
Flagging 13 Million Malicious Domains in 1 Month with Newly Observed Domains


by Stijn Tilborghs and Gregorio Ferreira
Executive Summary
Akamai researchers have flagged almost 79 million domains as malicious in the first half of 2022, based on a newly observed domain dataset. This equals approximately 13 million malicious domains per month, and represents 20.1% of all the Newly Observed Domains (NODs) that successfully resolved.
We compared a NOD-based detection approach with another well-known threat intelligence aggregator in terms of coverage and mean time to detect and found excellent complementary value.
NOD-based threat detection enables us to look at the “long tail” of DNS queries and flag new malicious threats very early in a threat’s lifecycle.
Introduction
Akamai CacheServe instances currently handle more than 80 million DNS queries per second, or approximately 7 trillion requests per day, from all over the world. An anonymized subset of this data reaches our team, where our researchers work hard to make life safer online.
We are part of Akamai Security Research. We produce DNS and IP intelligence for ISPs and enterprises, so that end users like you and me are able to browse the web in a safe, protected way.
As you undoubtedly know, the destinations of web links are not always safe. If we identify a destination as malicious, our systems are able to intervene so that you don’t become a victim of ransomware, malware, phishing, and many other threats.
In this article, you will learn about one of our most powerful assets: the newly observed domain (NOD) dataset, and how we use it to flag new malicious domain names with a very short mean time to detect (MTTD).
We will introduce the concept of NODs, and show you how they enable our team to protect customers and end users. In a future post, we will outline more of the process behind this research from a machine learning angle.
Newly observed domains
Some of our CacheServe customers (typically ISPs) supply us with anonymized DNS query fields, such as the requested FQDN and resolved IP address. From this data we extract the domain names, and we keep track of when every domain name was last observed. Whenever a domain name is queried for the first time in the last 60 days, we consider it a NOD: a newly observed domain.
The NOD dataset lets us zoom in on what is often referred to as the “long tail,” — in this case, the long tail of DNS queries. This dataset is where you find freshly registered domain names, typos, and domains that are only very rarely queried on a global scale.
Other organizations that we know are monitoring NODs have stated that they use a time window from 30 minutes to 72 hours. This is far off from the 60-day window we are using. We use such a long window to ensure we are only looking at the freshest and most rarely queried domain names. This subset is where our researchers have found large amounts of new and upcoming DNS-based cyberthreats.
On top of this, we also keep track of DNS queries that never successfully resolved (NXDOMAIN). We do this because most domains to which malware tries to connect are not even registered. This leads to an increase of our dataset size of almost an order of magnitude, but it allows our security researchers to look at a complete picture instead of a biased sample.
This is, in a nutshell, what our NOD dataset is. And it provides us with a wealth of options for analysis.
Malicious activity in NOD data
To get an idea of what the NOD dataset actually looks like, Figure 1 shows a random sample from March 3, 2022.
aa65ef[.]ch
i3oq6565ybln1l14[.]com
1z4e1feu8flth[.]com
fkyjtgqnodzv0n0[.]com
xmyc[.]ren
bx76-lzlirxpp6[.]com
vcd7alw-x34ujurr7aeciih9l8[.]com
yporqueyo[.]com
avdl2-li2tmw86[.]com vnfwjetwwqqddnundjgk[.]jp lynnesilkmandesig[.]com aa73ve[.]ch
Fig. 1: A random sample of the NOD dataset
After seeing Figure 1, you will not be surprised that NODs have quite a high likelihood of being malicious.
On a typical day, our team observes a total of approximately 12 million new NODs, of which slightly more than 2 million successfully resolve. Over the first 6 months of 2022, almost 79 million domain names were flagged as malicious thanks to NOD-based threat detection. This makes the NOD dataset a key component of our detection mechanisms.
Many names in the NOD dataset look like names you’d never type into a browser window. They’re not readable by humans; they look computer generated. Why do we see so many of these?
