Network segmentation is easy to implement; segmenting the network in a way that doesn’t impact the end user or network operability while making it secure is nigh impossible.
We (the Akamai Security Intelligence Group researchers) often mention network segmentation as a mitigation strategy for lateral movement and the various other threats we report on — whether it’s in our Patch Tuesday advisories, our malware reports, vulnerability advisories, or other research pieces.
In this post, we’ll provide practical, concrete segmentation strategies and realistic best practices for defenders. Our aim is to only discuss segmentation strategies that are actionable and would not affect network operability or end-user experience very much while still having a significant security benefit.
Although proper segmentation is challenging, there are some quick wins when it comes to protecting your network. To highlight this, we’ve included several segmentation strategies that deal with different stages of a network breach.
Please note that real-world networks differ from one another; although we aim to provide general recommendations, the strategies may require adjustments to be applicable for you.
Table of contents
What is network segmentation?
Before we can jump into best practices and strategies, we first need to define our playground. Network segmentation involves “breaking” the network into parts (segments) and defining who can access what, and in what way (for example, web servers may only be accessed via HTTP/S).
Traditionally, this has been achieved using VLANs and physical firewalls, but lately we see more and more software-based approaches to firewalls and segmentation (Akamai Guardicore Segmentation, for example). We won’t recommend one way or the other — there are pros and cons to both approaches. Our recommended policies and strategies are vendor-agnostic and can apply everywhere.
When you move on from controlling traffic using VLANs, access control lists (ACLs), and IP ranges to using custom labels that are vendor-agnostic, you enter the realm of microsegmentation. All our strategies in this blog post will assume that we’re using microsegmentation.
It should be possible to adapt the strategies and guidelines to not require segmentation, but the process to define all the VLANs, ACLs, and IP lists, and then maintain them is probably impractical, or will come with the immediate burnout of all network admins and engineers. (Try to define the IP range/group of all finance servers. It might be doable, but can you maintain that list accurately for long? That’s also only one server group; in an enterprise network, you’ll have many more — end users, domain controllers, domain admins, printers, etc.)
Network segmentation guidelines
Before we can discuss how to segment, we need to discuss a major prerequisite for it: visibility. Microsegmentation does not live in a vacuum. You can’t protect what you can’t see. Good segmentation is only effective alongside network visibility that organizes and summarizes the traffic. There is usually too much traffic to realistically parse it all raw with the naked eye.
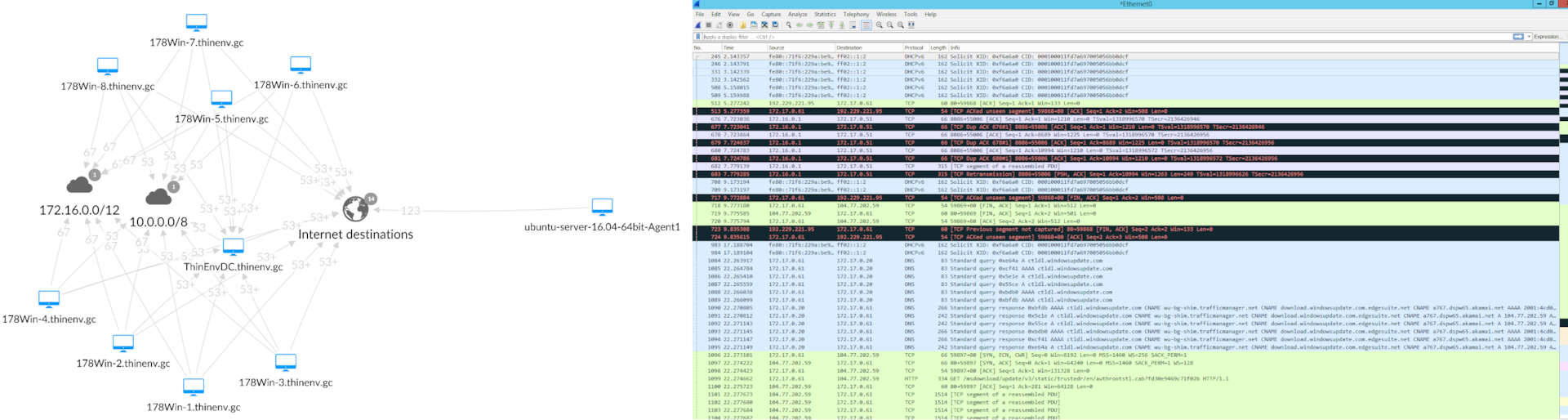 Fig. 1: Network visibility via a visibility tool vs. raw data via network sniffing
Fig. 1: Network visibility via a visibility tool vs. raw data via network sniffing
You can see in Figure 1 that there’s a lot of traffic going on inside that network (and there’s also a dummy network in the figure for illustration purposes). Creating policies that apply to each and every traffic strand that moves through the network is realistically impossible.
