
AkaNAT: How Akamai Uses Machine Learning to Detect Shared IPs


Executive summary
Shared IPs are IP addresses that serve multiple users or devices, like proxies or corporate network address translations (NATs).
These types of IPs pose a significant challenge to cybersecurity defenses and often demand precise tailored treatment.
Detecting and flagging shared IPs in a timely manner is a crucial capability of many security applications.
Akamai uses a novel machine learning (ML)–based detection algorithm to detect and classify shared IPs.
This algorithm allows Akamai App & API Protector to accurately differentiate between shared and nonshared IPs, enabling our customers to make more granular decisions.
Introduction
A shared IP address is an IP address that multiple devices or users use. This practice is common in large organizations, where a single IP address is shared by a group of employees. Despite their advantages in saving money and in simplifying workflows, shared IPs pose significant challenges in cybersecurity as they make it difficult to track the source of malicious activity.
Threat actors often use shared IPs to conduct cyberattacks such as phishing, malware distribution, and denial-of-service (DoS) attacks. Detecting these attacks can be challenging since they appear to be coming from a legitimate source, which makes it difficult to block them without blocking legitimate traffic.
An organization’s ability to quickly detect shared IPs is critical to prevent cyberattacks and protect its applications. An ML-based algorithm for detecting shared IPs can help to quickly identify malicious activity and prevent it from spreading.
Correctly classifying shared IPs can help organizations to improve their cybersecurity posture by defining more granular security policies that address shared IPs differently from nonshared ones (Figure 1). For example, with accurate shared IP detection, organizations can reduce their false positives by permitting nonlethal traffic if it comes from a shared IP, which would be blocked otherwise. Another option would be raising the threshold for some rule if it’s triggered by a shared IP’s traffic.
 Fig. 1: Shared and nonshared IPs interacting on the internet
Fig. 1: Shared and nonshared IPs interacting on the internet
In this blog post, we introduce AkaNAT, a new ML-based algorithm for detecting shared IPs. We will outline how we labeled the data for such an algorithm, describe the training process, and share details on how AkaNAT is coping with shared IPs at Akamai’s scale.
Labeled data
Labeled data is a critical component in the field of ML. Simply put, labeled data is data that has been manually labeled or annotated with specific information, typically with the help of human experts or annotators. This labeled data is then used to train ML models to make accurate predictions and identify patterns in new, unseen data.
The need for labeled data in ML is fundamental because it helps create a reference point for the model. With labeled data, the ML model can learn from examples and understand how to identify specific patterns or features that are associated with a particular task. Without labeled data, it is difficult for the model to distinguish between different types of inputs and provide accurate outputs.
For our task at hand — detecting shared IPs — labeled data is particularly important. We need to train the ML model to recognize patterns and features that are specific to shared IPs, and this can only be done with the help of high-quality labeled data.
By providing the model with a large dataset of labeled examples of shared and nonshared IPs, we can ensure that it is trained to recognize the unique characteristics of shared IPs and can accurately identify them in new, unseen data.
How we labeled the data
To label our data, we used a combination of manual and automated techniques to compile a list of IPs and their labels (i.e., shared/nonshared), like the one in Table 1. To obtain positive samples — IPs that we know (with high confidence) are shared — we used several sources. The first one was the misses by our current shared IP detection algorithm, as reported to us by our customers in the support channels. (Yes, we give value to the saying “You should learn from your mistakes.”)