Malicious actors often register thousands of domain names in bulk. This way, if one or more of their domains are flagged and blocked (e.g., by our team), they can simply switch to one of the other domains they own. Typically these domain names are created programmatically using a domain generation algorithm (DGA). This automated process is part of what makes these NODs dangerous. It is a persistent way of attacking an organization.
It is often the case that digits are inserted into the names, so that there is a low chance that the generated domains have already been registered.
Common threats using the above technique include malware, ransomware attacks, cryptominers, typosquatting (often used for phishing), botnets, and APTs. The better and faster we detect these kinds of patterns and computer-generated names, the more threats we can neutralize before they cause damage.
Malicious activity detection in NOD data
Here is a small selection of the NOD-based detection methods in our team.
Known DGA database
Let’s have a closer look at 2 domain names from the earlier examples: aa65ef[.]ch and aa73ve[.]ch. They both share the same length, top-level domain (TLD), and location of alphabetic and numeric characters, which suggest they were very likely created by the same DGA.
Once we know the inner workings of a DGA through reverse-engineering, it is easy to generate names that we expect to see in the future. This is exactly what one of our internal projects has done: We’ve created a database with predicted names for all known DGA families up to 30 years into the future. This was only made possible through public knowledge sharing in the cybersecurity community. Thank you, colleagues, for sharing your knowledge!
Any time we detect a new NOD, we look for a match against this database. If a match exists, we consider the NOD malicious. Approximately 0.1% of successfully resolved NODs are currently flagged as malicious through this method.
This means that the knowledge collected from the cybersecurity community is actively making an impact here and protecting end users. But it also means this method is detecting just a small fraction of the malicious activity, and we need more detection mechanisms in addition to this.
Heuristic analysis
Our researchers have been working with NOD data for many years. Through manual analysis and research in the last 12 years, we’ve created more than 190 NOD-specific detection rules.
These heuristic rules are currently responsible for the large majority of all the detections and are based on inputs such as the domain name itself, its TLD, resolved IP, autonomous system numbers (ASNs), and so on.
An example of such a rule could look like:
Flag all NODs with:
An ASN risk score over 0.50
A TLD risk score over 0.75
Resolved IP addresses in range 127.0.0.0/8
A registered domain name that starts with a digit
How do we know a rule doesn’t create false positive results? The team’s experience plays a big part here. Throughout the years, the rules have certainly caused a fair number of false positives. We have a reporting mechanism in place for our customers so any errors can be analyzed and dealt with quickly.
In the first half of 2022, of the 79 million flagged domains resulting from the heuristic analysis, we later found 329 false positives. This amounts to a false discovery rate of 0.00042%.
Our data scientist team is currently working on an ML-based approach to extend the heuristics and further increase coverage. We will write about this approach in a future blog post.
Phishing detection
For each new NOD that we see, we check the similarity with a list of known brand names and popular websites. If we see a new NOD with very high similarity, it may be enough reason to flag the NOD as malicious.
In cases of slightly less (but still high) similarity, we bring in other data to help make the decision. For example: If, after resolving, the domain name points to an ASN with a high risk score, the probability of it being a phishing attack increases.
Rapid threat detection
The big advantage of NOD-based threat detection is its very short MTTD.
NOD data allows us to classify a new domain very early in the threat lifecycle. All we need to trigger our detection mechanisms is a single DNS query to a newly created malicious domain.
Let’s look at an example:
We’re looking at a phishing attempt being set up in “evil hacker country.” The malicious actors are targeting safebank[.]abc and they set up a fake website at savebank[.]abc.
Emails are sent out to get people to visit the fake website. One of those emails reaches John, who lives in the United Kingdom and is a subscriber at an ISP using CacheServe. The ISP is also sharing CacheServe metadata with our Akamai team, and John has opted in to the ISP’s enhanced security package provided by Akamai, just like all the other ISP’s subscribers.
John clicks the link to the phishing website. As the website is completely new and it hasn’t been flagged as malicious by anyone, John will unfortunately be able to visit it.
However, behind the scenes, our team now receives a new entry in the NOD dataset for savebank[.]abc. Our phishing detection immediately identifies it as a spelling mistake of safebank[.]abc.