Instead, we can focus on small scale segmentation mini-projects that improve the security bit by bit (remember, it’s microsegmentation, not macrosegmentation). Although having an overarching goal is good, it’s probably better to focus on increasing security gradually, based on your network’s threat model.
What is threat modeling? It’s a way of defining the type of threats and cyberattacks you’re expecting to deal with, and defining priorities accordingly. For example, small and medium-sized businesses are unlikely to encounter state-sponsored threat actors, but banks on the other hand, might.
If you store a lot of sensitive information, your biggest threat might be data exfiltration. Smaller businesses may want to focus more on their perimeter, since they may not have a lot of machines inside the network to properly break into segments. If you’re scared of attackers running rampant in your network, consider starting with lateral movement segmentation. Do you have a business critical application that must not fall into the wrong hands? You can start by ringfencing it.
How to design a segmentation policy
Before jumping into actual segmentation strategies, we’d like to discuss some guidelines, or principles, that we believe are crucial for good segmentation.
The more accessible something is, the less output it should be allowed to send
Generally speaking, servers that have a lot of incoming traffic are more on the handling side of requests, like web or file servers (even domain controllers fall under this category). As such, there shouldn’t be that much outgoing traffic from them, or at least it should be strictly defined.
In addition, having minimal restrictions on both output and input runs the risk of the server being used as a pivot by attackers since the servers are more accessible for attackers and can be used to access a wider part of the network.
Use other defense mechanisms where your policy has to be loose
There are some machines for which policies have to be loose, as there’s too much variability in the traffic coming out of the machine; therefore, many exceptions have to be made.
Take, for example, jump box servers — different users use them to connect to different servers with different protocols. You won’t be able to cover all use cases without being too permissive (which defeats the whole purpose of segmentation).
In such cases, we believe that it’s best to employ other defense mechanisms instead, and make them stricter (like using stronger user access control for the jump box example, or lower alert thresholds for monitoring services).
Segmentation doesn’t exist in a vacuum
Just because some traffic strand already exists when you start segmenting doesn’t mean you should allow it. Sometimes you’ll have to modify existing configurations of applications or servers when you decide the traffic they produce is unnecessary. Sometimes, you’ll also have to consult existing configurations to understand why certain traffic exists in the first place.
Breaking the cyberattack kill chain
Roughly speaking, we can break down the cyberattack kill chain into three parts:
Network initial access
Lateral movement phase
Machine postbreach operations
The postbreach operations are the operations that attackers are usually performing on each machine in the network that they manage to breach, and those operations change according to the attack campaign. For example, cryptojacking campaigns will install and run cryptominers, while ransomware campaigns will exfiltrate sensitive data and then encrypt it.
We’ll discuss how segmentation can help in protecting against some parts of the kill chain
(Figure 2).