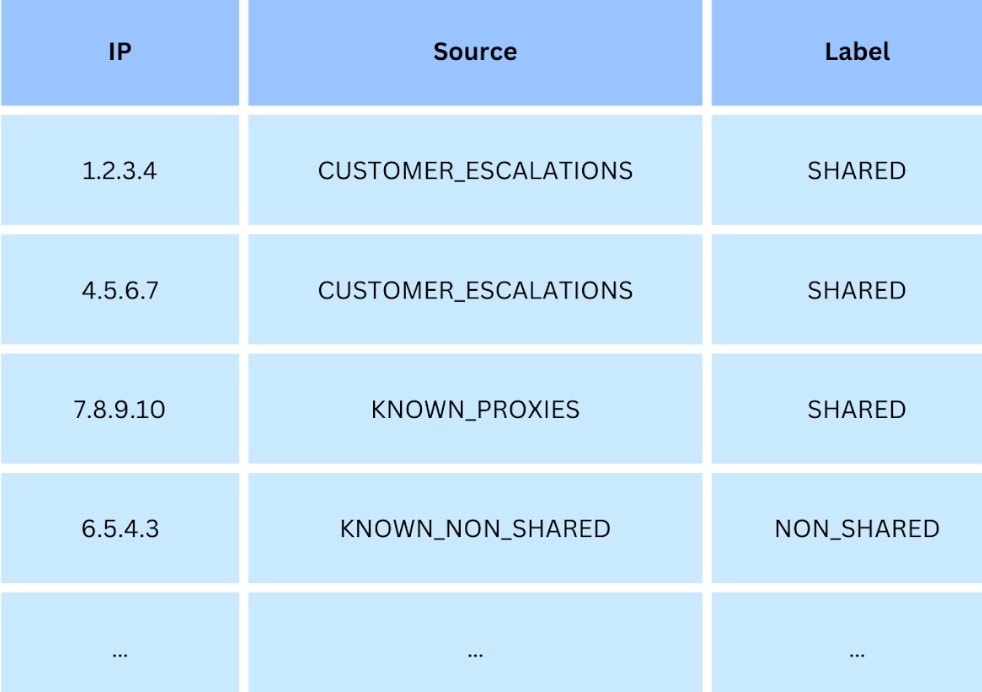 Table 1: Labeled IP lists collected in several techniques
Table 1: Labeled IP lists collected in several techniques
We systematically scanned our internal ticketing system and looked for any tickets related to false negatives from the current algorithm. We paid special attention to these IPs. With this approach, we can make sure our new algorithm, reinforced with valuable data, succeeds where the previous algorithm has failed.
The second source of positive samples was publicly known shared IP pools. One such example is Starlink. Starlink is a satellite internet constellation operated by SpaceX, that provides satellite internet access coverage to 34 countries. These IPs are an obvious example of shared IPs.
For negative samples (i.e., nonshared IPs), we systematically sampled the data from the Akamai content delivery network (CDN), and recorded IPs that met certain conditions that clearly indicate that they are not shared across multiple users. To lower the chances that the sampled IPs are shared, we subtracted from these IPs all IPs detected by our current shared IP algorithms.
These two methods, along with other techniques, allowed us to obtain a large dataset with which to train our ML model.
Feature engineering
The next step toward building an ML model capable of detecting shared IPs is to enrich our list of IPs and labels with the actual data. This step is often referred to as “feature engineering” in ML terminology. To achieve this, we will leverage Akamai’s unprecedented amounts of data and generate a unique “fingerprint” for each IP.
This fingerprint will be in the form of aggregated features, that will describe the IP patterns and behavior, as seen in the Akamai network. Some of the aggregated features we are using are shown in Table 2.