The domain is flagged as malicious. This is cascaded to the ISP. From this point forward, all the ISP’s subscribers are protected from this phishing scam. Even if they click on the phishing link, they will be unable to visit the fake website.
John may have been the first victim of the phishing website. But as far as people protected by our team are concerned, John is probably also the last one
All of our NOD-based detection systems and rules are fully automated. This means that once a new NOD is identified, the time needed for us to classify it as malicious is measured in minutes, not hours or days. No human intervention is needed.
All this gives our NOD-based threat detection an edge in speed over many other threat detection mechanisms. It allows our team to mitigate new DNS-based threats fast.
To sum things up:
The event that triggers the threat detection is positioned at a very early stage in the threat lifecycle.
The detection systems themselves are very fast because they’re fully automated.
How effective are we?
In order to be able to do a comparison, let’s zoom in on NODs that were successfully resolved, because we are unlikely to find unresolved domain names in external datasets. Therefore, any numbers mentioned below are only for rcode 0. We also limit ourselves to a timeline from January 1, 2022, through the end of June 2022.
In this time frame, our team’s detection systems flagged 20.1% of all NODs as malicious. This equals almost 79 million unique malicious domain names in this 6-month period, based on rcode 0 alone.
We decided to do an evaluation using a large and well-known aggregator of threat intelligence as a reference. We will refer to this reference as “the aggregator’.
On one end, we took all the NODs that were flagged as malicious by the heuristic analysis project we described earlier.
On the other end, we took all the domain names that had been searched at least once in the database mentioned above.
We found that 91.4% of the NODs that we flagged as malicious were not present.
We also found that from the names that we were able to find, more than 99.9% had a “reputation” of 0, which means these had not yet been tagged as either benign or malicious (they were just searched by someone).
Summing this up, for all the successfully resolved domain names that our researchers flagged through the heuristic rules, we were only able to get an opinion from the known aggregator for approximately 1 in every 11,000 domain names.
Did we do better or worse than them? This is a question we can’t answer here.
What we can conclude from the above numbers is that the NOD dataset provides a lot of complementary value, since there is only a very small overlap between its output and other major threat intelligence feeds.
How fast are we?
Let’s now analyze the time to detect.
We take the same data setup as above, and zoom in on the small overlap that we found, which represents cases where both the aggregator and our team flagged a domain name as malicious. Note that we are still looking here at just one of our detection projects; that is, the heuristic analysis.
