

Détection de code JavaScript malveillant avec la passerelle Web sécurisée Secure Internet Access Enterprise


Écrit par : Jordan Garzon
Introduction
Imaginez un monde sans JavaScript. Je ne peux pas compter le nombre de fois où mes collègues et moi y avons pensé à un moment donné de notre carrière, et même encore aujourd'hui. Un monde sans JavaScript est difficile à imaginer. En tant que collaborateur d'une entreprise qui utilise JavaScript depuis maintenant plusieurs années, j'ai bien conscience de ses défis, et de son omniprésence dans notre secteur. Ainsi, la protection de JavaScript fait partie intégrante de notre mission, que cela nous plaise ou non.
JavaScript est partout. Chaque demande envoyée à un site Web ou à une application pour mobile charge des dizaines de lignes de code JavaScript ; tous les navigateurs le supportent. Il est si omniprésent qu'il pourrait facilement être considéré comme une technologie essentielle, qui façonne la création et le mode de fonctionnement des sites Web. Cependant, comme nous le savons tous, en matière de sécurité, plus une technologie est essentielle, plus elle peut être utilisée de manière malveillante.
En raison de son omniprésence, le ciblage et l'utilisation de JavaScript permet aux cybercriminels de créer d'importants dégâts en tirant profit de l'énorme surface d'attaque de JavaScript. L'impact potentiel d'un vecteur important a été illustré par la vulnérabilité Log4j, découverte en décembre 2021, un vecteur d'attaque qui a immédiatement permis de lancer des attaques à grande échelle une fois exploité. Log4j, une bibliothèque Java, permet d'utiliser des services de journalisation, une fonctionnalité de base que la plupart des développeurs utilisent. C'est la différence entre les vulnérabilités de JavaScript et les autres vulnérabilités : leur présence massive au sein du code de production.
Avec tout cela à l'esprit, l'éternelle question se pose : « Que pouvons-nous y faire ? » Après avoir vu les ravages causés par Log4j, nous avons décidé d'essayer de répondre définitivement à la question et avons lancé une enquête pour comprendre et détecter le JavaScript malveillant. Cela a mené au projet dont je vous parle aujourd'hui. La recherche sur la sécurité est toujours intéressante, et quand nous avons vu notre théorie fonctionner, nous avons fait un pas de plus et avons mis à l'épreuve quelques situations contextuelles du monde réel.
Dans cet article de blog, je souhaite vous parler de notre enquête et des techniques que nous avons utilisées pour identifier et isoler le JavaScript malveillant afin d'intégrer une nouvelle fonctionnalité à notre produit. Nous analyserons l'écosystème des menaces liées au JavaScript, notamment l'architecture système, les algorithmes appliqués et une étude de cas.
Écosystème des menaces liées aux codes JavaScript malveillants
Avant d'entrer dans le vif du sujet, examinons l'écosystème qui fait du code JavaScript malveillant un vecteur de menace aussi dangereux. J'ai déjà mentionné son omniprésence, mais jusqu'où s'étend-elle ? Comprendre ce facteur permet de mettre le projet en contexte. Voici quelques-unes des attaques les plus répandues utilisant JavaScript.
Exploitation du navigateur
Je n'ai pas besoin de vous préciser l'ampleur de cette menace : les navigateurs et les extensions de navigateur sont indispensables pour quiconque possède un ordinateur. Le projet de framework d'exploitation de navigateur, également appelé BeEF,illustre parfaitement cet exemple. BeEF est un outil de test de pénétration centré sur les navigateurs Web (l'un des plus grands vecteurs d'attaque côté client) qui illustre assez bien leur exploitabilité.
Skimmers
Les skimmers illustrent la façon dont la cybersécurité peut affecter la vie en dehors du monde de l'entreprise et nous toucher personnellement. Comme JavaScript contrôle le modèle d'objet document, il peut modifier non seulement le code HTML généré, mais également les requêtes HTTP sous-jacentes. Cela peut se produire simplement lorsque l'utilisateur clique sur un bouton.
Les sites d'e-commerce sont particulièrement visés par ces attaques. Si un JavaScript malveillant est injecté sur un site Web inoffensif, toutes les informations d'identification de carte de crédit capturées par le skimmer peuvent être redirigées vers le cybercriminel. Citons notamment l'attaque de type Magecart sur le site Web de British Airways en 2018, qui a permis de voler environ 380 000 numéros de carte de crédit.
Le skimming s'est transformé depuis 2018. Aujourd'hui, cette technique est souvent utilisée pour remplacer des adresses bitcoin par l'adresse du cybercriminel sur un site Web inoffensif, comme nous l'avons vu avec le groupe Lazarus ces dernières années.
