

A/B Testing, Now with EdgeKV


This blog was co-authored by Tim Vereecke, Josh Johnson, and Medhat Yakan
This is a blog series about building an A/B test with EdgeWorkers and EdgeKV. Read part one here.
In our previous blog, we wrote the base code for our A/B test and stored the data locally. Although this may be convenient for testing purposes, it's suboptimal for several reasons:
- Editing source code just to change data values (e.g., URL updates) introduces the risk of inadvertent changes and bugs
- It's also less convenient since a new EW bundle needs to be generated, uploaded, and activated
- Getting code to work correctly is easier when separated from data values
- Commingling data and code in a single entity may limit future scalability
Now that we've written the framework of our code, let's layer in EdgeKV (EKV), our distributed key-value store database. Before getting started, we recommend downloading and installing the EdgeKV command-line interface (CLI) to use for these examples. You may also want to review the documentation of the EKV data model to better understand it. The uppermost element of our data model is the namespace, which contains groups; groups contain individual name-value pairs called items.
To gain access to an EdgeKV database from an EdgeWorker requires the use of an access token, which contains assertions (claims) including:
- EdgeWorker ID allowed to access the namespace
- Expiration date
- Valid environment (staging or production)
- Namespace permissions (read, write, and delete)
This token must be included in your EdgeWorker code bundle and can easily be created using a CLI command. More information can be found here.
Now that we have the framework of our code written, we need to craft the redirect path that will be used to route the client request in the onClientResponse stage. We'll replace the static implementation of getBucketABPath() from the previous post with an implementation that uses EdgeKV instead. First, we need to import a (local) reference to the EdgeKV helper library in our main.js file, which will also be part of our EdgeWorker code bundle.
import {EdgeKV} from './edgekv.js';
Next, we instantiate an EKV object (edgeKv_abpath) using a single line of code. The helper library makes it simple and easy. We instantiate the object, passing in the namespace and group from where we want to retrieve our data. We'll populate the database shortly with the proper path data for each bucket_id.
We set a constant to define the URL of the default experience to use if no experiences are defined for the client yet.
const default_path = "ekv_experience/default";
const edgeKv_abpath = new EdgeKV({namespace: "default", group: "abpath"});
async function getBucketABPath(bucket_id) {
// If we do not have a valid bucket, we will default to the following
if (!bucket_id) {
return default_path;
}
let path = null;
let err_msg = "";
// Retrieve the path associated with the bucket from EdgeKV
try {
path = await edgeKv_abpath.getText({ item: bucket_id.toUpperCase(),
default_value: default_path });
} catch (error) {
// Catch the error and log the error message
err_msg = error.toString();
logger.log("ERROR: " +
encodeURI(err_msg).replace(/(%20|%0A|%7B|%22|%7D)/g, " "));
path = null;
}
if (!path) {
path = default_path;
}
return path;
}
Now that we have instantiated the object, we create a function call that will get the A/B path based on the bucket_id key found in the cookie value. We return the default path value if the bucket_id is not already set, otherwise we retrieve the URL relative path from the KV database.
We make an async request using the edgeKv_abpath object and EdgeKV getText() method to obtain an item from the EdgeKV. This function does exactly what it sounds like: returns an item (key-value pair) in plain text. The key will be the bucket (A or B) and the value will be a URI stem, both of which we'll create shortly. We use a try-catch block to handle any exceptions thrown by the EdgeKV method, raising errors into the JavaScript console via the logger library.
If we don't have the path value stored in EdgeKV, we revert to the defined default_path; otherwise we return the correct path from the item in EdgeKV.
Populate EdgeKV with data
Okay, now that we have the code to run the A/B test, we need to populate the EdgeKV database with the data needed by the EdgeWorker. To get data into EdgeKV, you can use the administrative API or download our CLI if you don't want to write against our APIs. For this blog, we'll assume usage of the CLI.
We first need to initialize the database itself, which is a one-time operation.
$ akamai edgekv initialize
---------------------------------------
--- EdgeKV INITIALIZED successfully ---
---------------------------------------
┌─────────┬───────────────┬──────────────────┬───────────────┬───────────┐
│ (index) │ AccountStatus │ ProductionStatus │ StagingStatus │ Cpcode │
├─────────┼───────────────┼──────────────────┼───────────────┼───────────┤
│ 0 │ 'INITIALIZED' │ 'INITIALIZED' │ 'INITIALIZED' │ '123456' │
└─────────┴───────────────┴──────────────────┴───────────────┴───────────┘
After initialization, we'll have a namespace called "default" automatically created for us in both staging and production environments. We'll use the production environment to store our data.
Now we need to populate our desired namespace with the path values corresponding to bucket A and bucket B. Here, we write text into the KV database in production with a namespace of "default" and a group name of abpath. In this example, the item (key) we're writing is called "A" and the value is ekv_experience/experiment-A.
$ akamai edgekv write text production default abpath A "ekv_experience/experiment-A"
----------------------------------------------------------------------------------------------------------------
--- Item A was successfully created into the environment: production, namespace: default and groupid: abpath ---
----------------------------------------------------------------------------------------------------------------
Now we wait up to 10 seconds for the inconsistency window to elapse (the time it takes to update all global database nodes). Once it elapses, we can be confident that the data is consistent everywhere in the world and available to all EdgeWorkers. Let's repeat this process to write item "B" into the abpath group with a value of ekv_experience/experiment-B.