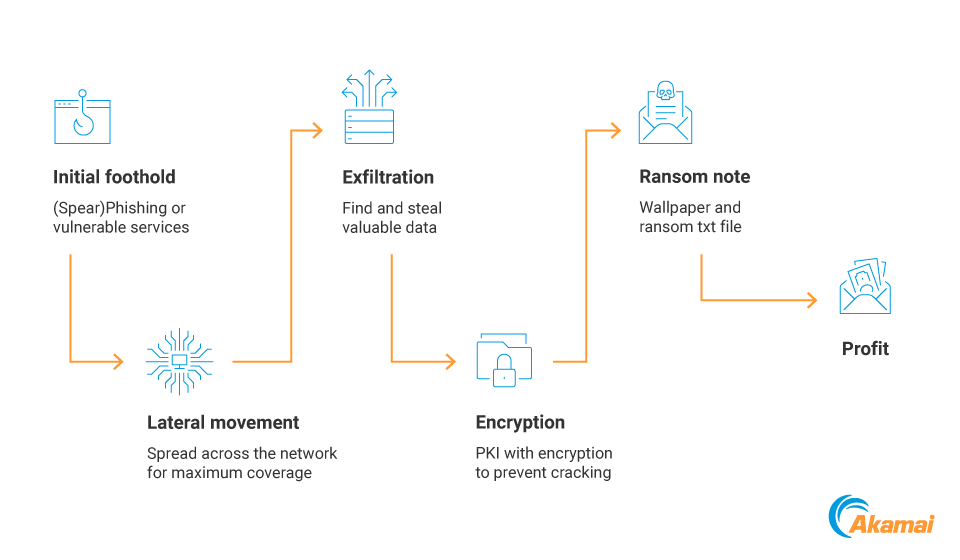 Fig. 2: The ransomware kill chain
Fig. 2: The ransomware kill chain
Initial access
In this case, segmentation is just like traditional firewalling: you block incoming traffic from outside your network that shouldn’t come in. This would usually be from the internet, but it can also be from third-party networks that are connected to your own.
So, blocking exposed Secure Shell (SSH) or remote desktop protocol (RDP) ports (or basically any port in the lateral movement section) is advised. In fact, it’s better to use an allowlist rather than denylist for traffic that originates from outside your network, especially from the internet (consider, for example, how many internet scanners are active at any given moment).

Of course, as with any other security tool, practice (or policy) segmentation is not a catch-all for threats. In this case, segmentation can’t cover all initial access vectors, and relying only on segmentation leaves your network exposed to risk. Many breaches begin with phishing emails or links or other forms of social engineering.
Some breaches also begin with vulnerabilities in protocols that should be allowed, or with weak credentials to services that are legitimately exposed to the internet, like the VPN server. Because of that, we recommend not relying just on segmentation to prevent initial access, and employ security solutions for host and email protection in addition to segmentation.
Lateral movement
There are many ways to execute lateral movement; we will not be covering all of them. Specifically, we’ll focus on preventing lateral movement that can happen through legitimate processes that already exist on the machine, using protocols like RDP or SSH, RPC-based services like the service manager or task scheduler, management tools like PowerShell or WMI, or some of the protocols and tools available in Linux that we discussed in a separate post.
We will not be discussing one-day or zero-day vulnerabilities because they can be in any product and with different implementations, so it’s impractical to have a general strategy that applies to them. The only thing we can recommend is segmentation, since something that is inaccessible is a lot harder to exploit.
Before we dive into different considerations for each of the different protocols, there are two principles that apply to all of them.

Users don’t really need to access other users’ machines, especially not over the network. Unless someone works in IT, there isn’t a lot of justification for them to connect to another user’s machine remotely. As such, it should be pretty feasible to restrict traffic among users’ machines without compromising network operability very much.
In addition, since the protocols discussed in this section can be used for remote control or execution, they can also serve as initial access vectors. That’s why we reiterate the need to restrict arbitrary internet access over these protocols.