Clickjacking (ou détournement de clics)
Bien que l'exploitation de sites Web inoffensifs permette une vaste diffusion, leur portée est limitée par rapport à celle d'un serveur entièrement contrôlé par le cybercriminel. Si le pirate peut faire venir l'utilisateur à lui, il a l'avantage du terrain. Cela lui permet d'avoir un impact beaucoup plus important. Une fois que les victimes arrivent sur son territoire, le cybercriminel peut leur faire télécharger des programmes malveillants, récupérer des informations sur leur session de navigation et effectuer de nombreuses autres activités malveillantes.
Pour ce faire, il peut créer une iframe transparente sur une iframe légitime et ainsi donner aux utilisateurs un faux sentiment de sécurité quand ils cliquent dessus. Cette iframe redirige les utilisateurs vers le serveur contrôlé par le pirate, ce qui lui permet d'exécuter d'innombrables activités malveillantes.
Minage de cryptomonnaies non autorisé
Le minage de cryptomonnaies fait grand bruit ces derniers temps, avec la forte hausse de l'utilisation des cryptomonnaies. Pourquoi ne pas utiliser le processeur d'autres utilisateurs pour miner des cryptomonnaies ? Cela ne nécessite qu'une seule ligne de code JavaScript. La bibliothèque la plus célèbre pour cette technique, Coinhive, est censée avoir fermé en 2019, mais a bien sûr été remplacée depuis par CoinIMP ou CryptoLOOT.
Moteur de détection de code JavaScript malveillant : architecture et algorithmes
Maintenant que vous connaissez le contexte, parlons à présent de la solution que nous avons créée. Il existe deux façons d'injecter du code JavaScript dans un site Web : en écrivant un fichier JavaScript sur le même serveur, ou en utilisant un fichier existant provenant d'une autre source et en insérant le lien dans la page HTML. Côté proxy, nous allons voir deux requêtes HTTP différentes, l'une pour le fichier HTML et l'autre pour le fichier JavaScript. En entrant sur un seul site Web, votre navigateur peut exécuter des centaines de requêtes HTTP pour afficher l'ensemble du site Web.
Vous pouvez également écrire le code JavaScript dans le code HTML lui-même. Aucune requête supplémentaire n'est alors nécessaire pour le récupérer. La détection d'un JavaScript malveillant nécessite d'agir sur ces deux plans. C'est donc ce que nous avons donc créé.
Notre nouveau moteur est capable d'extraire les codes JavaScript « en ligne » et des lire séparément. Vous trouverez ci-dessous un extrait de la page source du New York Times affichant ces deux types de JavaScript :
 on February 2, 2022")
Extrait de code HTML du site Web du New York Times (https://www.nytimes.com/) le 2 février 2022
La passerelle Web sécurisée (SWG) d'Akamai Secure Internet Access Enterprise intègre différents moteurs qui analysent le trafic en temps réel. Elle est également reliée à nos informations sur les menaces et enrichie par nos algorithmes personnalisés.
 High-level overview of the Enterprise Threat Protector secure web gateway
High-level overview of the Enterprise Threat Protector secure web gateway
Concentrons-nous sur la zone rouge intitulée « Modèles JS » :
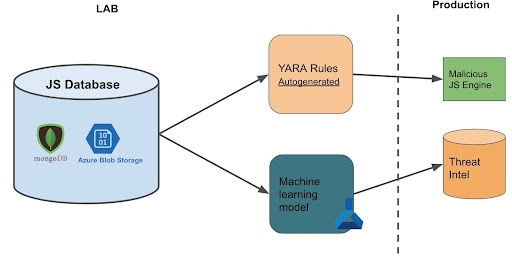
Base de données
Les modèles utilisent une base de données relationnelle pour conserver les métadonnées et stocker le code JavaScript réel par l'intermédiaire d'un fournisseur de stockage.
La base de données comprend un échantillon d'entraînement (nos données étiquetées). Les données inoffensives proviennent principalement des JavaScript populaires observés dans notre trafic. Les données malveillantes sont renseignées à l'aide de diverses sources : VirusTotal (VT), les détections d'autres algorithmes et le code malveillant que nous détectons réellement. Ainsi, elles sont constamment mises à jour.
La base de données contient également l'échantillon de test, qui représente essentiellement les derniers jours de trafic que nous observons sur le proxy.
Modèle de détection en temps réel
Pour pouvoir détecter le JavaScript malveillant en temps réel, nous utilisons des règles YARA que nous déployons en bordure de l'Internet. Ces règles sont créées en fonction de l'échantillon d'entraînement. Comme la création de règles n'est pas une mince affaire, nous avons basé un algorithme sur cet article qui génère automatiquement des règles Yara. Nous l'avons adapté pour classer le code JavaScript au lieu du code binaire, et avons modifié la logique de génération de règles afin de mettre à jour le moteur de codes JavaScript malveillants fonctionnant sur SWG à la demande.