$ akamai edgekv write text production default abpath B "ekv_experience/experiment-B"
----------------------------------------------------------------------------------------------------------------
--- Item B was successfully created into the environment: production, namespace: default and groupid: abpath ---
----------------------------------------------------------------------------------------------------------------
Again, we wait 10 seconds. Now, let's read back the keys we created to ensure they're in the database. First, bucket A.
$ akamai edgekv read item production default abpath A
------------------------------------------------------------------------------------------------------
--- Item A from group abpath, namespace default and environment production retrieved successfully. ---
------------------------------------------------------------------------------------------------------
Then, check bucket B.
$ akamai edgekv read item production default abpath B
------------------------------------------------------------------------------------------------------
--- Item B from group abpath, namespace default and environment production retrieved successfully. ---
------------------------------------------------------------------------------------------------------
ekv_experience/experiment-B
Testing our A/B logic
That's it! We've created our code and populated our database with the containers (keys) that will hold our redirect values. We can now perform an A/B test with two different paths. The best way to see it in action is to browse to the URI of the website and review the cookie values.
For the sake of clarity, we're also printing Experiment A or Experiment B to the screen in red and blue, respectively. When we first visit the website, the bucket cookie value isn't set, and we get routed to a randomly assigned experience. In the case shown below, we're routed to bucket B.
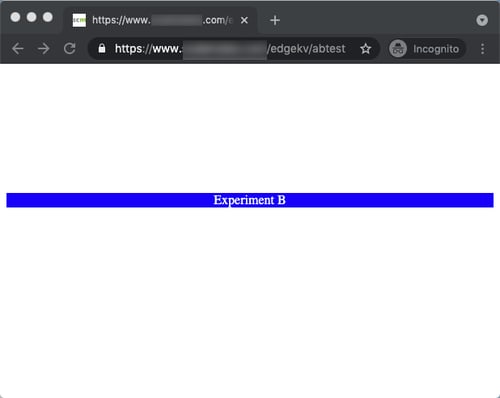
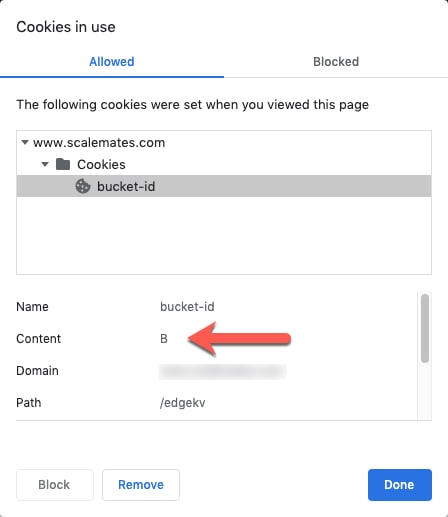
We can cross-verify this by checking the cookie values. Here, we see that the EdgeWorker operating on the /edgekv/abtest path has set the bucket-id value of the cookie to bucket B.
Now we clear the cookies for this website by selecting on the www parent entry and clicking the Remove and Done buttons. This will clear all the cookies from the browser, like this:
Now that the browser is no longer storing cookies, we refresh the page. If we get lucky with randomness, we get sent to the experiment A version of the page, as denoted by the red bar. If you don't receive the red page, clear the cookies and refresh the page again. You may need to clear the cookies multiple times to receive the experiment A version of the page.
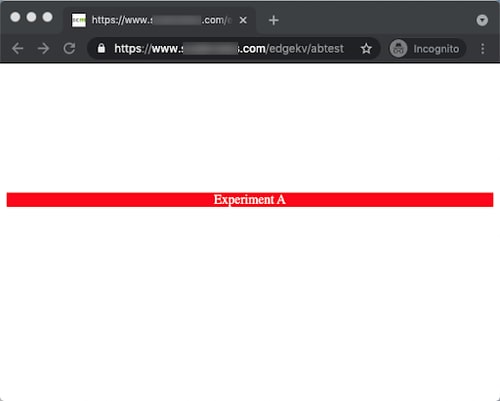
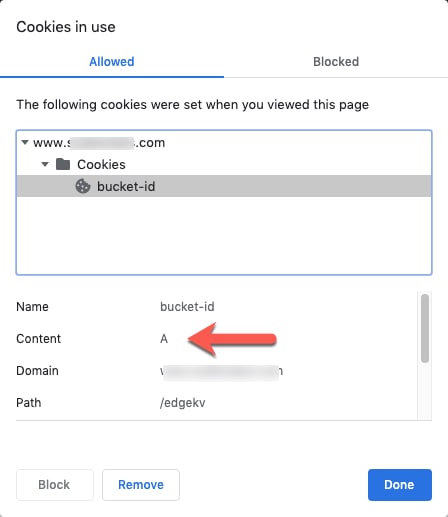
Note that we now get a bucket-id cookie value of A instead of B, validating that we're indeed on the second experience. If we refresh the page without clearing cookies, we will be pinned to bucket A, as we set the lifetime of the cookie to seven days inside the EdgeWorker code. This locks the user into one experience for the lifetime of the test.
Summary
This is a bare-bones example of what you could do with EdgeWorkers and EdgeKV when used in tandem. To improve this example, we might stop using randomness to determine the page to send and instead sniff the geographic location of the client to set the page. This would add more specificity to the decision.
To run the demo, you'll need both EdgeWorkers and EdgeKV provisioned at Akamai. If you're an existing Akamai customer, you can add both products to your contract via the Marketplace app store in the Akamai Control Center.