Tool/Protocol |
Port(s) |
|---|---|
RDP |
3389 |
VNC |
5900+ |
X Window System |
6000+ |
TeamViewer |
5938, 80, 443 |
AnyDesk |
6568, 80, 443 |
SSH |
22 |
MS-RPC |
135, 49152+ |
SMB |
445, 139 |
WinRM |
5985, 5986 |
SNMP |
161 |
rexec |
512 |
rlogin |
513 |
rsh |
514 |
Fig. 3: Common tools/protocols (and their ports) that can be used for lateral movement
RDP, VNC, TeamViewer, and other remote desktop protocols
Since these services are interactive and graphical, their automated usage is pretty limited. Therefore, you can expect to not see those protocols used among servers very often (the keyword being “expect” — if you do see it, it’s time to investigate why).
The same reasoning applies among users’ machines — users shouldn’t need to connect to one another. Exceptions to these assumptions might be jump boxes and terminal servers that allow users to hop environments or access servers, IT personnel connections to user machines, or application owners connecting to the application server.
Handling such exceptions should be done by creating suitable policies using segmentation, but those efforts should be supplemented with proper identity access management (IAM) solutions as well.

Threat actors sometimes install third-party remote desktop servers as a backdoor and as a persistence method. If you detect remote desktop traffic or software that is new to the network, investigate it.
SSH
Although SSH is similar in concept to the RDPs, the story is more complicated. Since SSH is terminal (text)–based, it is a lot easier to use it to interact with software, and there are programs and scripts that use it. In addition to that, SSH is also used to encapsulate less-secure protocols, like SFTP, which is the SSH encapsulation of the file transfer protocol.
For those reasons, SSH requires a much more granular approach than other RDPs. Without proper visibility into network traffic, it will be very difficult to properly segment SSH without affecting the end users or network operability.

MS-RPC and SMB
Both MS-RPC and SMB don’t immediately allow for lateral movement — other protocols that are built on top of them do (see Figure 4). SMB is used for file transfer and communications, while RPC is used to call remote functions from defined interfaces. RPC is also sometimes carried over SMB, so they’re tightly coupled. They are also notoriously difficult to properly segment, as they are baked into the Windows domain system.
For example, domain authentication is implemented in Netlogon, an RPC-based protocol. Domain group policies and logon scripts are stored in a shared folder on the domain controller called SYSVOL, and domain-joined machines access it over SMB.
Blocking off SMB and RPC is practically impossible, without breaking the entire domain. So, what can you do? With SMB, you can create policies based on logic units — most servers and machines shouldn’t talk with one another over SMB, unless the destination is a file server. As such, proper ringfencing segmentation should help mitigate the risk of SMB.

A similar approach can be applied to RPC, but it can be even more restrictive, since we don’t need to allow RPC traffic to file servers, unlike in SMB. Also, since RPC is handled in user mode, it is possible to create segmentation policies based on the target service or process, so you only need to deal with RPC interfaces that can be abused for lateral movement (and only if you have a segmentation agent that can handle process- or service-based rules).
The following table shows RPC interfaces that should be managed to prevent lateral movement.
Technique |
Usage |
RPC interface |
Destination process |
Service |
|---|---|---|---|---|
Communicating with the service manager to execute remote binaries. Usually used after copying malicious binary remotely with SMB |
services. exe |
|||
Modifying the registry remotely to achieve persistence, run logon scripts or weaken security |
svchost.exe |
RemoteRegistry |
||
Creating scheduled tasks remotely for command execution |
Schedule |
|||
Another abstraction layer above RPC. Can be used to interact with various system components remotely, like WMI |
DcomLaunch |
Fig. 4: RPC interfaces that can be used for lateral movement
Since not all operations over those RPC interfaces are malicious (for example, some monitoring solutions and watchdogs interact with the service manager remotely to check for service health), we recommend surveying existing RPC communications. If they aren’t normally accessed remotely (or if you can narrow down the source list), we recommend you create segmentation policies around them for the extra security benefit.

