

hAFL1 – Our Journey of Fuzzing Hyper-V and Discovering a Critical 0-Day




Executive summary
- Guardicore Labs, in collaboration with SafeBreach Labs, found a critical vulnerability in Hyper-V’s virtual network switch driver (vmswitch.sys).
- The vulnerability was found using an in-house built fuzzer we named hAFL1 and which we open-source today. The repository includes detailed, step-by-step instructions on how to deploy and run the fuzzer on a Linux server.
- hAFL1 is a modified version of kAFL which enables fuzzing Hyper-V paravirtualized devices and adds structure awareness, detailed crash monitoring and coverage guidance.
- The RCE vulnerability we found (CVE-2021-28476) was assigned a CVSS score of 9.9 and is detailed in a separate blog post.
Motivation
Why Hyper-V? A growing number of companies are moving major parts of their workloads to public clouds, such as AWS, GCP and Azure. Public clouds give their users flexibility and free them from having to manage their own bare-metal servers. However, these clouds are inherently based on a shared infrastructure – shared storage, networking and CPU power. This means that any security flaw in the hypervisor has a much broader impact; it affects not only one virtual machine, but potentially many of them.
Hyper-V is Azure’s underlying virtualization technology, and we decided to target its virtual switch (vmswitch.sys) as it is a central, critical component of the cloud’s functionality.
Why fuzzing? Between developing a fuzzer and statically analyzing Hyper-V’s huge networking driver vmswitch.sys, we chose the first for one simple reason – scale. Searching manually for vulnerabilities can be tedious, and we were hoping that a good fuzzer would be able to find more than a single bug.
Our target: vmswitch - a paravirtualized device
In Hyper-V terminology, the host operating system runs in the Root Partition and any guest operating system runs inside a Child Partition. To provide child partitions with interfaces to hardware devices, Hyper-V makes extensive use of paravirtualized devices. With paravirtualization, both the VM and the host use modified hardware interfaces, resulting in much better performance. One such paravirtualized device is the networking switch, which was our research target.
Each paravirtualized device in Hyper-V consists of two components:
- A virtualized service consumer (VSC) which runs in the child partition. netvsc.sys is the networking VSC.
- A virtualized device provider (VSP) which runs in the root partition. vmswitch.sys is the networking VSP.
The two components talk to each other over VMBus – an intra-partition communication protocol based on hypercalls. VMBus uses two ring buffers – a send-buffer and a receive-buffer to transmit data between the guest and the host.
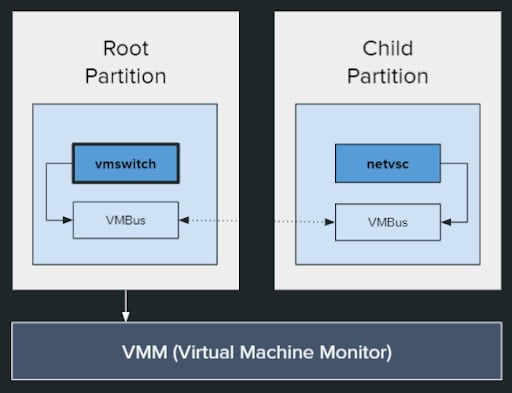 Paravirtualized networking in Hyper-V consists of netvsc (the consumer) and vmswitch (the provider).
Paravirtualized networking in Hyper-V consists of netvsc (the consumer) and vmswitch (the provider).

General plan
Our goal was to have a fuzzing infrastructure capable of sending inputs to vmswitch. In addition, we wanted our fuzzer to be coverage-guided and provide detailed crash reports that indicate exactly why a crash occurred. Last, it was important for us to integrate structure awareness, to send inputs in the format vmswitch usually accepts and not waste time and resources on arbitrary inputs.
Harness: finding our way in
The first phase in developing our fuzzer was designing the harness. We drew inspiration from an MSRC blog post that detailed the fuzzing of VPCI – Hyper-V’s paravirtualized PCI bus. As this goal was similar to ours, we started following the same steps.