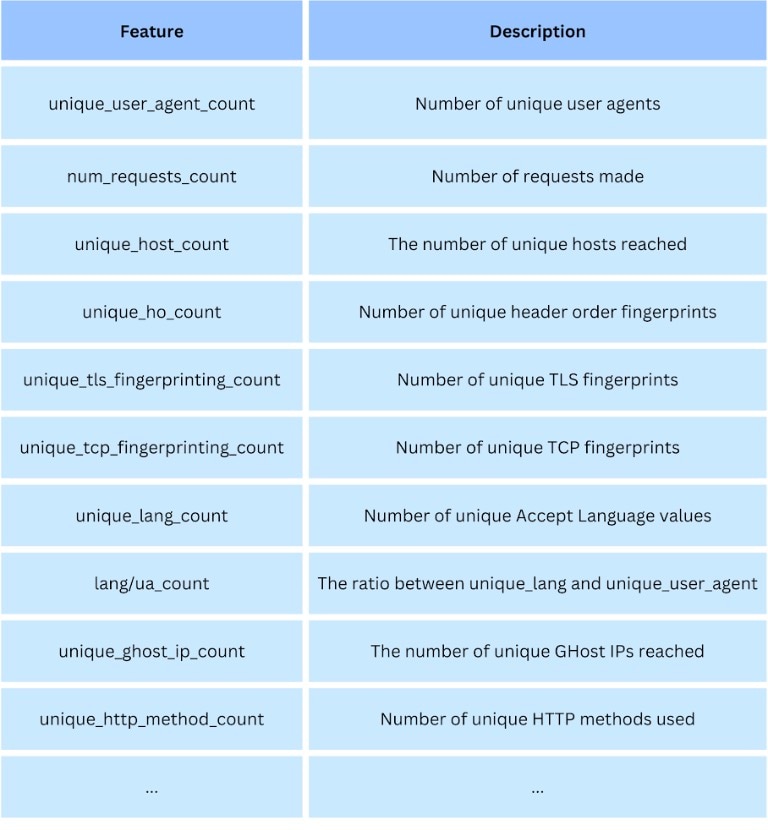 Table 2: A sample of aggregated features
Table 2: A sample of aggregated features
The features Table 2 are calculated for each IP and a 12-hour window. That is, to generate a fingerprint, we divide the IP’s traffic into 12-hour buckets in a sliding window. Then, for each bucket, we apply the required calculations to generate the features.
These features were chosen to be part of our IP fingerprint because we think they are solid indicators of the “sharedness” of an IP. Most of them are just numeric counters of several fields of the HTTP requests. Generally speaking, the higher the numerical value of the features, the more likely the IP is shared. Figure 2 depicts this process at a high level.
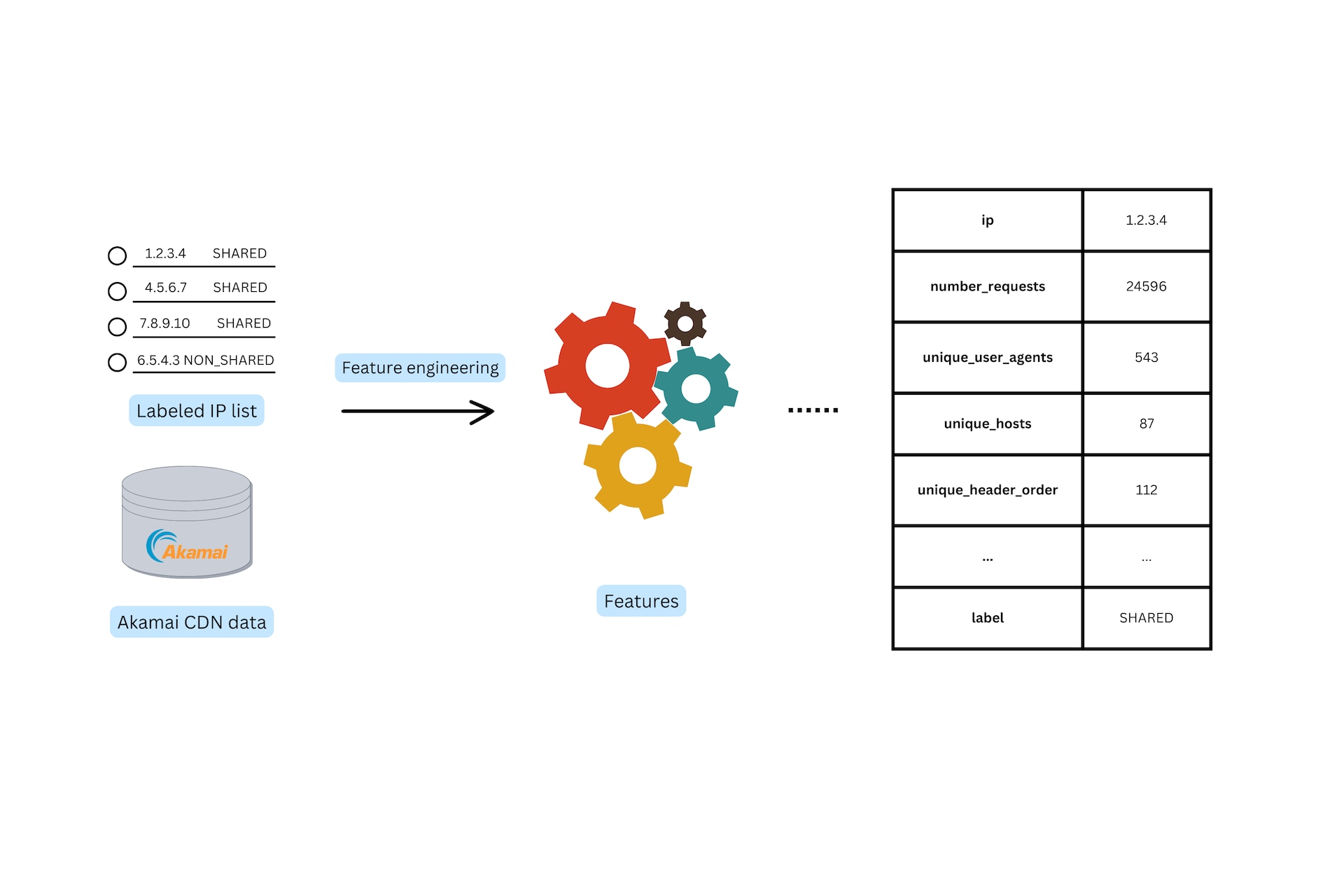 Fig. 2: Feature engineering in AkaNAT using Akamai’s CDN data
Fig. 2: Feature engineering in AkaNAT using Akamai’s CDN data
Cleaning the data
So far, we have collected the initial data and generated the features. It’s important to note, though, that collecting data with the methods we described can produce erroneous data. Therefore, we will need to clean the data from outliers. (An outlier is a sample that lies at an abnormal distance from the other samples.) For this task, we will be using the interquartile range (IQR) technique.
In this technique, we remove any data point that falls outside the range defined by the first quartile minus 1.5 times the IQR and the third quartile plus 1.5 times the IQR. With the assumption that most of the data is accurate, and only a few IPs are labeled incorrectly, we can use the IQR technique to clean the data. After the feature engineering phase, the outlier removal process is done when we have aggregated data per IP. Then, data examples (IPs aggregated traffic data in a defined time window) that are detected as outliers are removed from the dataset.
Training a classifier
Determining the “sharedness” of an IP is a binary classification problem. So, to train our ML, we used the XGBoost algorithm. XGBoost is a popular and powerful open source gradient-boosting framework that has been widely used in various ML tasks, including classification.
We chose XGBoost for several reasons, including:
It is known for its high accuracy and efficiency, making it an ideal choice for large-scale datasets
It is highly customizable, allowing us to fine-tune the model to our specific needs
It is easy to integrate into our existing workflow, thanks to its support for various programming languages and platforms
To train the XGBoost classifier, we used the labeled data that we collected previously. Specifically, we split the data into training and validation sets, with an 80:20 ratio. We then used the training set to train the classifier, using a gradient boosting algorithm, and we used the validation set to tune the hyperparameters and evaluate the model's performance (Figure 3).
 Fig. 3: Using XGBoost with our labeled data to train a classifier
Fig. 3: Using XGBoost with our labeled data to train a classifier
During the training process, the XGBoost classifier learns the patterns of shared or nonshared IPs based on the features and labels we feed to it. The output of the training process is a trained model that can be used to classify new IP addresses as shared or nonshared.
To ensure the reliability and robustness of our model, we used various techniques, such as cross-validation, early stopping, and regularization.