PowerShell, WMI, WinRM
Both PowerShell and WMI are capable of interacting with remote machines, and that interaction is “powered” by Windows Remote Management (WinRM). Since the legitimate usage is usually remote management or monitoring (with WMI), there should be few use cases in your network. It should be possible to create segmentation policies that restrict arbitrary usage and allow it only from monitoring servers or IT machines.
Of course, outliers are possible and we’ve seen a few cases where remote PowerShell was used extensively by developers for convenience; it would probably require a case-by-case decision.

SNMP
Simple Network Management Protocol (SNMP) is a popular monitoring solution, especially for Linux machines. SNMP also has an EXTEND plug-in, that could be abused for remote script execution, as we’ve mentioned in our post about Linux lateral movement (and implemented in Infection Monkey). Although the EXTEND plug-in is no longer enabled by default for remote commands in newer releases of the SNMP agent, it is still possible to compile an SNMP agent with the plug-in enabled. We’ve also seen machines running an unpatched version that has the EXTEND plug-in enabled.
Since SNMP is used for monitoring, we recommend allowing SNMP traffic to originate only from monitoring servers, and restricting it from the rest of the network. We also recommend giving additional attention to EDR alerts originating from the monitoring servers to prevent them from being used as a proxy to the rest of the network by attackers.
When there are multiple monitoring servers used by different products, separation by segmentation of different logical units should also be considered (for example, if you have a monitoring solution for your finance servers, and only for them, don’t allow it to access your web servers).
Telnet and the Berkeley r-commands
Telent and the Berkeley r-command are much less common, and have largely been replaced by SSH. We covered them in our Linux lateral movement post. But just because they’re rare does not mean we should ignore their existence. After all, attackers don’t care about commonality, they’ll use whatever means they have available.
We recommend replacing these protocols with more secure protocols, like SSH, or at the very least encapsulating their traffic in a secure channel. Where it isn’t possible, the same security practices around SSH apply.
Exfiltration
Unless you want to control all outgoing traffic 1984-style, you can’t realistically expect to prevent data exfiltration during attacks using only segmentation. The internet is large and wide, it is not realistic to have an accurate verdict for every site and server that users are connecting to from your network. As such, threat actors can easily camouflage their exfiltration attempts among all the other outbound traffic.
Instead of trying to control the outbound traffic, it is more feasible to control who can access sensitive data. The only place where it might be possible to restrict outbound traffic is on servers in the network; unlike user machines, there should be much less variability in their outbound destinations.

General segmentation workflow
The overarching principle for this entire section is “Just because it exists, does not mean it should be allowed.” When segmenting a part of the network, whether it’s a business-critical application (like SWIFT), an operational unit (like the domain controller), or an environment (like production servers), the first order of business is to survey the existing traffic (Figure 5).
After analyzing the existing traffic, you can create policies that allow the relevant flows and restrict the rest (this is also your opportunity to find any misconfigurations that should be handled by the application owner instead of segmentation).
We recommend not implementing a blocking policy immediately, but running in an alerts-only mode for some time. You should move to a restricting policy only after you deem that the policy is running as intended and that the policy violation alerts are at a minimum or controlled amount.
It is also important to differentiate your current environment (the one that existed before you started segmenting it) and your future environment (the one after you’ve implemented your segmentation policy). When first implementing segmentation, you should use caution and learn the network to avoid breaking things.
Newer additions, however, should be added while considering the existing segmentation policy. Make policy exceptions and allowances where needed for normal operativity, but don’t disregard the existing policy just because you’re expanding the network.