Figure 2 addresses the question: When both systems flag a domain name as malicious, which of the two does it earliest and what is the time difference?
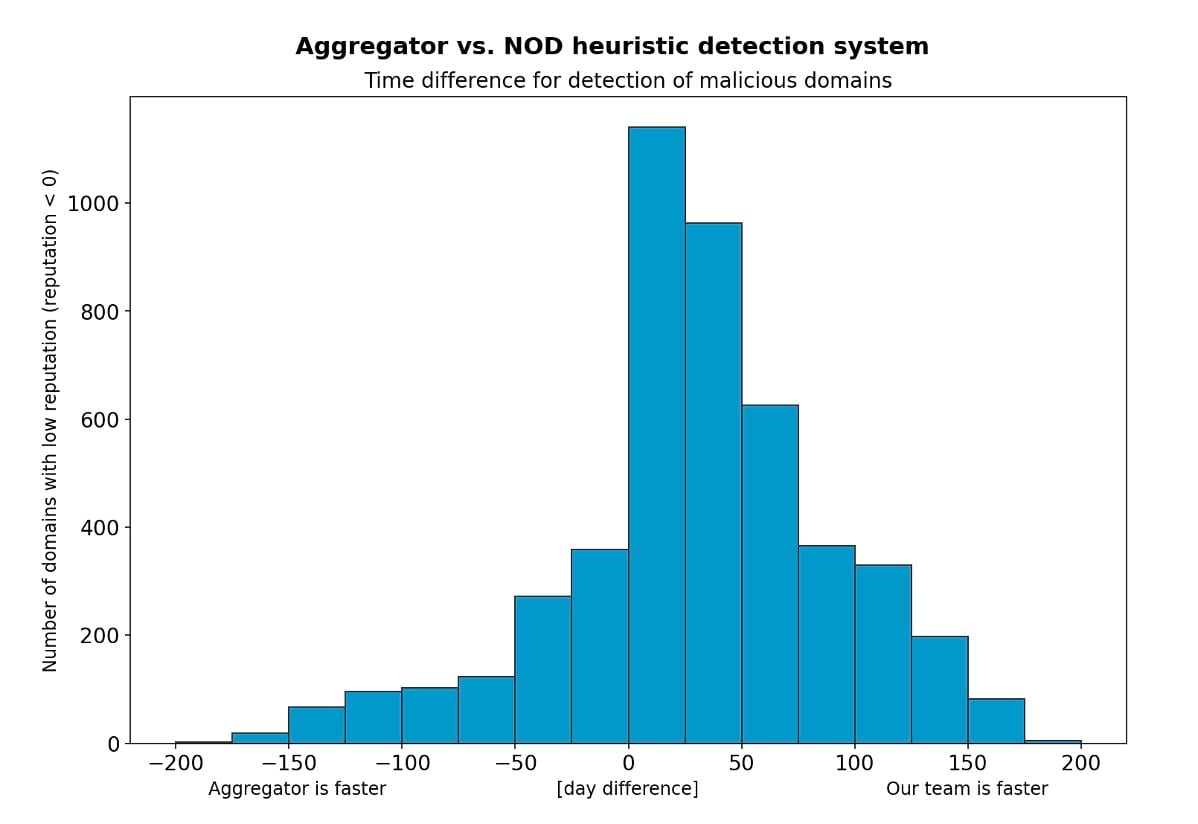
Fig. 2: The time difference for detection by the aggregator versus our NOD detection system
We found that in cases in which both the aggregator and our team flag a domain name as malicious, we typically do it 29.6 days earlier than the aggregator (i.e., an almost 30-day shorter MTTD).
Figure 2 breaks this number down further.
The y-axis represents the count of malicious domain names.
The x-axis represents the difference in the number of days between flagging a domain name as malicious and it being flagged by the other system. Bars on the right side represent cases where our detection system was faster. Bars on the left side represent cases where the aggregator was faster.
The NOD approach truly shows its excellent MTTD here, as a result of its detection triggers being positioned very early in a typical threat’s lifecycle.
However, it is also clear that there are numerous cases where the NOD approach is slower than the other aggregator. This demonstrates the need for a multifaceted approach so we get the best of both systems.
From our analysis of Figure 2, we conclude — again — that the best solution is using both the NOD approach and the aggregator at the same time.
A recent NOD observation
One more thing about NOD data is that analyzing it can provide us with a unique macro perspective on malicious activity. For example, Figure 3 shows the number of malicious domain names we flagged per TLDs over time.
The behavior of the .ru Russian TLD is particularly interesting. Its baseline is approximately 10,000 unique new malicious domains per day. Two weeks before Russia's invasion of Ukraine, we started to see steadily rising malicious activity up to nearly 40,000 malicious NODs per day. This activity then slowed down a little before resulting in a massive peak of more than 250,000 unique malicious .ru domain names per day in the second half of March.
Flagging these domains for our customers allowed them to keep their subscribers safe from these potential threats.

Fig. 3: The number of malicious domain names flagged per TLD over time
Conclusion
Security has to be multifaceted, and the more we know, the more secure we can make the world. NOD-based threat detection is fast and very complementary to other threat intelligence feeds.
Our team continues to monitor NODs and will continue to learn and share our knowledge with the security community in future posts.
In a future blog post, we will expand on how we are adding machine learning–based algorithms on the NOD dataset.
To ensure that you don’t miss any of the work from our security research team, our threat intelligence team, or any of our other impressive teams, be sure to follow us on Twitter for information on upcoming research.