The idea presented in Microsoft’s post is simple – find the VMBus channel used by the VSC and use this channel to send data to the VSP using known, documented APIs. We set out to apply these steps to our target: find the VMBus channel used by netvsc and use this channel to send data to vmswitch using VmbPacketAllocate and VmbPacketSend.
Finding the VMBus channel
netvsc is an NDIS driver that runs in the guest operating system of a Hyper-V child partition, and exposes a virtualized network adapter. As part of the initialization process of the virtual adapter, netvsc allocates a structure called MiniportAdapterContext (this happens as part of the function NvscMicroportInit). At offset 0x18 of the MiniportAdapterContext is our VMBus channel pointer.
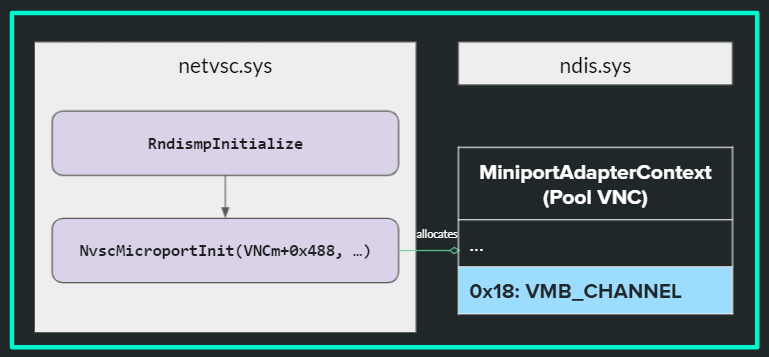 The VMBus channel pointer is written to the MiniportAdapterContext structure as part of the initialization process in netvsc.
The VMBus channel pointer is written to the MiniportAdapterContext structure as part of the initialization process in netvsc.
With this new knowledge, we wrote a dedicated driver (harness.sys) which runs on the child partition. It iterates through all NDIS miniport adapters, finds the adapter we want to fuzz with (by doing string-matching on its name) and fetches the VMBus channel pointer from the adapter context structure. With the VMBus channel used by netvsc at hand, the driver allows us to send data freely to vmswitch.
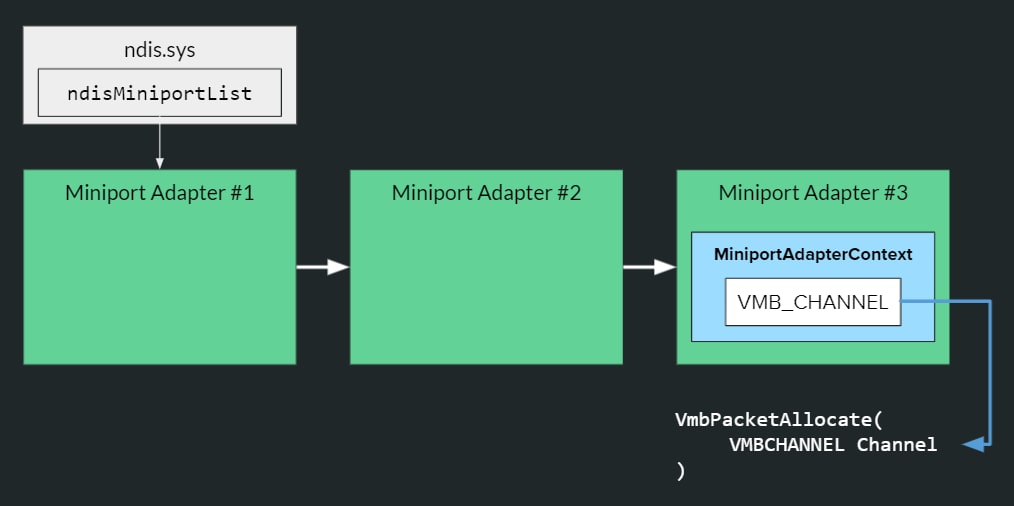 The process of finding the VMBus channel through the ndis.sys driver
The process of finding the VMBus channel through the ndis.sys driver
The vmswitch side
Every VSP in Hyper-V has to implement and register a packet-processing callback EvtVmbChannelProcessPacket. This function is invoked whenever a new packet reaches the VSP. In vmswitch, this callback function is VmsVmNicPvtKmclProcessPacket.
vmswitch expects packets of type NVSP – a proprietary format for packets transmitted over Hyper-V’s VMBus. There are many NVSP packet types; some are responsible for setting VMBus’s send and receive buffers, others perform the handshake between the VSP and the VSC (e.g. exchanging NDIS and NVSP versions), and some are used to send RNDIS messages between the guest and the host.