 Example of a YARA rule generated with AutoYara
Example of a YARA rule generated with AutoYara
Enrichissement des informations sur les menaces via des techniques d'apprentissage automatique
Un problème connu rencontré par les chercheurs lorsqu'ils détectent du JavaScript est la dissimulation, une technique (également utilisée par les sites Web inoffensifs) qui compacte le code et le rend illisible. Or Katz a écrit un article de blog à ce sujet en octobre 2020.
Pour pouvoir le détecter, nous avons intégré notre logique à un modèle inspiré par JStap, qui s'exécute sur l'arborescence syntaxique abstraite, une représentation arborescente du code qui nous permet de contourner cette technique.
Un modèle d'apprentissage automatique garantit une meilleure précision que les règles YARA. Toutefois, le déploiement de cette solution en bordure de l'Internet pour analyser les menaces en temps réel est difficile. Nous avons donc opté pour une solution hybride. Notre modèle utilise le même échantillon d'entraînement, analyse le trafic hors ligne (dans l'environnement Azure Machine Learning) et renseigne les informations sur les menaces détectées.
Les informations sur les menaces sont vérifiées à chaque connexion à la SWG, ce qui permet aux clients de bénéficier de la détection du modèle d'apprentissage automatique.
Le modèle à l'épreuve : étude de cas
Le meilleur moyen de prouver l'efficacité de cette technique est d'utiliser un exemple réel. Le 8 mars 2022, le modèle d'apprentissage automatique a détecté un code JavaScript hébergé sur cigarettesblog[.]blogspot[.]com.
Ce domaine, au 10 mars 2022, montrait 0 détection sur VT.
![Page d'accueil de cigarettesblog[.]blogspot[.]com vue le 9 mars](/site/fr/images/blog/2022/detecting-malicious-javascript-with-swg5.jpeg) Home page of cigarettesblog[.]blogspot[.]com seen on March 9
Home page of cigarettesblog[.]blogspot[.]com seen on March 9
Dans l'extrait suivant, le code JavaScript remplace tous les liens HTML par des URL malveillantes.
L'un d'entre eux, hxxps://myprintscreen[.]com/soft/myp0912.exe (aujourd'hui indiqué dans les commentaires du code), télécharge en fait un cheval de Troie (4a6ffa02ff7280e00cf722c4f2235f0e318e6cc8a2b9968639ba715f1a38c834), qui a 23 détections sur VT. D'autres URL ont été signalées comme malveillantes par de nombreux fournisseurs sur VT.
Il s'agit d'un comportement classique du code JavaScript malveillant : remplacement d'URL sur les pages, envoi de requêtes POST à d'autres domaines (voir l'extrait ci-dessous), ou exécution d'une attaque par téléchargement pour déposer des programmes malveillants sur la machine de l'utilisateur.
![Code JavaScript extrait de la base de données cigarettesblog[.]blogspot[.]com le 9 mars 2022.](/site/fr/images/blog/2022/detecting-malicious-javascript-with-swg6.png) JavaScript code extracted from cigarettesblog[.]blogspot[.]com on March 9, 2022
JavaScript code extracted from cigarettesblog[.]blogspot[.]com on March 9, 2022
URL :
myprintscreen[.]com/soft/myp0912.exe
www[.]blog-hits.com
Hachage de fichiers :
4a6ffa02ff7280e00cf722c4f2235f0e318e6cc8a2b9968639ba715f1a38c834 (cheval de Troie)
fc311d002d7139e0a58b00464731ba8d4faea4670cff9fedfb35057fe838c285 (fichier JavaScript mis en ligne par nos soins le 10 mars)
Le même mécanisme a été détecté sur penis-photo.blogspot[.]com.br (le 10 mars) ainsi que sur mateyhderesa[.]blogspot.com (le 13 mars), playboy-college-girls.blogspot.sk (14 mars)
Résumé
Comme indiqué au début de cet article, tout ce qui est essentiel pour la sécurité peut également être utilisé de manière malveillante, et quelque chose d'aussi répandu que JavaScript peut avoir des répercussions majeures. De plus, il n'est pas toujours évident de le déchiffrer. Un précédent article de blog a montré que 25 % du code malveillant que nous détectons est brouillé. Ce n'est pas un pourcentage insignifiant, et compte tenu du nombre de pages d'Internet que nous examinons, cela donne une idée de l'ampleur du phénomène.
Cette étude visait à l'origine à améliorer la sécurité de nos clients. Nous avons donc appliqué les enseignements tirés à notre SWG. Nous avons deux nouveaux modèles : l'un reposant sur YARA et l'autre reposant sur l'apprentissage automatique. Le modèle basé sur les règles YARA analyse tout code JavaScript passant par la SWG pour une protection en temps réel. Le modèle basé sur l'apprentissage automatique vérifie deux fois le trafic pour mettre à jour les renseignements sur les menaces en bordure de l'Internet. Les deux modèles sont constamment mis à jour et reformés, et tiennent compte des dernières menaces ainsi que du nouveau code JavaScript inoffensif observé.