Cross-validation helps prevent overfitting by splitting the data into multiple folds and training the model on different combinations of the folds
Early stopping ceases the training process if the validation performance does not improve after a certain number of iterations, preventing the model from overfitting to the training data
- Regularization helps prevent overfitting by adding penalties to the model's weights
Robust and accurate results
Although having a trained ML classifier can provide decent results in the short term, it might not perform very well in real-life scenarios. For example, imagine a situation in which an IP is detected and flagged as shared on Friday. Then, the weekend comes, and the IP generates much less traffic than on weekdays.
At this point, the latest run of the model might classify it as nonshared — and this decision might change again on Monday. These erratic changes might cause confusion and inconsistent security configuration for our customers, which in turn can cause more harm than good.
It is important to note that there are additional factors that must be taken into account to ensure reliable and robust results in real-life settings. To address those issues, AkaNAT uses two key concepts: "time to detect” and "time to forget." These two are configurable parameters of the algorithm, and are used by what we call the “long-term classifier,” while the ML model is the “short-term classifier.”
Time to detect
Time to detect refers to the minimum number of positive (i.e., shared) classifications required before an IP address can be classified as a shared IP. In other words, if an IP address is flagged as potentially being shared, our algorithm will only classify it as such once it has been observed behaving in a manner consistent with a shared IP a certain number of times.