We decided to focus our fuzzing efforts on the code-flow that processes RNDIS messages for two reasons:
- There is a lot of code handling RNDIS messages.
- Quite a few of the vulnerabilities found in vmswitch were in the area of RNDIS packet-processing (1 2 3).
The function which handles RNDIS messages is VmsVmNicPvtVersion1HandleRndisSendMessage,
and it is directly called from VmsVmNicPvtKmclProcessPacket.
To fuzz vmswitch with RNDIS messages, our harness will have to invoke one of these functions and pass it RNDIS messages.
Sending RNDIS messages

VmsVmNicPvtKmclProcessPacket takes five parameters: the VMBus channel pointer, a packet object, a buffer and its length, and flags. The buffer parameter is used to send the packet metadata over to vmswitch. It consists of 4 fields:
- msg_type – the NVSP message type
- channel_type – 0 for data, 1 for control
- send_buf_section_index – The index of the send-buffer section where the data is written. Recall that VMBus transmits data over two ring buffers; this field specifies the exact location of the data
- send_buf_section_size – The size of the data in the send-buffer
 The different fields in the Buffer parameter of the packet-processing callback
The different fields in the Buffer parameter of the packet-processing callback
At first, it seemed mandatory to send data through the VMBus send-buffer. But after more research, we found another way to send RNDIS messages which does not involve the VMBus send-buffer. One can allocate memory, copy the data into it and then create a Memory Descriptor List (or an MDL) that points to the allocated buffer. We found this way more convenient for us, as it freed us from the need to copy our RNDIS messages to the send-buffer.
To send RNDIS messages using MDLs, the buffer from above specifies the following values:
- msg_type = NVSP_MSG1_TYPE_SEND_RNDIS_PKT
- channel_type = 1
- send_buf_section_index = -1 (to indicate the use of an MDL)
- send_buf_section_size = 0 (this parameter is ignored when using an MDL)
The MDL itself is attached to the packet object.
Testing our harness
At this point, we were not only able to send arbitrary inputs to vmswitch. We knew exactly which packets to send and how to send them so that the RNDIS code-flows were executed. With this capability we managed to trigger with our harness a past vulnerability in vmswitch – CVE-2019-0717.
Connecting the harness to a fuzzing infrastructure
The next step in the process was to integrate our harness into a fuzzing infrastructure, to save us the need to implement such an infrastructure ourselves – write hypercalls, design a mutation engine, decode coverage traces, etc. Several options were available, but we chose kAFL as it seemed most suitable for our needs – fuzzing a kernel-mode driver.
We had a clear mental image of our fuzzer, with three levels of virtualization (denoting level N with “LN”). L0 – the bare metal server – will run kAFL on Linux’s built-in hypervisor, KVM. We will then create our Hyper-V host (L1) – a VM running Windows 10 with Hyper-V enabled. On top of our Hyper-V host, two machines (L2) will run: the root partition, where vmswitch will execute, and a child partition, from which we will run our harness and fuzz vmswitch.
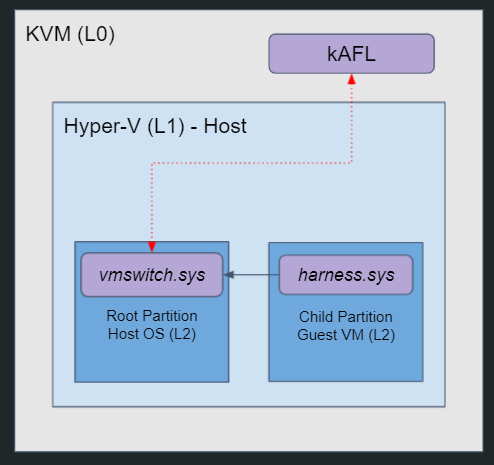 hAFL1 setup - take #1: vmswitch runs inside the root partition (L2) and our harness runs inside a child partition (L2 as well).
hAFL1 setup - take #1: vmswitch runs inside the root partition (L2) and our harness runs inside a child partition (L2 as well).