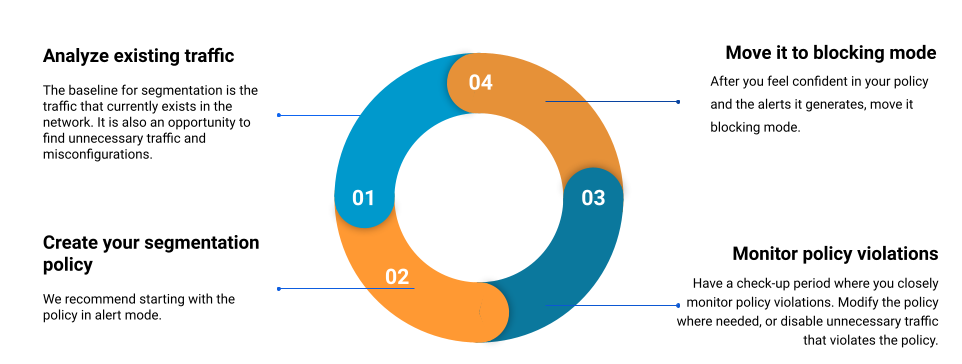 Fig. 5: The general segmentation workflow
Fig. 5: The general segmentation workflow
Ringfencing
With ringfencing, we’re mostly interested in the interfaces of the segment with the rest of the network and with the world. We want to control what comes in and goes out of the part of the network we want to segment without considering what is going on inside the segment.

Application ringfencing
We can take ringfencing one step further, and apply policies to individual machines based on their purpose. So,for example, if a server functions only as a database, it should only be given access over the database ports; a web server, over web ports.
Of course, it’s not that simple. There are usually more services that need access to those servers, such as watchdogs, performance monitors, or IT. Usually, those access ports also look very similar to lateral movement techniques, since they usually revolve around some sort of remote control. (For example, remote watchdogs query the service manager, in a similar way to the PsExec lateral movement technique. The only way to distinguish between the calls is deep packet inspection, which is usually not available.)
To overcome this challenge, wherever you need to allow additional traffic besides what should already access the service, we recommend you limit the allowed sources to the segment that should do the monitoring.
In addition, we can limit user access to sensitive locations that they don’t need. If the database only serves internal applications, there’s little reason to let arbitrary users query it. Blocking arbitrary user access is the most crucial security step in our opinion, since many attacks begin from compromised users.

Microsegmentation
With microsegmentation, we’re applying another layer of granularity to our segmentation policy — we separate the machines in the segment based on their role or sensitivity. We can think of it as a hybrid between application ringfencing and general ringfencing. The major difference from ringfencing is that we now also control traffic inside the segment, and don’t automatically trust neighbors.
Our principle here is that we shouldn’t trust traffic from neighboring machines just because we’re inside the same segment. Attackers will use whatever connection they can to propagate throughout the network, regardless of segments.
So, even if we have the same kind of application server in the segment, there’s no reason for them to be able to communicate with one another on every port and protocol. Microsegmentation means we apply policy rules on all kinds of traffic, even inside the network segment and among machines with the same role.
Of course, machines inside the same segment are usually more tightly coupled, so it’s more difficult to add policies without being overly permissive.

Depending on how you define the segments in your network, the principles for application ringfencing can often also apply as microsegmentation principles. For example, if we split our network into a user segment, database segment, and web server segment, then the principles defined in application ringfencing are also suitable for microsegmentation. The only addition required is the application of the same principles inside each application segment, among different machines.
However, if our network is split into a finance segment, sales segment, and IT segment, and each segment has a mix of servers and user machines, then we need to be more creative. After applying the general ringfencing strategies to the segments, we must then turn to creating policies among the segments and inside them. We can consider each segment a mini-network; then we can split each one into the different applications and machine types that contrive it. (For example, for a sales segment, we might have a fileserver, database, and user machines.) We can treat each kind of machine as a new segment, and follow the ringfencing or application ringfencing guidelines again.
Figure 6 summarizes the relations among the various segmentation strategies.