This threshold can be adjusted depending on the level of risk tolerance we would like to use. By requiring a certain number of observations before classifying an IP as shared, we are able to reduce the likelihood of false positives, increase the overall accuracy, and reduce the “fuzziness” of our model’s classifications.
Time to forget
Similarly, time to forget refers to the length of time that must elapse without an IP address exhibiting behavior consistent with a shared IP before our algorithm will "forget" that it was ever classified as such. This is an important component of our algorithm because it ensures that our classification results remain up-to-date. Without this feature, our algorithm would be more likely to classify IPs as shared even if they are no longer exhibiting shared-like behavior.
Together, these two concepts — time to detect and time to forget — form an integral part of our long-term classifier, which is designed to process classification results in a way that will scale to our customer's data (Figure 4). By taking into account the number of positive classifications required and the length of time needed to forget previous classifications, we are able to provide robust and accurate shared IP detection results that are well-suited to real-life scenarios.
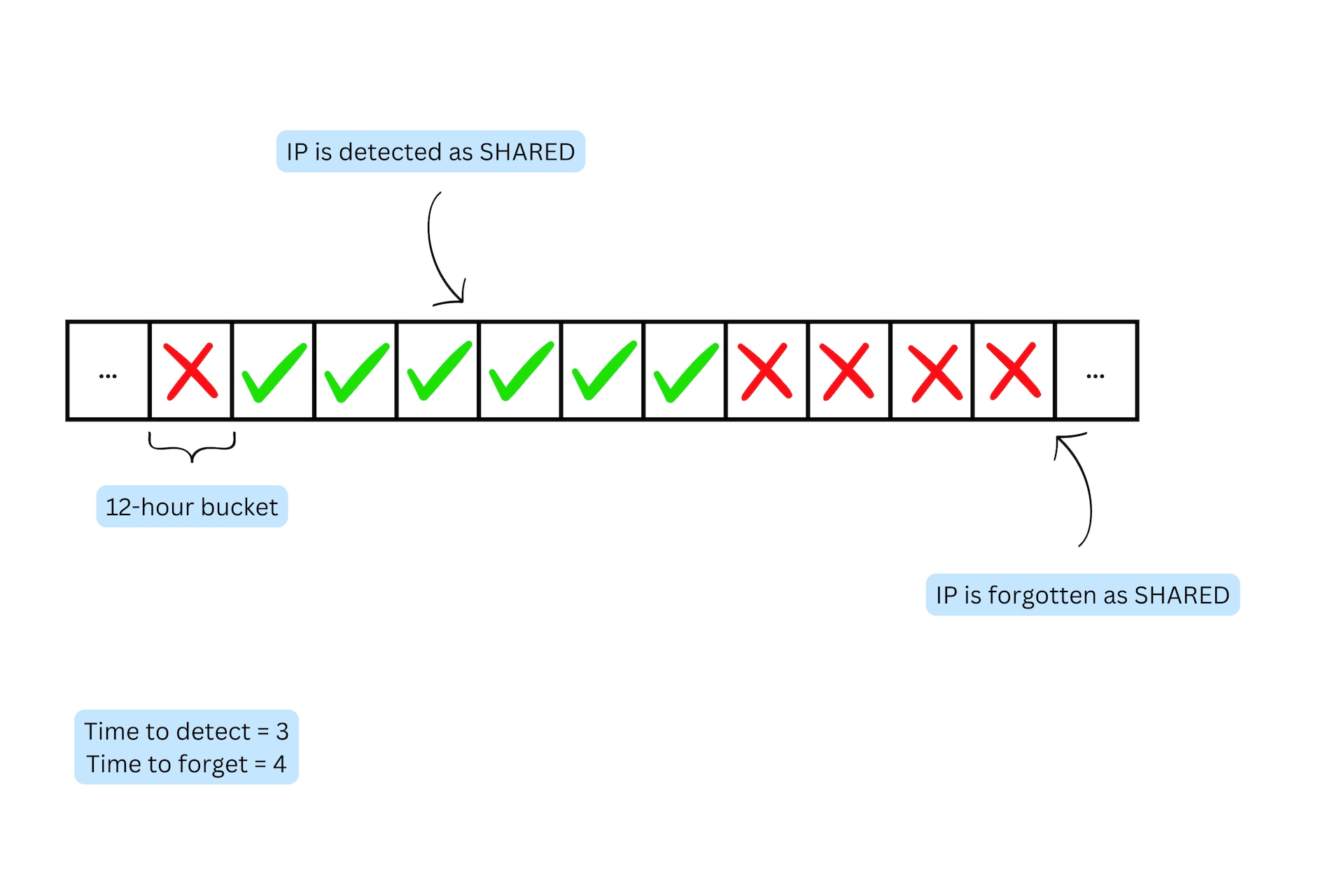 Fig. 4: Use of time to detect and time to forget to create a long-term classifier
Fig. 4: Use of time to detect and time to forget to create a long-term classifier
Real-life success stories
In the short time that our model has been running in production, it has already provided us with a handful of real-life success stories. For example, one of our Akamai App & API Protector customers was planning to launch a new pool of IP addresses for the secure web gateway service it offers to its clients.
Those addresses are shared by definition, and they provided a great opportunity for AkaNAT to showcase fast and accurate shared IP detection. Indeed, AkaNAT was able to correctly detect the addresses as shared in as fast as 14 hours, which is an 8x improvement in detection time (Figure 5).