The problem was that kAFL does not support nested virtualization, while our setup is based on nested virtualization – we have a guest OS on top of a Hyper-V host on top of KVM. With such a setup kAFL cannot directly communicate with components that run in L2. More precisely, this implies lack of coverage information from vmswitch, and inability to send fuzzing payloads (inputs) from kAFL to our harness.
So for kAFL to fit, we had to rethink the setup. We thought, if we can’t fuzz from an L2 – we should fuzz from L1. In practice, this meant we had to find a way to run vmswitch from within L1 and not from within the root partition. Then, we would simply run our harness from the same virtualization level as vmswitch.
Lucky for us, we found a neat workaround that allowed us to do just that. As it turned out, when the Hyper-V feature is enabled and Intel VTx is disabled – Windows boots in a fallback mode where Hyper-V is not operational, but vmswitch is still loaded into kernel memory! However, no root (or child) partition exists, because Hyper-V does not operate, so we are left with only L1. This was exactly what we wanted; we could now run our harness on the (single) Windows VM and invoke our target function –VmsVmNicPvtVersion1HandleRndisSendMessage.
The next pitfall we experienced was the lack of a VMBus channel. When fully operational, vmswitch uses a VMBus channel to communicate with its consumers – the netvsc instances. But with an inactive Hyper-V, and no running VMs, our vmswitch has no such VMBus channel to use. We needed to find a way to provide vmswitch a VMBus channel, or make it initialize one itself.
After more reverse engineering, we discovered a special function in vmswitch called VmsVmNicMorph that does exactly that – it initializes a new VMBus channel for vmswitch. However, simply calling this function led to a blue screen, as it was trying to invoke VMBus-related functionality, and VMBus was not operating. We decided to patch out all VMBus logic. This made sense, as VMBus is an independent communication layer which does not interfere with the data being sent. You can think of it like the OSI network layer model: VMBus is the transport layer, and is independent from vmswitch, the application layer. Namely, we could give up executing VMBus logic and still receive a proper VMBus channel object for vmswitch to use.
There was still one more problem to solve. Changes to signed kernel-mode code are prevented by a Windows feature named PatchGuard. So if we wanted to modify instructions in vmswitch, we had to disable PatchGuard. To do that, we used an open-source tool called EfiGuard, which gave us 2-in-1: it disabled kernel-patch protection as well as driver signature enforcement, allowing us to run our unsigned harness driver on the machine.
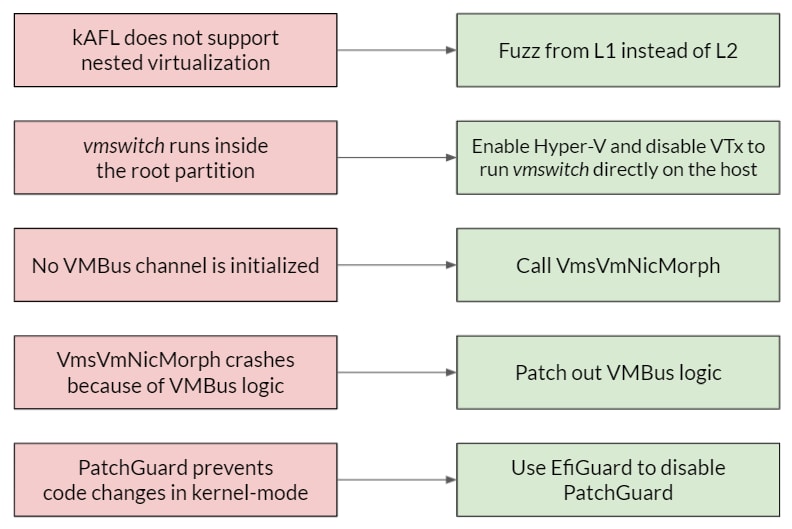 Summary of our pitfalls and solutions in the process of building hAFL1
Summary of our pitfalls and solutions in the process of building hAFL1
The resulting setup looked quite different from what we initially had in mind. vmswitch runs directly on the Windows 10 host (and not inside the root partition), and our harness driver (harness.sys) runs at the same level and not within a child partition. A user-mode harness process receives fuzzing payloads from kAFL over hypercalls, and passes them onto our harness driver using IOCTLs. Recall – Hyper-V is somewhat broken, as VT-x is disabled. And yet, it worked – we managed to run our harness, send fuzzing inputs to vmswitch and get coverage information to drive the fuzzing process forward.