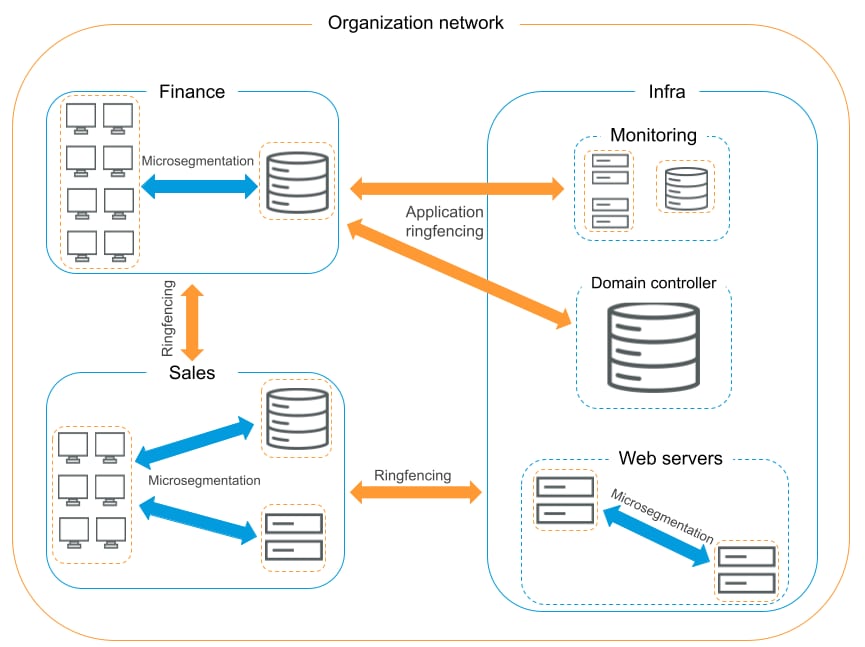 Fig. 6: Segmentation strategies in an organizational network
Fig. 6: Segmentation strategies in an organizational network
Other defense layers’ synergies with segmentation
Although proper network segmentation greatly raises the hurdle necessary for threat actors to clear to breach the network, it still shouldn’t be the only defense layer in your arsenal. You need a defense that includes detection, response, and simulation.
Detection
A dedicated and talented enough attacker will probably be able to get anywhere they want, as no system or network is 100% foolproof, and zero-day vulnerabilities always exist. It’s not necessarily a realistic scenario (since zero-day vulnerability development is costly and can’t be done on a whim), but we believe that it’s better to prepare for the worst than to plant your head in the sand.
With this approach, we believe that segmentation comes hand-in-hand with detection. Even if the attackers manage to find footholds in the network and move laterally, you have tools in place to detect them and resolve the threat. It could be EDRs for host threat detection, web access monitoring tools, or regular threat hunting activities. The important things are that suspicious activity is detected and alerted, and that you have a team in place to investigate those alerts.
In addition to detection, there are three added benefits that a segmented network provides over a flat network (Figure 7).
It raises the skill level required to breach the network and can deter less-skilled threat actors. Zero-day vulnerabilities aren’t available to most attackers, so given the threat model of your network, a good network segmentation policy might serve as a good enough deterrent against most attackers.
The more hops threat actors have to take in the network, the more chances are that they’ll be detected because of the increased time and steps it takes to complete a full intrusion.
It might also be possible to direct attackers to “choke points” where they’re more easily identifiable. This can be done through honeypots, canaries, or even just extra vigilance.