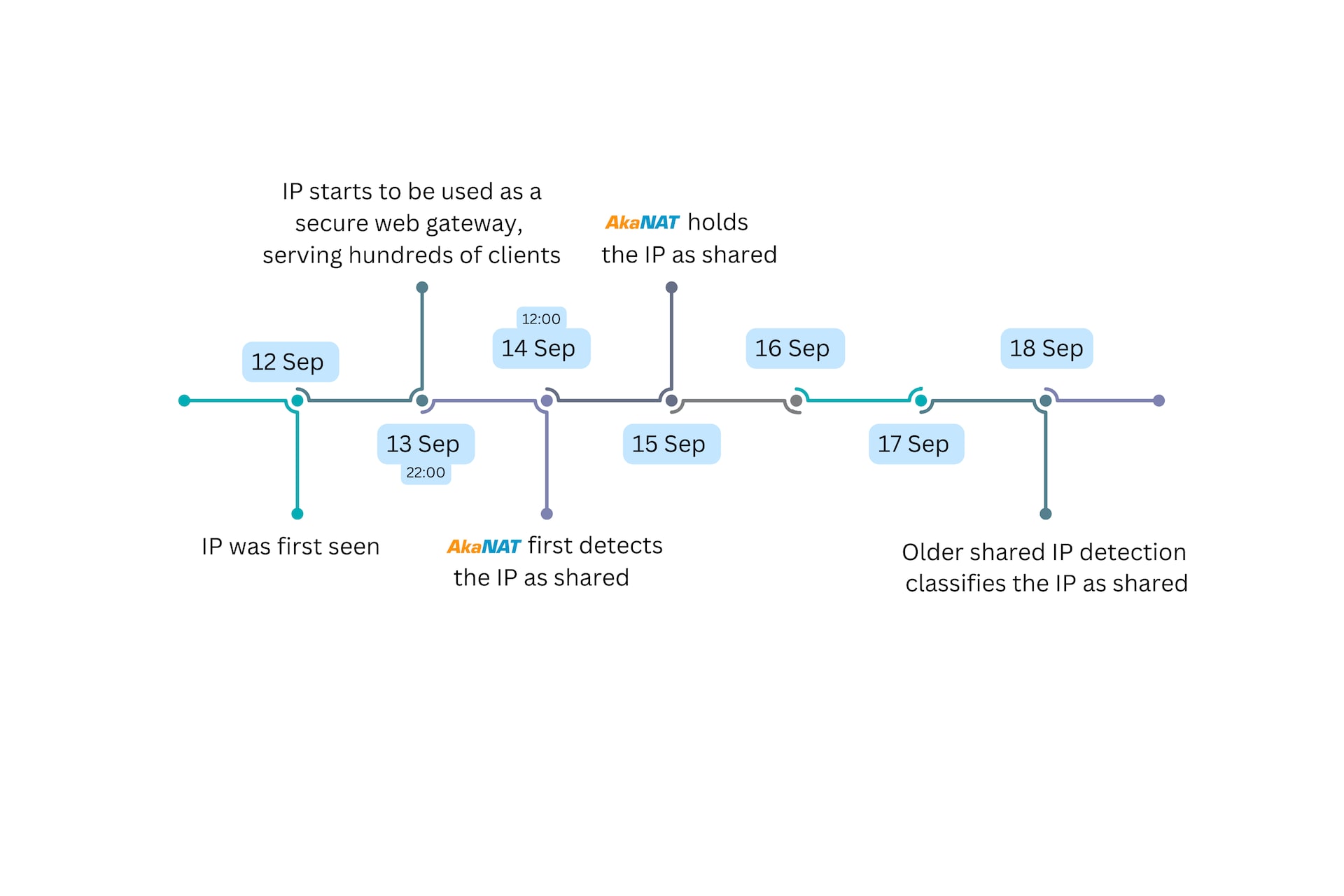 Fig. 5: AkaNAT detects shared IPs quicker than older methods
Fig. 5: AkaNAT detects shared IPs quicker than older methods
In another case, our research team detected a shared IP false positive, which was made by our legacy algorithm. This false positive caused a regular end-user IP address to be falsely detected as shared. When running AkaNAT on this IP’s traffic, it was correctly classified as nonshared. This case proves another ability of AkaNAT: to avoid false positives.
Summary
In this blog post, we introduced AkaNAT, an ML-based algorithm for detecting shared IPs, which is used by Akamai App & API Protector. Shared IPs pose a significant challenge to cybersecurity defenses as they make it difficult to track the source of malicious activity. By detecting shared IPs, organizations can improve their cybersecurity posture, reduce the risk of data breaches, and prevent financial loss.
To train our algorithm, we collected a large dataset of labeled examples of shared IPs, using a combination of manual and automated techniques. We used the XGBoost algorithm, which is known for its high accuracy and efficiency, to train the model. To ensure the reliability and robustness of the model, we wrapped it with guardrails, like time to detect and time to forget, that will help the algorithm cope with real-life settings.
Our algorithm allows Akamai App & API Protector to treat shared IPs differently than nonshared IPs, enabling our customers to create more granular security policies. Overall, this capability increases our customers’ visibility of the IPs that are interacting with their applications. Backed up by high-quality data from Akamai’s network and equipped with important mechanisms, our shared IP detection algorithm demonstrates the power of ML to address well-known cybersecurity challenges.