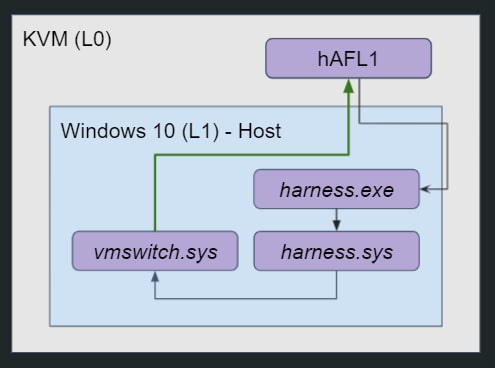 hAFL1 setup - take #2: vmswitch runs inside L1 and so does our harness.
hAFL1 setup - take #2: vmswitch runs inside L1 and so does our harness.
Fuzzing improvements
It was now time to incorporate some more logic and capabilities into our fuzzing infrastructure.
Coverage guidance
kAFL comes with coverage guidance out of the box. It leverages Intel-PT to trace the instruction pointer’s value throughout fuzzing iterations, and mutates inputs to increase the number of basic blocks it hits. To trace execution from only a certain process’s context (in our case – the harness), kAFL uses CR3 filtering – it records execution trace only if the CR3 register value matches the CR3 filter value.
To our unpleasant surprise, the reported number of visited basic blocks was too low to make sense. We knew that even a single packet should propagate through more basic blocks than what was shown by the fuzzer UI.
A short investigation revealed that vmswitch processes packets in an asynchronous, multithreaded manner. Packets first go through short, synchronous processing, and are then pushed into a queue as Work Items, waiting to be processed by a dedicated system worker thread. This thread, obviously, has a different CR3 value than that of our harness. This is why the fuzzer simply did not trace execution when it originated from a worker thread. To overcome this, we disabled CR3 filtering. We knew this wouldn’t contaminate our tracing results, as we were the only ones triggering code in vmswitch (recall – no guest VM exists in our setup!).
Last, to help us monitor our coverage of vmswitch and make sure we were on track, we wrote a Python script to convert Intel-PT data from kAFL format to that of IDA’s Lighthouse plugin.
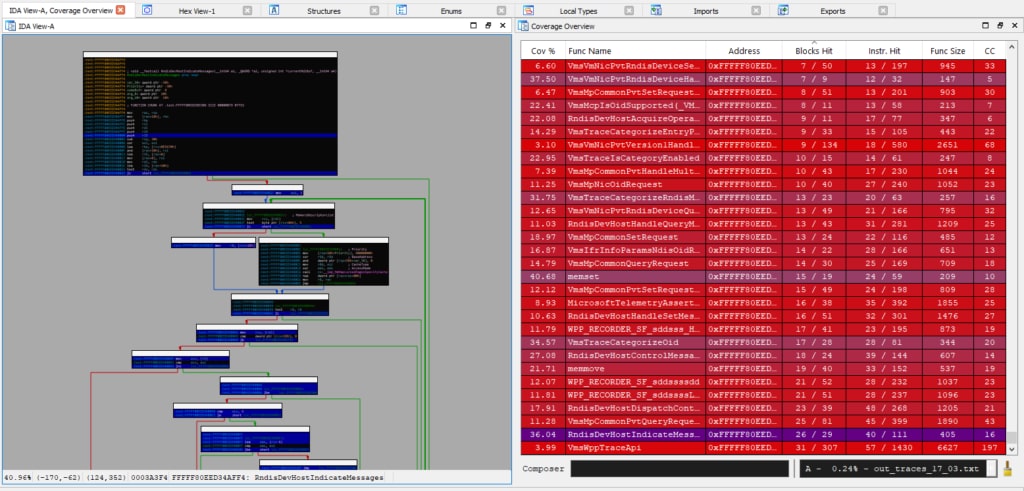 vmswitch coverage is visualized with IDA's Lighthouse plugin
vmswitch coverage is visualized with IDA's Lighthouse plugin
Crash monitoring
To be able to efficiently investigate crashes, it is necessary that the fuzzer produces detailed crash reports. However, kAFL does not provide much information for crashes in Windows targets. For example, it does not output the stack trace or the exact offset in the target’s code which triggered the crash. We needed to implement this logic ourselves.