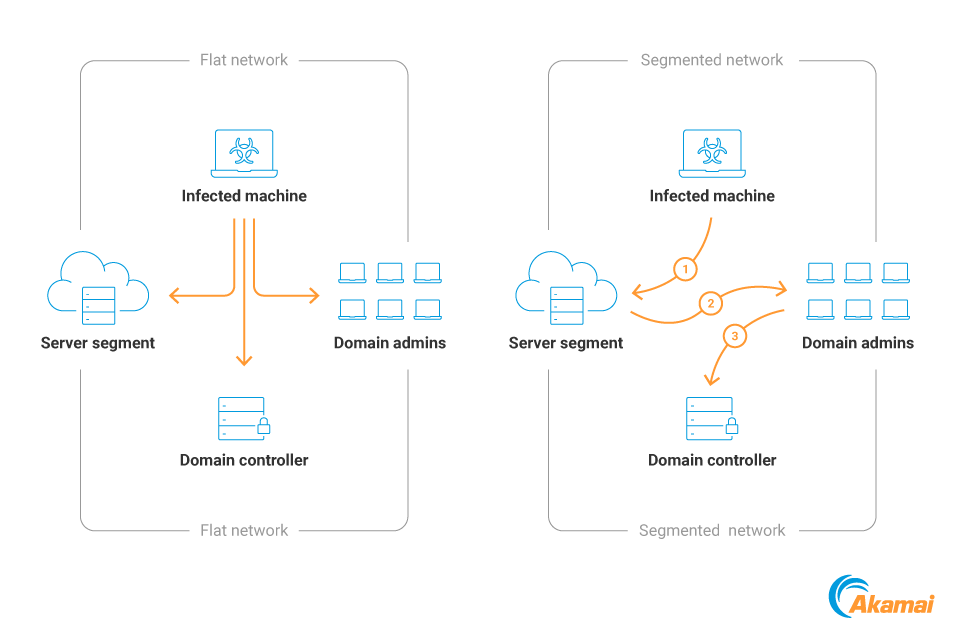 Fig. 7: Flat vs. segmented network intrusion. In the flat network, every part of it is reachable simultaneously and intruders can reach their goal quickly. In a segmented network, attackers have to act procedurally.
Fig. 7: Flat vs. segmented network intrusion. In the flat network, every part of it is reachable simultaneously and intruders can reach their goal quickly. In a segmented network, attackers have to act procedurally.
Response
Simply detecting threats is not enough, you must also respond quickly to alerts and breaches. According to reports about ransomware attacks, breach to encryption only takes a few days. That means you also have only a few days to detect them and drive them out of the network. Granted, as we said earlier, a proper segmentation will slow down the attack, but attacks still need prompt reaction.
Segmentation synergizes with response in two ways.
It gives you more time to respond because attacks will now take longer to complete and have more places of friction to generate alerts (where attacker traffic clashes with your segmentation policy).
It can be used to respond. In the same way that you create segmentation policies and rules to restrict and control access to different parts of the network, you can create rules to quarantine assets — so attacks can’t proceed further. Incorporating segmentation in your incident response plans and workflow, and having tools to deploy quarantine rules quickly in case of an emergency, can be pivotal in dealing with network breaches.
Simulation
On paper, you may have created the best segmented and secure network possible, and you can detect any attack coming your way. But no plan survives first contact with the enemy; it is best to have that enemy not be a malicious threat actor.
That’s where simulation comes in. A red team can simulate an enemy by trying to hack your systems like a threat actor would, or a network breach automated simulation tool (like Akamai’s open source tool, Infection Monkey) could do that instead.
Simulations can uncover weak spots in your defense that malicious threat actors could exploit. Routinely checking up, and then acting on the results, can greatly increase your network’s security.
Summary
Network segmentation is a useful tool to increase network security and deal with network-based threats. It is also a tool that can provide immediate security value, as you don’t have to start with long or arduous segmentation projects, and can instead split your work into multiple subprojects, each one improving the network’s security posture one step at a time.
We’ve provided guidelines to various segmentation policies and strategies to help network admins do just that. We hope that our recommendations are practical and will help keep organizations more secure.
The Akamai Akamai Security Intelligence Group will continue to monitor, study, and publish research on a multitude of security topics. For real-time updates and breaking research, follow us on Twitter!