We used a part of Xen’s codebase to fetch the stack trace and module information. Then, we wrote two KVM hypercalls which send this information from L1 back to kAFL. Finally, we implemented and registered a special BugCheck callback that invokes these KVM hypercalls.
With this, we were able to obtain detailed information regarding each crash that took place in vmswitch – a full stack trace with function names and offsets, as seen in the screenshot below.
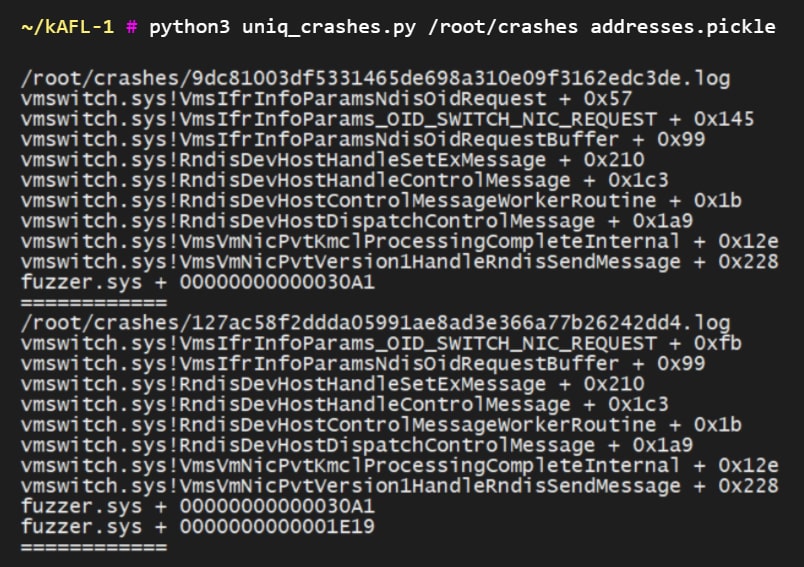 A detailed crash report from hAFL1, showing the stack trace, function names and offsets within them.
A detailed crash report from hAFL1, showing the stack trace, function names and offsets within them.
Structure awareness
For a faster fuzzing process, we wanted the fuzzer to generate inputs that match the format expected by the target. In our case, these inputs were RNDIS messages.
We defined RNDIS messages using Protocol Buffers and mutated them using libprotobuf-mutator. To integrate our custom, Protocol-Buffer-based mutation into kAFL, we had to create a new state and add it to kAFL’s state machine, which is basically a mutation pipeline. Any fuzzing payload goes through this pipeline to be mutated by kAFL’s built-in mutators. A more detailed explanation of this process is in our repository’s README.
The vulnerability
Within two hours from the moment hAFL1 started running – it found a critical, CVSS 9.9 RCE vulnerability. You can read more about it in our separate blog post.
 hAFL1 GUI. The interface is identical to that of kAFL, but can be extended by adding the new stage of Protocol-Buffer-based mutation.
hAFL1 GUI. The interface is identical to that of kAFL, but can be extended by adding the new stage of Protocol-Buffer-based mutation.
Finally - the fuzzer
You can find hAFL1 in our repository, with detailed instructions on its deployment and execution. Feel free to reach out to us if you have any questions, suggestions and comments.
